第66节 Kubernetes 二次开发 CRD 学习
❤️💕💕新时代拥抱云原生,云原生具有环境统一、按需付费、即开即用、稳定性强特点。Myblog:http://nsddd.top
[TOC]
前言
sealos 使用了大量的 CRD 对其扩展,我们可以使用 CRD 来 Kubernetes
除此之外,这里有一份官方 CRD 案例 ~
CRD是Kubernetes为提高可扩展性,让开发者去自定义资源(如Deployment,StatefulSet等)的一种方法。
Operator=CRD+Controller
CRD仅仅是资源的定义,而Controller可以去监听CRD的CRUD事件来添加自定义业务逻辑。
如果说只是对CRD实例进行 CRUD 的话,不需要 Controller 也是可以实现的,只是只有数据,没有针对数据的操作。
就拿官方的 CRD 案例(sample-controller)来说,如果没有运行这个程序,也可以使用 examples 案例中的 yaml 文件,创建 CRD,以及 CR。只不过没有办法针对 Pod 和 deployment 等 内置的 API 资源对象进行 CRUD 操作。
❯ k get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 9h
❯ ./ctrl -kubeconfig ~/.kube/config -logtostderr=true
❯ k get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
example-foo 1/1 1 1 4s
nginx-deployment 3/3 3 3 9h
项目 demo
review:@muzi502
author: @cubxxw
这篇文章将参考各个博客和 kubebuilder 官方文档 以及 kubernetes/sample-controller 进行学习,最后实践一个项目的步骤,对静态博客(docker.nsddd.top 或者 go.nsddd.top) 进行 CRD,形成学习闭环~
- 创建自定义API对象(Custom Resource Definition),名为Blog;
- 用代码生成工具生成informer和client相关代码;
- 创建并运行自定义控制器,k8s环境中所有 Blog 相关的"增、删、改"操作都会被此控制器监听到,可以根据实际需求在控制器中编写业务代码;
Operator 功能设计
借助 Operator 完成和企业内部注册中心的打通
Operator 开发 SDK 有 2 个选择:
- kubebuilder
- operator sdk
注意:在本质上其实都是在 K8s 控制器运行时上的封装,主要都是脚手架的生成,使用体验相差不大。
但是有意思的是,Kubebuilder 的维护方是:kubernetes-sigs,所以更受人关注。
底层都是基于 k8s 控制器运行时封装,不同的是 kubebuilder 早期包含 CRD和 自定义 Controller 开发。但是 operator-sdk 早期不包含 CRD 开发,但是现在也是融合了。
CRD 允许你定义自己的 Kubernetes API 对象,而自定义控制器可以监听这些对象的事件并执行相应的操作。
kubebuilder 架构图
图片来自官网站:
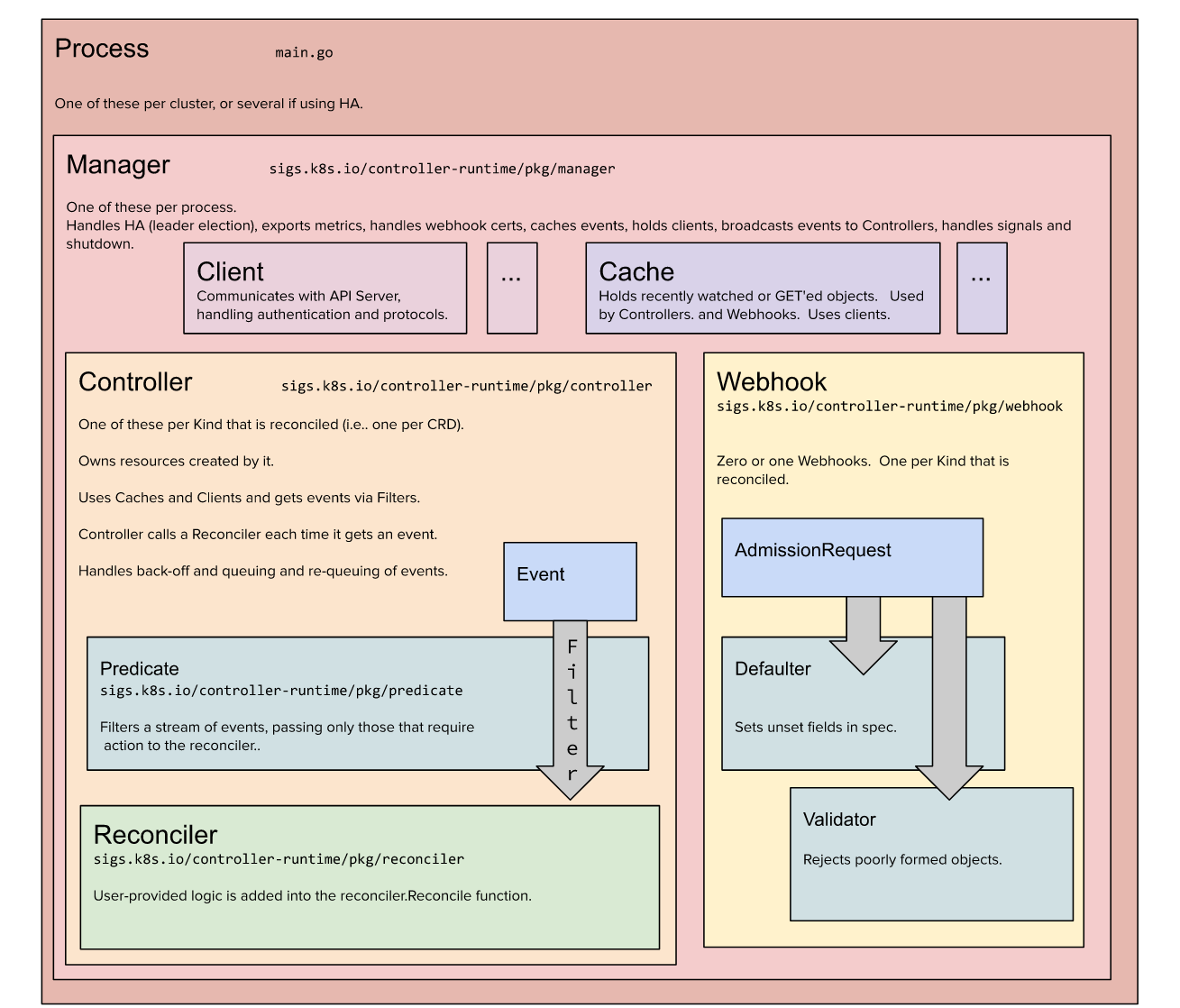
installation kubebuilder
安装kubebuilder:
❯ curl -L -o kubebuilder https://go.kubebuilder.io/dl/latest/$(go env GOOS)/$(go env GOARCH)
❯ chmod +x kubebuilder && mv kubebuilder /usr/local/bin/
或者,使用 make build , 这是我很喜欢的一种方式,方便贡献和阅读源码:
❯ export KUBEBUILDER=$(pwd)/kubebuilder
❯ git clone https://github.com/kubernetes-sigs/kubebuilder.git $KUBEBUILDER && cd $KUBEBUILDER; make build && cd bin; ./kubebuilder;
❯ export PATH=$PATH:$KUBEBUILDER/bin; kubebuilder
create a project
很简单的行为,我们只需要创建一个目录,并且使用 命令 初始化就够了,在底层上 kubebuilder 并不希望我们知道实现的细节~
❯ mkdir /tmp/guestbook -p; cd /tmp/guestbook
❯ kubebuilder init --domain my.domain --repo my.domain/guestbook
这个目录就是很神奇了,就像代码生成器一样生成了一个模板:
❯ tree -L 3
.
├── Dockerfile
├── Makefile
├── PROJECT
├── README.md
├── cmd
│ └── main.go
├── config
│ ├── default
│ │ ├── kustomization.yaml
│ │ ├── manager_auth_proxy_patch.yaml
│ │ └── manager_config_patch.yaml
│ ├── manager
│ │ ├── kustomization.yaml
│ │ └── manager.yaml
│ ├── prometheus
│ │ ├── kustomization.yaml
│ │ └── monitor.yaml
│ └── rbac
│ ├── auth_proxy_client_clusterrole.yaml
│ ├── auth_proxy_role.yaml
│ ├── auth_proxy_role_binding.yaml
│ ├── auth_proxy_service.yaml
│ ├── kustomization.yaml
│ ├── leader_election_role.yaml
│ ├── leader_election_role_binding.yaml
│ ├── role_binding.yaml
│ └── service_account.yaml
├── go.mod
├── go.sum
└── hack
└── boilerplate.go.txt
在这里我借助《Kubernetes operator 开发进阶》这本书(但不推荐)部分解释:
Dockerfile: 用于构建 Docker 镜像的文件。Makefile: 一个 Makefile,其中包含了用于构建和发布 Operator 的常用命令。PROJECT: 项目名称,以及项目信息,这里是一些 metadata 。README.md: 项目的说明文档。cmd/: 包含了 Operator 的入口程序main.go。config/: 包含了 Operator 的配置文件,包括 RBAC 权限相关的 YAML 文件、Prometheus 监控服务发现(ServiceMonitor)相关的 Yaml 文件、控制器(Manager)部分部署的 Yaml 文件。default/: 包含了默认的配置文件。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。manager_auth_proxy_patch.yaml: 在 manager 容器中添加了 auth-proxy 容器的相关信息。manager_config_patch.yaml: 在 manager 容器中添加了与 Operator 相关的配置信息。
manager/: 包含了部署 Operator 所需的 k8s 资源文件。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。manager.yaml: 部署 Operator 所需的 k8s 资源文件。
prometheus/: 包含了 Prometheus 监控 Operator 所需的 k8s 资源文件。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。monitor.yaml: 部署 Prometheus 监控 Operator 所需的 k8s 资源文件。
rbac/: 包含了 Operator 所需的 RBAC 资源文件。auth_proxy_client_clusterrole.yaml: 配置了与客户端授权相关的 ClusterRole。auth_proxy_role.yaml: 配置了与 auth-proxy 相关的 Role。auth_proxy_role_binding.yaml: 配置了与 auth-proxy 相关的 RoleBinding。auth_proxy_service.yaml: 配置了与 auth-proxy 相关的 Service。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。leader_election_role.yaml: 配置了与 leader election 相关的 Role。leader_election_role_binding.yaml: 配置了与 leader election 相关的 RoleBinding。role_binding.yaml: 配置了与 Operator 相关的 RoleBinding。service_account.yaml: 配置了与 Operator 相关的 ServiceAccount。
go.mod: Go 项目的模块文件。go.sum: Go 项目的模块依赖文件。hack/: 包含了生成代码和文档等相关的脚本和文件。boilerplate.go.txt: 用于生成 Go 项目文件的代码模板。
为了方便我们后面的学习,我这里用 git 进行版本控制,方便观察后面生成了哪些文件
❯ git add .
❯ git commit -a -s -m "kubebuilder init"
create an API
运行以下命令,创建一个新的API(组/版本)为 webapp/v1 ,并在其上创建新的Kind(CRD) Guestbook :
❯ kubebuilder create api --group webapp --version v1 --kind Guestbook
Create Resource [y/n]
y
Create Controller [y/n]
y
📜 对上面的解释:
如果你按下
y创建资源[y/n]和创建控制器[y/n],则这将创建文件api/v1/guestbook_types.go(其中定义了API)和controllers/guestbook_controller.go(其中实现了此类(CRD)的协调业务逻辑)。
这个时候 kubebuilder 又偷偷的做了什么?我们看一下 git 的变动:
❯ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: PROJECT
modified: cmd/main.go
modified: go.mod
modified: go.sum
Untracked files:
(use "git add <file>..." to include in what will be committed)
api/
config/crd/
config/rbac/guestbook_editor_role.yaml
config/rbac/guestbook_viewer_role.yaml
config/samples/
internal/
no changes added to commit (use "git add" and/or "git commit -a")
新增目录:
api:包含刚刚添加的 API,后面会经常编辑这里的guestbook_types.go文件。这个文件是 CRD 代码的主要定义文件。config/crd:存放的是 crd 部署相关的 kustomize 文件。config/rbac/:分别是编辑权限和查询权限的ClusterRolesamples:很好理解,CR 示例文件internal:很好理解,内部核心代码,我们打开看看controllers
❯ cat internal/controller/guestbook_controller.go
package controller
//...
// GuestbookReconciler reconciles a Guestbook object
type GuestbookReconciler struct {
client.Client
Scheme *runtime.Scheme
}
//...
func (r *GuestbookReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
_ = log.FromContext(ctx)
// TODO(user): your logic here
return ctrl.Result{}, nil
}
// SetupWithManager sets up the controller with the Manager.
func (r *GuestbookReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&webappv1.Guestbook{}).
Complete(r)
}
很明显,上面的 Reconcile 函数是一个调谐函数,这是贯穿始终的一个词语,在 显眼的提示 TODO 中,我们可以补充自己的逻辑。
我们具体观察一下 PROJECT 文件,具体的元数据变化:
❯ git diff PROJECT
diff --git a/PROJECT b/PROJECT
index a18434c..3ea38eb 100644
--- a/PROJECT
+++ b/PROJECT
@@ -7,4 +7,14 @@ layout:
- go.kubebuilder.io/v4
projectName: guestbook
repo: my.domain/guestbook
+resources:
+- api:
+ crdVersion: v1
+ namespaced: true
+ controller: true
+ domain: my.domain
+ group: webapp
+ kind: Guestbook
+ path: my.domain/guestbook/api/v1
+ version: v1
version: "3"
如果要编辑API定义,请使用以下命令生成清单,如自定义资源(CR)或自定义资源定义(CRD)
CRD 和 CR 区别
自定义资源(CR)是 Kubernetes 中扩展 API 资源的一种方式,它允许用户自定义 Kubernetes 中的资源类型,并为其创建自己的 API 端点。用户可以使用 kubectl 命令行工具或 Kubernetes API 以编程方式操作 CR。CR 可以用于任何一种 Kubernetes 资源的扩展,例如 Pod、Service 或 Deployment。
自定义资源定义(CRD)用于定义自定义资源(CR)。它定义了 CR 的结构,即它的 API 规范。CRD 用于定义 Kubernetes 中的新 API 资源类型。这些资源类型可以用于扩展 Kubernetes,使其支持更多的资源类型和操作。CRD 本身是一个 Kubernetes 资源,它可以被 kubectl 或 Kubernetes API 用于创建新的 CR 类型。
因此,CR 是用户创建的 Kubernetes 资源类型,而 CRD 是定义和管理这些资源类型的方式。
API 定义
Kubernetes 的资源本质就是一个 API 对象,不过这个对象的 期望状态 被 API Service 保存在了 ETCD 中(或者是对于 k3s 来说可以保存在其他的有状态数据库,包括 sqlite、dqlite、mysql…),然后提供 RESTful 接口用于 更新这些对象。
我们在上面讲过,CRD 的代码定义主要在 api/ 目录下面,我们看一下代码结构:
❯ tree api
api
└── v1
├── groupversion_info.go
├── guestbook_types.go
└── zz_generated.deepcopy.go
guestbook_types.go 文件主要的定义,我们看下 spec 结构。
Spec 结尾的结构体含义
在Go语言中,结构体以 spec 结尾表示该结构体是用于特定目的的规范结构体。这种命名约定通常用于描述一个结构体的用途和功能,以便开发人员更好地理解和使用它。例如,GuestbookSpec定义了所需的 Guestbook 状态
// GuestbookSpec defines the desired state of Guestbook
type GuestbookSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Foo is an example field of Guestbook. Edit guestbook_types.go to remove/update
Foo string `json:"foo,omitempty"`
}
上面的注释写的很清楚,Foo 是一个示例,我们可以删除掉,然后添加自己需要的配置。
修改这个文件后利用 Makefile 重新生成代码,💡简单的一个案例如下:
import (
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
type GuestbookSpec struct {
Replicas int32 `json:"replicas,omitempty"`
Template corev1.PodTemplateSpec `json:"template,omitempty"`
}
我们分别定义了 用于声明 Pod 副本的数量、和用于生成 Pod 模板的配置。
最后我们也要记录到 git commit 中:
❯ git add .
❯ git commit -a -s -m "create api"
CRD 部署
接下来我们就可以使用 make manifests 命令生成 ClusterRole 和 CustomResourceDefinition 配置。
检查 git 的更改信息:
如果要编辑API定义,请使用以下命令生成清单,如自定义资源(CR)或自定义资源定义(CRD)
❯ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
config/crd/bases/
config/rbac/role.yaml
我们可以看到两个目录文件的变化:
config/crd/bases/目录:新增webapp.my.domain_guestbooks.yaml文件,这也是guestbook类型的 CRD 配置文件。config/rbac/role.yaml定义的是一个 ClusterRole,从名字 manager-role 上大致也可以猜出这是后面 Controller 部署后将充当的 “角色”,定义了对guestbook资源的 CURD 操作。
接下来,我们需要一个 Kubernetes 的环境,不管是 Kind & minikube & k3s 作为测试环境也好,我选择了 Kind:
❯ kind version
kind v0.18.0-alpha+bc0526729cf900 go1.20.1 linux/amd64
⚠️ 控制器将自动使用 kubeconfig文件(即集群kubectl cluster-info显示的任何内容)。如果出现问题按照官方的方法可以自己拷贝 kubeconfig 或者是 设置 环境变量。
我们可以用 make install 完成 CRD 的部署过程:
❯ make install
🎯 我们应该检查一个 Makefile 中的 install target,或许可以看出来 install target 是包含 make manifests 命令的,不过我们还是分开操作有助于了解整个过程。
# install Install CRDs into the K8s cluster specified in ~/.kube/config.
.PHONY: install
install: manifests kustomize ## Install CRDs into the K8s cluster specified in ~/.kube/config.
$(KUSTOMIZE) build config/crd | kubectl apply -f -
# kustomize Download kustomize locally if necessary. If wrong version is installed, it will be removed before downloading.
.PHONY: kustomize
kustomize: $(KUSTOMIZE) ## Download kustomize locally if necessary. If wrong version is installed, it will be removed before downloading.
$(KUSTOMIZE): $(LOCALBIN)
@if test -x $(LOCALBIN)/kustomize && ! $(LOCALBIN)/kustomize version | grep -q $(KUSTOMIZE_VERSION); then \
echo "$(LOCALBIN)/kustomize version is not expected $(KUSTOMIZE_VERSION). Removing it before installing."; \
rm -rf $(LOCALBIN)/kustomize; \
fi
test -s $(LOCALBIN)/kustomize || { curl -Ss $(KUSTOMIZE_INSTALL_SCRIPT) --output install_kustomize.sh && bash install_kustomize.sh $(subst v,,$(KUSTOMIZE_VERSION)) $(LOCALBIN); rm install_kustomize.sh; }
校验:
❯ k get crd -A
NAME CREATED AT
crontabs.stable.example.com 2023-04-07T09:17:55Z
guestbooks.webapp.my.domain 2023-04-07T15:42:22Z
guestbooks.webapp.my.domain 已经存在了,这是一个自定义资源,意味着我们可以通过 k get pod 的方式来 k get guestbooks
❯ k get guestbooks.webapp.my.domain -A
No resources found
这里并没出出现 error ,说明提示的是 kube-apiserver 已经可以识别这个资源,只不过没有这个资源的具体实例。
运行你的控制器(这将在前台运行,所以切换到一个新的 终端(如果你想让它保持运行):
make run
安装自定义资源的实例
如果你按了y创建资源 [y/n],则你在示例中为CRD创建了CR(如果你更改了 API定义):
kubectl apply -f config/samples/
在集群上运行
构建镜像并将其推送到IMG指定的位置:
make docker-build docker-push IMG=<some-registry>/<project-name>:tag
使用IMG指定的镜像将控制器部署到集群:
make deploy IMG=<some-registry>/<project-name>:tag
卸载CRD
要从群集中删除CRD,请执行以下操作:
make uninstall
取消部署 controller
将控制器取消部署到群集:
make undeploy
CR 部署
我们使用 CRD 定义了一个资源,CR 就像写一个 Deployment 一样,创建 guestbooks 同样需要一个 yaml 文件,并且符合声明式。
❯ cat config/samples/webapp_v1_guestbook.yaml
apiVersion: webapp.my.domain/v1
kind: Guestbook
metadata:
labels:
app.kubernetes.io/name: guestbook
app.kubernetes.io/instance: guestbook-sample
app.kubernetes.io/part-of: guestbook
app.kubernetes.io/managed-by: kustomize
app.kubernetes.io/created-by: guestbook
name: guestbook-sample
spec:
# TODO(user): Add fields here
replicas: 3
template:
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
❯ k apply -f webapp_v1_guestbook.yaml
guestbook.webapp.my.domain/guestbook-sample created
❯ k get guestbooks.webapp.my.domain
NAME AGE
guestbook-sample 93s
上面表示创建出来了 guestbook-sample 对象,不过这个时候还不够,因为 Pod 还没有被创建出来,我们继续实现相应的控制器逻辑。
guestbook 生成的代码和结构
我们详细解释一下 kubebuilder 初始化CRD以及相关的控制器框架后,部分的代码结构和源码解析。首先,我们应该从主函数开始: main.go
cmd
main.go 作为入口函数,是我们主要看的。当然,许可证信息省略掉了~ 我们先看一下头文件:
package main
import (
"flag"
"os"
// Import all Kubernetes client auth plugins (e.g. Azure, GCP, OIDC, etc.)
// to ensure that exec-entrypoint and run can make use of them.
_ "k8s.io/client-go/plugin/pkg/client/auth"
"k8s.io/apimachinery/pkg/runtime"
utilruntime "k8s.io/apimachinery/pkg/util/runtime"
clientgoscheme "k8s.io/client-go/kubernetes/scheme"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/healthz"
"sigs.k8s.io/controller-runtime/pkg/log/zap"
webappv1 "my.domain/guestbook/api/v1"
"my.domain/guestbook/internal/controller"
//+kubebuilder:scaffold:imports
)
每一组控制器都需要一个Scheme,它提供了Kinds和它们对应的Go类型之间的映射。在编写API定义时,我们将更多地讨论Kinds,所以稍后请记住这一点。
var (
scheme = runtime.NewScheme()
setupLog = ctrl.Log.WithName("setup")
)
func init() {
utilruntime.Must(clientgoscheme.AddToScheme(scheme))
utilruntime.Must(webappv1.AddToScheme(scheme))
//+kubebuilder:scaffold:scheme
}
runtime.Scheme 是 Kubernetes 中对象的编解码器注册表,用于将对象序列化为字节数组,并将字节数组反序列化为对象。所有 Kubernetes API 对象都必须注册到 runtime.Scheme 中,以便在存储到 etcd 或发送到 API Server 时进行正确的编解码。
可以通过调用 scheme.AddKnownTypes() 方法向 runtime.Scheme 中注册新的 API 对象类型。
我们实例化了两个管理器,它跟踪所有控制器的运行情况,并为API服务器设置共享缓存和客户机。
⚠️ 注意:这里有 //+kubebuilder:scaffold:scheme ,这是一个比较有意思的事情。
剩下就是最核心的 main() 函数:
func main() {
var metricsAddr string
var enableLeaderElection bool
var probeAddr string
flag.StringVar(&metricsAddr, "metrics-bind-address", ":8080", "The address the metric endpoint binds to.")
flag.StringVar(&probeAddr, "health-probe-bind-address", ":8081", "The address the probe endpoint binds to.")
flag.BoolVar(&enableLeaderElection, "leader-elect", false,
"Enable leader election for controller manager. "+
"Enabling this will ensure there is only one active controller manager.")
opts := zap.Options{
Development: true,
}
opts.BindFlags(flag.CommandLine)
flag.Parse()
ctrl.SetLogger(zap.New(zap.UseFlagOptions(&opts)))
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
HealthProbeBindAddress: probeAddr,
LeaderElection: enableLeaderElection,
LeaderElectionID: "80807133.tutorial.kubebuilder.io",
})
if err != nil {
setupLog.Error(err, "unable to start manager")
os.Exit(1)
}
前面无非就是定义了一个 flag 并且初始化。并且交给Parse解析os.Args[1:]中的命令行标志。
请注意, Manager 可以通过以下方式限制所有控制器将监视资源的命名空间:
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
Namespace: namespace,
MetricsBindAddress: metricsAddr,
Port: 9443,
HealthProbeBindAddress: probeAddr,
LeaderElection: enableLeaderElection,
LeaderElectionID: "80807133.tutorial.kubebuilder.io",
})
上面的示例将项目的范围更改为单个 Namespace 。在这种情况下,我们还建议将默认的 ClusterRole 和 ClusterRoleBinding 分别替换为 Role 和 RoleBinding ,从而将提供的授权限制在此命名空间。这样来说权限小一些,在 RBAC 中介绍过这部分。
不仅如此,我们还可以使用 MultiNamespacedCacheBuilder 来监视特性的命名空间子集。
var namespaces []string // List of Namespaces
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
NewCache: cache.MultiNamespacedCacheBuilder(namespaces),
MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort),
Port: 9443,
HealthProbeBindAddress: probeAddr,
LeaderElection: enableLeaderElection,
LeaderElectionID: "80807133.tutorial.kubebuilder.io",
})
接下来的部分,就是一些错误处理,和开始搭建我们的API了!
// +kubebuilder:scaffold:builder
if err := mgr.AddHealthzCheck("healthz", healthz.Ping); err != nil {
setupLog.Error(err, "unable to set up health check")
os.Exit(1)
}
if err := mgr.AddReadyzCheck("readyz", healthz.Ping); err != nil {
setupLog.Error(err, "unable to set up ready check")
os.Exit(1)
}
setupLog.Info("starting manager")
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
setupLog.Error(err, "problem running manager")
os.Exit(1)
}
groups, versions, kinds, and resources
当我们谈论Kubernetes中的API时,我们经常使用4个术语:组、版本、种类和资源。
没错,我们在 https://docker.nsddd.top/Cloud-Native-k8s/ 中介绍过很多关于 GVK 和 GVR 的介绍,为什么在 Kubebuilder 中尤其需要再提一次。
当我们在一个特定的组版本中引用一个种类时,我们将其称为GroupVersionKind,或简称为GVK。资源和GVR也是如此。我们很快就会看到,每个GVK对应于包中给定的 root Go type。走进源码,体会这种感觉~
create an API
我们在前面创建过 API ,kubebuilder create api --group webapp --version v1 --kind Guestbook 命令创建了一个 组为 webapp,版本为 v1,类型为 Guestbook 的API 资源对象。
我们使用的命令是 create api,此命令的目标是为我们的同类创建自定义资源(CR)和自定义资源定义(CRD)。我翻开了 Kubebuilder 的源码部分:
在 pkg/cli 目录下面,我们找到了入口:
// addSubcommands returns a root command with a subcommand tree reflecting the
// current project's state.
func (c *CLI) addSubcommands() {
// add the alpha command if it has any subcommands enabled
c.addAlphaCmd()
// kubebuilder completion
// Only add completion if requested
if c.completionCommand {
c.cmd.AddCommand(c.newCompletionCmd())
}
// kubebuilder create
createCmd := c.newCreateCmd()
// kubebuilder create api
createCmd.AddCommand(c.newCreateAPICmd())
createCmd.AddCommand(c.newCreateWebhookCmd())
if createCmd.HasSubCommands() {
c.cmd.AddCommand(createCmd)
}
// kubebuilder edit
c.cmd.AddCommand(c.newEditCmd())
// kubebuilder init
c.cmd.AddCommand(c.newInitCmd())
// kubebuilder version
// Only add version if a version string was provided
if c.version != "" {
c.cmd.AddCommand(c.newVersionCmd())
}
}
📜 对上面的解释:
通过
newCreateCmd创建了一个create命令,并且通过newCreateAPICmd和newCreateWebhookCmd绑定了api和webhook.
webhook 是一个钩子,hook 在 Kubernetes 中随处可见,可以使用 Webhook 来验证 CRD 对象的规范是否正确,并设置默认值,以确保 CRD 对象的正确性。
为什么要创建 API?
新的API是我们向Kubernetes教授自定义对象的方式。Go结构体用于生成一个CRD,其中包括数据的模式以及跟踪数据,例如我们的新类型被称为什么。
然后,我们可以创建我们的自定义对象的实例,这些对象将由我们的控制器管理。
我们的API和资源代表我们在集群上的解决方案。基本上,CRD是我们定制对象的定义,而CR是它的实例。就比如说上面 我们 通过 kubebuilder 定义了一个 guestbooks.webapp.my.domain 的 CRD,然后再通过 声明式 yaml 文件编写 CR,并且创建 CR。
当然官方有一个更好理解的例子:目标是让应用程序及其数据库在Kubernetes平台上运行。然后,一个CRD可以表示App,而另一个CRD可以表示DB。
通过使用一个CRD描述应用程序,另一个CRD描述数据库,我们不会损害封装、单一责任原则和内聚等概念。
破坏这些概念可能会导致意想不到的副作用,例如难以扩展、重用或维护等。
Single Group to Multi-Group
在Kubebuilder v2 scaffolding的初始版本中(从Kubebuilder v2.0.0开始)不存在多组scaffolding支持。
要更改项目的布局以支持多组,请运行命令 kubebuilder edit --multigroup=true 。一旦切换到多组布局,新的Kinds将在新布局中生成,但需要额外的手动工作将旧的API组移动到新布局。
然后我们就可以添加一个 新的 API
add new api
❯ kubebuilder create api --group batch --version v1 --kind CronJob
按下 y 键,选择“创建资源”和“创建控制器”。
第一次为每个组版本调用此命令时,它将为新的组版本创建一个目录。
在本例中,创建了与 batch.tutorial.kubebuilder.io/v1 对应的 api/v1/ 目录(还记得我们一开始的 --domain --domain设置吗?)。
它还为我们的 CronJob Kind添加了一个文件, api/v1/cronjob_types.go 。每次我们调用不同类型的命令时,它都会添加一个相应的新文件。
我们的出发点很简单:我们导入 meta/v1 API组,它通常不会自己暴露,而是包含所有Kubernetes Kind通用的元数据。
package v1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
接下来,我们为Spec和Status of our Kind定义类型。Kubernetes的功能是将期望的状态( Spec )与实际的集群状态(其他对象的 Status )和外部状态进行协调,然后记录它所观察到的( Status )。因此,每个函数对象都包括spec和status。一些类型,比如 ConfigMap ,不遵循这种模式,因为它们不编码所需的状态,但大多数类型都是这样。
// CronJobSpec defines the desired state of CronJob
type CronJobSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
// CronJobStatus defines the observed state of CronJob
type CronJobStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
接下来,我们定义对应于实际Kind的类型, CronJob 和 CronJobList 。 CronJob 是我们的根类型,它描述了 CronJob 类型。像所有Kubernetes对象一样,它包含 TypeMeta (描述API版本和Kind),还包含 ObjectMeta ,它包含名称,命名空间和标签等内容。
CronJobList 只是多个 CronJob 的容器。它是在批量操作中使用的类型,如LIST。
一般来说,我们从不修改这两个属性中的任何一个--所有修改都在Spec或Status中。
这个小小的 +kubebuilder:object:root 注释被称为标记。我们将在稍后看到更多,但要知道它们作为额外的元数据,告诉控制器工具(我们的代码和YAML生成器)额外的信息。这个特定的类型告诉 object 生成器这个类型代表一个Kind。然后, object 生成器为我们生成 runtime.Object 接口的实现,这是所有表示Kinds的类型都必须实现的标准接口。
//+kubebuilder:object:root=true
//+kubebuilder:subresource:status
// CronJob is the Schema for the cronjobs API
type CronJob struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec CronJobSpec `json:"spec,omitempty"`
Status CronJobStatus `json:"status,omitempty"`
}
//+kubebuilder:object:root=true
// CronJobList contains a list of CronJob
type CronJobList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []CronJob `json:"items"`
}
最后,我们将Go类型添加到API组。这允许我们将此API组中的类型添加到任何 Scheme 中。
func init() {
SchemeBuilder.Register(&CronJob{}, &CronJobList{})
}
controller
一句话描述:Controllers are the core of Kubernetes, and of any operator
控制器的工作是确保,对于任何给定的对象,世界的实际状态(包括集群状态,以及潜在的外部状态,如Kubelet的运行容器或云提供商的负载均衡器)与对象中所需的状态相匹配。
每个控制器专注于一个 root Kind,但可以与其他Kind交互。
我们称这个过程为和解( reconciling)。
在controller-runtime中,实现特定类型协调的逻辑称为Reconciler。reconciler获取对象的名称,并返回是否需要重试(例如,如果出现错误或周期性控制器,如HorizontalPodAutoscaler)。
首先,我们从一些标准的导入开始。和前面一样,我们需要核心控制器运行时库,以及客户端包和API类型的包。
package controllers
import (
"context"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
batchv1 "tutorial.kubebuilder.io/project/api/v1"
)
接下来,kubebuilder为我们搭建了一个基本的reconciler结构。几乎每个协调器都需要日志,并且需要能够获取对象,因此这些都是开箱即用的。
// CronJobReconciler reconciles a CronJob object
type CronJobReconciler struct {
client.Client
Scheme *runtime.Scheme
}
大多数控制器最终都在集群上运行,因此它们需要RBAC权限,我们使用controller-tools RBAC标记来指定这些权限。这些是运行所需的最低权限。当我们添加更多功能时,我们将需要重新访问这些。
// +kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs/status,verbs=get;update;patch
使用以下命令通过controller-gen从上述标记生成 config/rbac/role.yaml 处的 ClusterRole 清单:
make manifests
实现 Controller
我们通过实现 Controller 逻辑去创建 Pod,在 internal/controller/guestbook_controller.go
我们的CronJob控制器的基本逻辑是这样的:
- 加载命名的 CronJob
- 列出所有活动 jobs 并更新状态
- 根据历史限制清理 history limits
- 检查我们是否被暂停(如果是,不要做任何其他事情)
- 获取下一次计划运行
- 运行一个新的 job,如果它是按计划进行的,没有超过截止日期,也没有被我们的并发策略阻塞
- 当我们看到一个正在运行的 job(自动完成)或者到了下一个计划运行的时间时,重新排队。
我们先从进口开始。下面你会看到,我们需要比那些脚手架更多的进口。我们将在使用时讨论每一个。
package controllers
import (
"context"
"fmt"
"sort"
"time"
"github.com/robfig/cron"
kbatch "k8s.io/api/batch/v1"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
ref "k8s.io/client-go/tools/reference"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
batchv1 "tutorial.kubebuilder.io/project/api/v1"
)
接下来,我们需要一个时钟,这将允许我们在测试中伪造时间。
// CronJobReconciler reconciles a CronJob object
type CronJobReconciler struct {
client.Client
Scheme *runtime.Scheme
Clock
}
// Clock
我们将模拟时钟,以便在测试时更容易在时间上跳跃,“真实的” 时钟只是调用 time.Now 。
type realClock struct{}
func (_ realClock) Now() time.Time { return time.Now() }
// clock knows how to get the current time.
// It can be used to fake out timing for testing.
type Clock interface {
Now() time.Time
}
请注意,我们还需要一些RBAC权限--因为我们现在正在创建和管理作业,所以需要这些权限,这意味着要添加一些标记。
//+kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs/status,verbs=get;update;patch
//+kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs/finalizers,verbs=update
//+kubebuilder:rbac:groups=batch,resources=jobs,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=batch,resources=jobs/status,verbs=get
现在,我们进入控制器的核心--协调器逻辑。
var (
scheduledTimeAnnotation = "batch.tutorial.kubebuilder.io/scheduled-at"
)
// Reconcile is part of the main kubernetes reconciliation loop which aims to
// move the current state of the cluster closer to the desired state.
// TODO(user): Modify the Reconcile function to compare the state specified by
// the CronJob object against the actual cluster state, and then
// perform operations to make the cluster state reflect the state specified by
// the user.
//
// For more details, check Reconcile and its Result here:
// - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.13.0/pkg/reconcile
func (r *CronJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := log.FromContext(ctx)
按名称加载CronJob
我们将使用客户端获取CronJob。所有客户端方法都将上下文(以允许取消)作为其第一个参数,并将有问题的对象作为其最后一个参数。Get有点特殊,它将 NamespacedName 作为中间参数(大多数没有中间参数,我们将在下面看到)。
许多客户端方法也在最后采用可变参数选项。
var cronJob batchv1.CronJob
if err := r.Get(ctx, req.NamespacedName, &cronJob); err != nil {
log.Error(err, "unable to fetch CronJob")
// we'll ignore not-found errors, since they can't be fixed by an immediate
// requeue (we'll need to wait for a new notification), and we can get them
// on deleted requests.
return ctrl.Result{}, client.IgnoreNotFound(err)
}
列出所有活动作业,并更新状态
要完全更新状态,我们需要列出此命名空间中属于此CronJob的所有子作业。与Get类似,我们可以使用List方法列出子作业。
var childJobs kbatch.JobList
if err := r.List(ctx, &childJobs, client.InNamespace(req.Namespace), client.MatchingFields{jobOwnerKey: req.Name}); err != nil {
log.Error(err, "unable to list child Jobs")
return ctrl.Result{}, err
}
一旦我们拥有了所有的作业,我们将把它们分成活动的、成功的和失败的作业,跟踪最近的运行,以便我们可以在状态中记录它。
请记住,状态应该能够从世界的状态中重新构建,因此通常从根对象的状态中读取不是一个好主意。相反,你应该在每次运行时重新构建它。这就是我们要做的。
我们可以使用状态条件检查作业是否“完成”以及它是成功还是失败。我们将把这个逻辑放在一个帮助器中,以使我们的代码更清晰。
// find the active list of jobs
var activeJobs []*kbatch.Job
var successfulJobs []*kbatch.Job
var failedJobs []*kbatch.Job
var mostRecentTime *time.Time // find the last run so we can update the status
// isJobFinished
// getScheduledTimeForJob
for i, job := range childJobs.Items {
_, finishedType := isJobFinished(&job)
switch finishedType {
case "": // ongoing
activeJobs = append(activeJobs, &childJobs.Items[i])
case kbatch.JobFailed:
failedJobs = append(failedJobs, &childJobs.Items[i])
case kbatch.JobComplete:
successfulJobs = append(successfulJobs, &childJobs.Items[i])
}
// We'll store the launch time in an annotation, so we'll reconstitute that from
// the active jobs themselves.
scheduledTimeForJob, err := getScheduledTimeForJob(&job)
if err != nil {
log.Error(err, "unable to parse schedule time for child job", "job", &job)
continue
}
if scheduledTimeForJob != nil {
if mostRecentTime == nil {
mostRecentTime = scheduledTimeForJob
} else if mostRecentTime.Before(*scheduledTimeForJob) {
mostRecentTime = scheduledTimeForJob
}
}
}
if mostRecentTime != nil {
cronJob.Status.LastScheduleTime = &metav1.Time{Time: *mostRecentTime}
} else {
cronJob.Status.LastScheduleTime = nil
}
cronJob.Status.Active = nil
for _, activeJob := range activeJobs {
jobRef, err := ref.GetReference(r.Scheme, activeJob)
if err != nil {
log.Error(err, "unable to make reference to active job", "job", activeJob)
continue
}
cronJob.Status.Active = append(cronJob.Status.Active, *jobRef)
}
在这里,我们将记录我们在稍高的日志级别上观察到的作业数量,以便进行调试。请注意,我们不是使用格式字符串,而是使用固定消息,并附加带有额外信息的键值对。这使得过滤和查询日志行更加容易。
log.V(1).Info("job count", "active jobs", len(activeJobs), "successful jobs", len(successfulJobs), "failed jobs", len(failedJobs))
使用我们收集的数据,我们将更新CRD的状态。就像以前一样,我们利用我们的客户。为了专门更新状态子资源,我们将使用客户端的 Status 部分和 Update 方法。
status子资源忽略对spec的更改,因此它不太可能与任何其他更新冲突,并且可以具有单独的权限。
if err := r.Status().Update(ctx, &cronJob); err != nil {
log.Error(err, "unable to update CronJob status")
return ctrl.Result{}, err
}
一旦我们更新了我们的状态,我们就可以继续确保世界的状态与我们在规范中想要的相匹配。
根据历史限制清理旧作业
首先,我们将努力清理旧的工作,这样我们就不会留下太多的闲置工作。
// NB: deleting these are "best effort" -- if we fail on a particular one,
// we won't requeue just to finish the deleting.
if cronJob.Spec.FailedJobsHistoryLimit != nil {
sort.Slice(failedJobs, func(i, j int) bool {
if failedJobs[i].Status.StartTime == nil {
return failedJobs[j].Status.StartTime != nil
}
return failedJobs[i].Status.StartTime.Before(failedJobs[j].Status.StartTime)
})
for i, job := range failedJobs {
if int32(i) >= int32(len(failedJobs))-*cronJob.Spec.FailedJobsHistoryLimit {
break
}
if err := r.Delete(ctx, job, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) != nil {
log.Error(err, "unable to delete old failed job", "job", job)
} else {
log.V(0).Info("deleted old failed job", "job", job)
}
}
}
if cronJob.Spec.SuccessfulJobsHistoryLimit != nil {
sort.Slice(successfulJobs, func(i, j int) bool {
if successfulJobs[i].Status.StartTime == nil {
return successfulJobs[j].Status.StartTime != nil
}
return successfulJobs[i].Status.StartTime.Before(successfulJobs[j].Status.StartTime)
})
for i, job := range successfulJobs {
if int32(i) >= int32(len(successfulJobs))-*cronJob.Spec.SuccessfulJobsHistoryLimit {
break
}
if err := r.Delete(ctx, job, client.PropagationPolicy(metav1.DeletePropagationBackground)); (err) != nil {
log.Error(err, "unable to delete old successful job", "job", job)
} else {
log.V(0).Info("deleted old successful job", "job", job)
}
}
}
检查是否停止
如果这个对象被挂起,我们不想运行任何作业,所以我们现在停止。如果我们正在运行的作业出现故障,并且我们希望暂停运行以进行调查或处理集群,而不删除对象,则此功能非常有用。
if cronJob.Spec.Suspend != nil && *cronJob.Spec.Suspend {
log.V(1).Info("cronjob suspended, skipping")
return ctrl.Result{}, nil
}
获取下一次计划运行
如果我们没有暂停,我们将需要计算下一个计划的运行,以及我们是否有一个尚未处理的运行。
// getNextSchedule
// figure out the next times that we need to create
// jobs at (or anything we missed).
missedRun, nextRun, err := getNextSchedule(&cronJob, r.Now())
if err != nil {
log.Error(err, "unable to figure out CronJob schedule")
// we don't really care about requeuing until we get an update that
// fixes the schedule, so don't return an error
return ctrl.Result{}, nil
}
我们将准备最终的请求,以便在下一个作业之前重新排队,然后确定我们是否实际需要运行。
scheduledResult := ctrl.Result{RequeueAfter: nextRun.Sub(r.Now())} // save this so we can re-use it elsewhere
log = log.WithValues("now", r.Now(), "next run", nextRun)
并发策略
运行一个新的作业,如果它是按计划进行的,没有超过截止日期,也没有被我们的并发策略阻塞
如果我们错过了一个运行,并且我们仍然在开始它的截止日期内,我们将需要运行一个作业。
if missedRun.IsZero() {
log.V(1).Info("no upcoming scheduled times, sleeping until next")
return scheduledResult, nil
}
// make sure we're not too late to start the run
log = log.WithValues("current run", missedRun)
tooLate := false
if cronJob.Spec.StartingDeadlineSeconds != nil {
tooLate = missedRun.Add(time.Duration(*cronJob.Spec.StartingDeadlineSeconds) * time.Second).Before(r.Now())
}
if tooLate {
log.V(1).Info("missed starting deadline for last run, sleeping till next")
// TODO(directxman12): events
return scheduledResult, nil
}
如果我们实际上必须运行一个作业,我们需要等待现有的作业完成,替换现有的作业,或者只是添加新的作业。如果我们的信息由于缓存延迟而过期,我们将在获得最新信息时重新排队。
// figure out how to run this job -- concurrency policy might forbid us from running
// multiple at the same time...
if cronJob.Spec.ConcurrencyPolicy == batchv1.ForbidConcurrent && len(activeJobs) > 0 {
log.V(1).Info("concurrency policy blocks concurrent runs, skipping", "num active", len(activeJobs))
return scheduledResult, nil
}
// ...or instruct us to replace existing ones...
if cronJob.Spec.ConcurrencyPolicy == batchv1.ReplaceConcurrent {
for _, activeJob := range activeJobs {
// we don't care if the job was already deleted
if err := r.Delete(ctx, activeJob, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) != nil {
log.Error(err, "unable to delete active job", "job", activeJob)
return ctrl.Result{}, err
}
}
}
一旦我们弄清楚了如何处理现有的工作,我们实际上就会创造出我们想要的工作
// constructJobForCronJob
// actually make the job...
job, err := constructJobForCronJob(&cronJob, missedRun)
if err != nil {
log.Error(err, "unable to construct job from template")
// don't bother requeuing until we get a change to the spec
return scheduledResult, nil
}
// ...and create it on the cluster
if err := r.Create(ctx, job); err != nil {
log.Error(err, "unable to create Job for CronJob", "job", job)
return ctrl.Result{}, err
}
log.V(1).Info("created Job for CronJob run", "job", job)
当我们看到一个正在运行的作业或者到了下一个计划运行的时间时重新排队
最后,我们将返回上面准备的结果,它表示我们希望在下一次运行时重新排队。
这是一个最大的期限--如果在这期间发生了其他变化,比如我们的工作开始或结束,我们被修改,等等,我们可能会更快地再次协调。
// we'll requeue once we see the running job, and update our status
return scheduledResult, nil
}
启动 Controller
接下来我们可以启动这个 Controller 来看一下效果
直接运行 make run 即可运行代码,再终端中可以看到日志输出。
查看 Pod 是否成功创建出来了:
kubectl get pod
部署 Controller
我们将其部署了了一个 示例,也运行 Controller 看到了相应的 副本 Pod 被创建出来了,现在我们进一步模拟 Operator 实际使用时的部署方式,把 Controller 打包后以 container 的方式部署到 Kubernetes 集群环境中:
# 构建镜像
make docker-build IMG=application-operator:v0.0.1
# 推送到 Kind 环境
kind load docker-image
# 部署 controller
make deploy IMG=application-operator:v0.0.1
补充:我们可以在 dockerfile 中解决Go语言的代理问题:
ENV GOPROXY=https://goproxy.op
资源清理
上面有讲过,用 Makefile 命令清理还是很方便的,我们直接清理就好了:
# 卸载 controller
make undeploy
# 卸载 CRD
make uninstall
Client-go
Kubeilder 已经屏蔽了 client-go 的细节,但是如果希望深入掌握 Operator 开发机制,还是需要对 Client-go 熟悉的。
这是一篇还没入门的概念了解笔记:
Kubernetes API是一组REST API,用于与Kubernetes集群交互。这些API允许开发人员执行各种操作,包括管理Pod、Deployment、Service、Namespace等。Kubernetes API由一组资源对象表示,例如Pod、Service、ReplicaSet等。这些资源对象由Kubernetes API Server管理,并可以通过kubectl等工具进行查询和修改。
| 方式 | 特点 | 支持者 |
|---|---|---|
| Kubernetes dashboard | 直接通过Web UI进行操作,简单直接,可定制化程度低 | 官方支持 |
| kubectl | 命令行操作,功能最全,但是比较复杂,适合对其进行进一步的分装,定制功能,版本适配最好 | 官方支持 |
| client-go | 从kubernetes的代码中抽离出来的客户端包,简单易用,但需要小心区分kubernetes的API版本 | 官方支持 |
Kubernetes API Server 提供的是默认的 HTTPS 服务,而且是双向的 TLS 认证,而我们目前的关注点是 API 本身,因此先通过 Kubectl 来代理 API Server 服务。
❯ kubectl proxy --port=8080
接下来就可以通过简单的 HTTP 请求来和 API Server 交互了:
❯ curl localhost:8080/version
{
"major": "1",
"minor": "19",
"gitVersion": "v1.19.16",
"gitCommit": "e37e4ab4cc8dcda84f1344dda47a97bb1927d074",
"gitTreeState": "clean",
"buildDate": "2022-10-26T15:40:32Z",
"goVersion": "go1.15.15",
"compiler": "gc",
"platform": "linux/amd64"
}#
我们可能还需要一个配置文件来描述 Deployment 资源,在本地创建一个 nginx-deploy.yaml 文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
我们创建它:
❯ kubectl create -f nginx-deploy.yaml
deployment.apps/nginx-deployment created
❯ k get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
my-nginx-app 0/3 3 0 23h
nginx-deployment 3/3 3 3 19s
Deployment 创建的 API 和 在 Kubernetes 中 API 的路径一样:
POST /apis/apps/v1/namespace/{namespace}/deployment
Kubernetes中使用的 RESTful 接口更新这些对象,包括操作:
- GET:从服务器读取一个资源。 - POST:在服务器上创建一个新的资源。 - PUT:在服务器上更新一个资源。 - DELETE:从服务器删除一个资源。 - HEAD:从服务器读取一个资源的头信息。 - PATCH:在服务器上部分更新一个资源。 - OPTIONS:列出服务器支持的方法和功能。
既然想尝试 kubectl,那么来点新花样:
❯ curl localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deploymen
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "deployments.apps \"nginx-deploymen\" not found",
"reason": "NotFound",
"details": {
"name": "nginx-deploymen",
"group": "apps",
"kind": "deployments"
},
"code": 404
}#
资源创建:
Depolyment 的创建 API 是:apps/v1 中的 Deployment。
POST /apis/apps/v1/namespaces/{namespace}/deployments
执行以下命令在 default 命名空间下创建一个 deployment:
❯ curl -X POST --header 'Content-Type: application/yaml' --data-binary @nginx-deploy.yaml http://localhost:8080/apis/apps/v1/namespaces/default/deployments
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "deployments.apps \"nginx-deployment\" already exists",
"reason": "AlreadyExists",
"details": {
"name": "nginx-deployment",
"group": "apps",
"kind": "deployments"
},
"code": 409
}#
sample-controller
我们将用于实验创建操作符的第一个工具是sample-controller,你可以在这里找到:https://github.com/kubernetes/sample-controller。
这个项目为 Foo 类型实现了一个简单的操作符,当我们创建一个自定义对象 foo 时,它将创建一个带有一些公共Docker镜像和特定数量副本的部署。
我们在上面已经下载过,现在我尝试编译它:
go version:
gvm use go1.20
❯ export SAMPLE=$(pwd)/sample-controller
❯ git clone https://github.com/cubxxw/sample-controller.git $SAMPLE && cd $SAMPLE;
❯ go build -o ctrl .
然后我们创建一个 CRD:
❯ kubectl apply -f artifacts/examples/crd-status-subresource.yaml
customresourcedefinition.apiextensions.k8s.io/foos.samplecontroller.k8s.io created
❯ k get CustomResourceDefinition
NAME CREATED AT
crontabs.stable.example.com 2023-04-07T09:17:55Z
foos.samplecontroller.k8s.io 2023-04-08T12:09:46Z
guestbooks.webapp.my.domain 2023-04-07T15:42:22Z
然后我们运行控制器:
./ctrl -kubeconfig ~/.kube/config -logtostderr=true
-logtostderr=true:将日志记录到标准错误而不是文件(默认为true)
现在,我们可以在另一个终端上操作 Foo 对象,看看控制器会发生什么:
❯ kubectl apply -f artifacts/examples/example-foo.yaml
foo.samplecontroller.k8s.io/example-foo created
❯ k get Foo
NAME AGE
example-foo 9s
# ----- 删除 Foo -------
❯ kubectl delete -f artifacts/examples/example-foo.yaml
foo.samplecontroller.k8s.io "example-foo" deleted
❯ k get pod | grep -i "Foo"
❯ k get Foo
No resources found in default namespace.
在编写和使用Kubernetes 1.11.0时,控制器将在创建部署后更新
foo对象的状态时进入无限循环:在updateFooStatus函数中,你必须通过调用UpdateStatus(fooCopy)来更改对Update(fooCopy)的调用。
很好理解不是吗,apply 声明式在 controller 中也是通过 for 循环不断的进行校验。检查 status 和 spec 的区别,是否达成一致。
我找出官方的最简单的案例拿出来:
for {
desired := getDesiredState() // 期望状态
current := getCurrentState() // 实际状态
makeChanges(desired, current) // 调谐过程
}
可以看出本质上就是一个循环,通过
getDesiredState()获取到 spec 中的期望状态,通过getCurrentState()获取到 status 当前集群的实际状态,然后进行调谐。
到目前为止一切顺利,控制器使工作:当我们创建 foo 对象时,它会创建一个部署,当我们删除该对象时,它会停止部署。
现在我们可以进一步调整CRD和控制器,以使用我们自己的自定义资源定义。
假设我们的目标是编写一个 operator ,它 将在集群的节点上部署一个守护进程。它将使用 DaemonSet 对象来部署此守护进程,我们希望能够指定一个标签,以便仅在标记有此标签的节点上部署守护进程。我们还希望能够指定要部署的 Docker 镜像,而不是像sample-controller那样使用静态镜像。
让我们首先为 GenericDaemon 类型创建自定义资源定义:
❯ cat artifacts/generic-daemon/crd.yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: genericdaemons.mydomain.com
spec:
group: mydomain.com
version: v1beta1
names:
kind: Genericdaemon
plural: genericdaemons
scope: Namespaced
validation:
openAPIV3Schema:
properties:
spec:
properties:
label:
type: string
image:
type: string
required:
- image
下面是要部署的守护进程的第一个示例:
// artifacts/generic-daemon/syslog.yaml
apiVersion: mydomain.com/v1beta1
kind: Genericdaemon
metadata:
name: syslog
spec:
label: logs
image: mbessler/syslogdocker
现在我们必须为API构建go文件,以便从操作符访问这个新的自定义资源定义。为此,让我们创建一个新目录 pkg/apis/genericdaemon ,我们将在其中复制在 pkg/apis/samplecontroller 中找到的文件(但不包括 zz_generated.deepcopy.go )
❯ tree pkg/apis/genericdaemon/
pkg/apis/genericdaemon/
├── register.go
└── v1alpha1
├── doc.go
├── register.go
└── types.go
并调整其内容(更改的部分以粗体显示):
////////////////
// register.go
////////////////
package genericdaemon
const (
GroupName = "mydomain.com"
)
/////////////////////
// v1beta1/doc.go
/////////////////////
// +k8s:deepcopy-gen=package
// Package v1beta1 is the v1beta1 version of the API.
// +groupName=mydomain.com
package v1beta1
/////////////////////////
// v1beta1/register.go
/////////////////////////
package v1beta1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
genericdaemon "k8s.io/sample-controller/pkg/apis/genericdaemon"
)
// SchemeGroupVersion is group version used to register these objects
var SchemeGroupVersion = schema.GroupVersion{Group: genericdaemon.GroupName, Version: "v1beta1"}
// Kind takes an unqualified kind and returns back a Group qualified GroupKind
func Kind(kind string) schema.GroupKind {
return SchemeGroupVersion.WithKind(kind).GroupKind()
}
// Resource takes an unqualified resource and returns a Group qualified GroupResource
func Resource(resource string) schema.GroupResource {
return SchemeGroupVersion.WithResource(resource).GroupResource()
}
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
AddToScheme = SchemeBuilder.AddToScheme
)
// Adds the list of known types to Scheme.
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(SchemeGroupVersion,
&Genericdaemon{},
&GenericdaemonList{},
)
metav1.AddToGroupVersion(scheme, SchemeGroupVersion)
return nil
}
//////////////////////
// v1beta1/types.go
//////////////////////
package v1beta1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// Genericdaemon is a specification for a Generic Daemon resource
type Genericdaemon struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec GenericdaemonSpec `json:"spec"`
Status GenericdaemonStatus `json:"status"`
}
// GenericDaemonSpec is the spec for a GenericDaemon resource
type GenericdaemonSpec struct {
Label string `json:"label"`
Image string `json:"image"`
}
// GenericDaemonStatus is the status for a GenericDaemon resource
type GenericdaemonStatus struct {
Installed int32 `json:"installed"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// GenericDaemonList is a list of GenericDaemon resources
type GenericdaemonList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata"`
Items []Genericdaemon `json:"items"`
}
我们再来看看它为我们提供了哪些可用的脚本:
它使用www.example.com中的生成器k8s.io/code-generator 生成一个类型化的客户端、informers、listers和deep-copy函数。你可以使用./hack/update-codegen.sh脚本自己执行此操作。
代码生成器
k8s.io/client-go 提供了对 k8s 原生资源的informer和clientset等等,但对于自定义资源的操作则相对低效,需要使用 rest api 和 dynamic client 来操作,并自己实现反序列化等功能。
code-generator 提供了以下工具用于为k8s中的资源生成相关代码,可以更加方便的操作自定义资源:
deepcopy-gen: 生成深度拷贝对象方法 ~
使用方法:
- 在文件中添加注释
// +k8s:deepcopy-gen=package - 为单个类型添加自动生成
// +k8s:deepcopy-gen=true - 为单个类型关闭自动生成
// +k8s:deepcopy-gen=false
client-gen: 为资源生成标准的操作方法(get; list; watch; create; update; patch; delete)
在
pkg/apis/${GROUP}/${VERSION}/types.go中使用,使用// +genclient标记对应类型生成的客户端, 如果与该类型相关联的资源不是命名空间范围的(例如PersistentVolume), 则还需要附加// + genclient:nonNamespaced标记,
// +genclient- 生成默认的客户端动作函数(create, update, delete, get, list, update, patch, watch以及 是否生成updateStatus取决于.Status字段是否存在)。// +genclient:nonNamespaced- 所有动作函数都是在没有名称空间的情况下生成// +genclient:onlyVerbs=create,get- 指定的动作函数被生成.// +genclient:skipVerbs=watch- 生成watch以外所有的动作函数.// +genclient:noStatus- 即使.Status字段存在也不生成updateStatus动作函数
informer-gen: 生成informer,提供事件机制(AddFunc,UpdateFunc,DeleteFunc)来响应kubernetes的event
lister-gen: 为 get 和 list 方法提供只读缓存层
conversion-gen是用于自动生成在内部和外部类型之间转换的函数的工具
一般的转换代码生成任务涉及三套程序包:
- 一套包含内部类型的程序包。
- 一套包含外部类型的程序包。
- 单个目标程序包(即,生成的转换函数所在的位置,以及开发人员授权的转换功能所在的位置)。包含内部类型的包在
Kubernetes的常规代码生成框架中扮演着称为peer package的角色。
使用方法:
- 标记转换内部软件包
// +k8s:conversion-gen=<import-path-of-internal-package> - 标记转换外部软件包
// +k8s:conversion-gen-external-types=<import-path-of-external-package> - 标记不转换对应注释或结构
// +k8s:conversion-gen=false
defaulter-gen 用于生产Defaulter函数
- 为包含字段的所有类型创建defaulters,
// +k8s:defaulter-gen=<field-name-to-flag> - 所有都生成
// +k8s:defaulter-gen=true|false
go-to-protobuf 通过go struct生成 pb idl
import-boss 在给定存储库中强制执行导入限制
openapi-gen 生成openAPI定义
使用方法:
+k8s:openapi-gen=true为指定包或方法开启+k8s:openapi-gen=false指定包关闭
register-gen 生成register
set-gen
code-generator整合了这些gen,使用脚本generate-groups.sh和generate-internal-groups.sh可以为自定义资源生产相关代码。
脚本自动生成
脚本 hack/update-codegen.sh 可用于围绕我们使用这些先前文件定义的新自定义资源定义生成代码。我们将不得不调整这个脚本来为我们的新 CRD 生成文件:
update-codegen脚本将自动生成以下文件& 目录:
pkg/apis/samplecontroller/v1alpha1/zz_generated.deepcopy.gopkg/generated/
// hack/update-codegen.sh
#!/usr/bin/env bash
set -o errexit
set -o nounset
set -o pipefail
SCRIPT_ROOT=$(dirname "${BASH_SOURCE[0]}")/..
CODEGEN_PKG=${CODEGEN_PKG:-$(cd "${SCRIPT_ROOT}"; ls -d -1 ./vendor/k8s.io/code-generator 2>/dev/null || echo ../code-generator)}
# generate the code with:
# --output-base because this script should also be able to run inside the vendor dir of
# k8s.io/kubernetes. The output-base is needed for the generators to output into the vendor dir
# instead of the $GOPATH directly. For normal projects this can be dropped.
echo "===> Generating code..."
"${CODEGEN_PKG}/generate-groups.sh" "deepcopy,client,informer,lister" \
k8s.io/sample-controller/pkg/generated \
k8s.io/sample-controller/pkg/apis \
samplecontroller:v1alpha1 \
--output-base "$(dirname "${BASH_SOURCE[0]}")/../../.." \
--go-header-file "${SCRIPT_ROOT}"/hack/boilerplate.go.txt
# To use your own boilerplate text append:
# --go-header-file "${SCRIPT_ROOT}"/hack/custom-boilerplate.go.txt
echo "===> Generating genericdaemon code"
"${CODEGEN_PKG}/generate-groups.sh" "deepcopy,client,informer,lister" \
k8s.io/sample-controller/pkg/generated \
k8s.io/sample-controller/pkg/apis \
genericdaemon:v1beta1 \
--output-base "$(dirname "${BASH_SOURCE[0]}")/../../.." \
--go-header-file "${SCRIPT_ROOT}"/hack/boilerplate.go.txt
然后执行它:
❯ ./hack/update-codegen.sh
我们现在可以调整我们的operator 。首先,我们必须将所有对前一个 Foo 类型的引用更改为 Genericdaemon 类型。第二,当创建新的通用守护进程时,我们必须创建Daemonset而不是部署。
将 operator 部署到Kubernetes集群
当我们根据需要修改完sample-controller后,我们需要将其部署到kubernetes集群。事实上,在这个时候,我们已经通过使用我们的凭证从我们的开发系统运行它来测试它。
下面是一个简单的Dockerfile,用于使用operator构建Docker镜像(你必须从原始的sample-controller中删除所有代码才能构建镜像):
FROM golang
RUN mkdir -p /go/src/k8s.io/sample-controller
ADD . /go/src/k8s.io/sample-controller
WORKDIR /go
RUN go get ./...
RUN go install -v ./...
CMD ["/go/bin/sample-controller"]
我们现在可以构建镜像并将其推送到Docker Hub:
❯ docker build . -t cubxxw/genericdaemon
❯ docker push cubxxw/genericdaemon
⚠️ 最开始使用
buildpacks来构建的,太离谱了,放弃了~
最后,使用此新映像启动部署:
// deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-controller
spec:
replicas: 1
selector:
matchLabels:
app: sample
template:
metadata:
labels:
app: sample
spec:
containers:
- name: sample
image: "cubxxw/genericdaemon:latest"
and kubectl apply -f deploy.yaml
❯ k get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
my-nginx-app 0/3 3 0 29h
nginx-deployment 3/3 3 3 5h42m
sample-controller 0/1 1 0 34s
❯ k get pod | grep -i sample-controller
sample-controller-779777db4b-xh74l 0/1 CrashLoopBackOff 5 6m20s
operator 现在正在运行,但是如果我们检查 pod 的日志,我们可以看到授权存在问题;POD不获得对不同资源的访问权限:
❯ kubectl logs sample-controller-779777db4b-xh74l
E0721 14:34:50.499584 1 reflector.go:134] k8s.io/sample-controller/pkg/client/informers/externalversions/factory.go:117: Failed to list *v1beta1.Genericdaemon: genericdaemons.mydomain.com is forbidden: User "system:serviceaccount:default:default" cannot list genericdaemons.mydomain.com at the cluster scope
E0721 14:34:50.500385 1 reflector.go:134] k8s.io/client-go/informers/factory.go:131: Failed to list *v1.DaemonSet: daemonsets.apps is forbidden: User "system:serviceaccount:default:default" cannot list daemonsets.apps at the cluster scope
[...]
我们需要创建一个 ClusterRole 和一个 ClusterRoleBinding 来给予operator 必要的权限:
// rbac_role.yaml
kind: ClusterRole
metadata:
name: operator-role
rules:
- apiGroups:
- apps
resources:
- daemonsets
verbs:
- get
- list
- watch
- create
- update
- patch
- delete
- apiGroups:
- mydomain.com
resources:
- genericdaemons
verbs:
- get
- list
- watch
- create
- update
- patch
- delete
// rbac_role_binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: operator-rolebinding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: operator-role
subjects:
- kind: ServiceAccount
name: default
namespace: default
部署:
❯ kubectl apply -f rbac_role.yaml
❯ kubectl delete -f deploy.yaml
❯ kubectl apply -f deploy.yaml
sample-controller CRD 资源定义源码
首先,最开始看的还是 CRD 的资源定义部分(sample-controller/artifacts/examples/crd.yaml):
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# 名字必需与下面的 spec 字段匹配,并且格式为 '<名称的复数形式>.<组名>'
name: foos.samplecontroller.k8s.io
spec:
# 组名称,用于 REST API: /apis/<组>/<版本>
group: samplecontroller.k8s.io
# 列举此 CustomResourceDefinition 所支持的版本
version: v1alpha1
names:
# kind 通常是单数形式的驼峰编码(CamelCased)形式。你的资源清单会使用这一形式。
kind: Foo
# 名称的复数形式,用于 URL:/apis/<组>/<版本>/<名称的复数形式>
plural: foos
# 名称的单数形式,作为命令行使用时和显示时的别名
singular: crontab
# shortNames 允许你在命令行使用较短的字符串来匹配资源
shortNames:
- f
# 可以是 Namespaced 或 Cluster
scope: Namespaced
- 该定义文件,声明了一种名为 Foo 的资源,告诉 API Server,有一种资源叫做 Foo
- 该 Foo 资源将被 sample-controller 所监听,并对其相关事件进行处理
- CRD 可以是名字空间作用域的,也可以 是集群作用域的,取决于 CRD 的
scope字段设置。 - 自动代码生成工具(上面讲的update-codegen) 将controller之外的事情都做好了,我们只要专注于controller的开发就好。
自己编写controller有三步:
定义CRD
生成自定义资源的Clientset、Informers、Listers等
- Clientset 用于和 Kubernetes 进行交互
- Informers 机制用于 监听 Kubernetes 中 API Server 的资源变化,一般和 WOrksSqueue 结合使用,一个是监听,一个是缓存到排队队列中(三种接口实现)
- Listers 是 Kubernetes 中的另一种机制,用于从 Informers 缓存中获取资源对象的列表。
编写Controller等代码
Foo 资源的 yaml 定义
源文件:
❯ cat artifacts/examples/example-foo.yaml
apiVersion: samplecontroller.k8s.io/v1alpha1
kind: Foo
metadata:
name: example-foo
spec:
deploymentName: example-foo
replicas: 1
📜 对上面的解释:
- 该文件声明要创建的资源为 Foo 类型,副本数为 1
- 这个创建事件会被
sample-controller拦截和处理
分析 Controller 的实现逻辑
既然是从 main.go 开始的,那么我们主要的逻辑在这里:
func main() {
klog.InitFlags(nil)
flag.Parse()
// set up signals so we handle the shutdown signal gracefully
ctx := signals.SetupSignalHandler()
logger := klog.FromContext(ctx)
cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig)
if err != nil {
logger.Error(err, "Error building kubeconfig")
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
}
kubeClient, err := kubernetes.NewForConfig(cfg)
if err != nil {
logger.Error(err, "Error building kubernetes clientset")
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
}
exampleClient, err := clientset.NewForConfig(cfg)
if err != nil {
logger.Error(err, "Error building kubernetes clientset")
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
}
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
exampleInformerFactory := informers.NewSharedInformerFactory(exampleClient, time.Second*30)
controller := NewController(ctx, kubeClient, exampleClient,
kubeInformerFactory.Apps().V1().Deployments(),
exampleInformerFactory.Samplecontroller().V1alpha1().Foos())
// notice that there is no need to run Start methods in a separate goroutine. (i.e. go kubeInformerFactory.Start(ctx.done())
// Start method is non-blocking and runs all registered informers in a dedicated goroutine.
kubeInformerFactory.Start(ctx.Done())
exampleInformerFactory.Start(ctx.Done())
if err = controller.Run(ctx, 2); err != nil {
logger.Error(err, "Error running controller")
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
}
}
📜 大致流程对上面的解释:
读取 kubeconfig 配置,构造用于事件监听的
Kubernetes Client。这里创建了两个,一个监听普通事件,一个监听 Foo 事件。
基于
Client构造监听相关的informer。基于
Client、Informer初始化自定义Controller,监听Deployment以及Foos资源变化。开启
Controller。
那么接下来就是最主要的,就是 controller 的实现逻辑了(controller.go)
Controller 的结构体定义如下:
// Controller is the controller implementation for Foo resources
type Controller struct {
// kubeclientset is a standard kubernetes clientset
kubeclientset kubernetes.Interface
// sampleclientset is a clientset for our own API group
sampleclientset clientset.Interface
deploymentsLister appslisters.DeploymentLister
deploymentsSynced cache.InformerSynced
foosLister listers.FooLister
foosSynced cache.InformerSynced
// workqueue is a rate limited work queue. This is used to queue work to be
// processed instead of performing it as soon as a change happens. This
// means we can ensure we only process a fixed amount of resources at a
// time, and makes it easy to ensure we are never processing the same item
// simultaneously in two different workers.
workqueue workqueue.RateLimitingInterface
// recorder is an event recorder for recording Event resources to the
// Kubernetes API.
recorder record.EventRecorder
}
📜 对上面的解释:
- Controller 的关键成员即两个事件的 Listener(
appslisters.DeploymentLister、listers.FooLister)这两个成员将由 main 函数传入参数进行初始化 - 此外,为了缓冲事件处理,这里使用队列暂存事件,相关成员即为
workqueue.RateLimitingInterface kubeclientset是一个标准的 Kubernetes 客户端集,用于与 Kubernetes API 进行交互。sampleclientset是我们自己的 API 组的客户端集,用于与我们的自定义API资源进行交互。deploymentsLister是一个 Deployment 的 Lister 接口,用于获取Deployment资源的列表信息。deploymentsSynced是一个 Deployment 的 InformerSynced 接口,用于确定Deployment资源是否已经同步完毕。foosLister是一个 Foo 的Lister接口,用于获取Foo资源的列表信息。foosSynced是一个 Foo 的InformerSynced接口,用于确定Foo资源是否已经同步完毕。workqueue是一个速率限制的工作队列,用于处理工作项。通过使用工作队列,我们可以确保一次只处理一定数量的资源,并且可以轻松确保我们不会同时在两个不同的工作者中处理同一项资源。recorder是事件记录器,用于记录 Event 资源到 Kubernetes API 中。
控制器的实现过程中,使用了 informer 和 workqueue 两个重要的组件,它们分别用于监听资源的变化和处理任务。当某个资源发生变化时,informer 会将该资源加入 workqueue 中等待处理。处理任务时,syncHandler 函数会获取任务对应的 Foo 和 Deployment 资源,并比较它们的状态是否一致,如果不一致则进行同步,同步成功后更新状态。整个过程中,使用了 Kubernetes 中的事件记录器将事件记录到 Kubernetes API 中,以便于调试和监控。
接着,分析 Controller 的构造过程,代码如下:
func NewController(
kubeclientset kubernetes.Interface,
sampleclientset clientset.Interface,
deploymentInformer appsinformers.DeploymentInformer,
fooInformer informers.FooInformer) *Controller {
// Create event broadcaster
// Add sample-controller types to the default Kubernetes Scheme so Events can be
// logged for sample-controller types.
utilruntime.Must(samplescheme.AddToScheme(scheme.Scheme))
klog.V(4).Info("Creating event broadcaster")
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&typedcorev1.EventSinkImpl{Interface: kubeclientset.CoreV1().Events("")})
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: controllerAgentName})
controller := &Controller{
kubeclientset: kubeclientset,
sampleclientset: sampleclientset,
deploymentsLister: deploymentInformer.Lister(),
deploymentsSynced: deploymentInformer.Informer().HasSynced,
foosLister: fooInformer.Lister(),
foosSynced: fooInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "Foos"),
recorder: recorder,
}
klog.Info("Setting up event handlers")
// Set up an event handler for when Foo resources change
fooInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.enqueueFoo,
UpdateFunc: func(old, new interface{}) {
controller.enqueueFoo(new)
},
})
// Set up an event handler for when Deployment resources change. This
// handler will lookup the owner of the given Deployment, and if it is
// owned by a Foo resource will enqueue that Foo resource for
// processing. This way, we don't need to implement custom logic for
// handling Deployment resources. More info on this pattern:
// https://github.com/kubernetes/community/blob/8cafef897a22026d42f5e5bb3f104febe7e29830/contributors/devel/controllers.md
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*appsv1.Deployment)
oldDepl := old.(*appsv1.Deployment)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
// Periodic resync will send update events for all known Deployments.
// Two different versions of the same Deployment will always have different RVs.
return
}
controller.handleObject(new)
},
DeleteFunc: controller.handleObject,
})
return controller
}
这是一个初始化的过程,也是在 main.go 中调用的。
将
sample-controller的类型信息(Foo)添加到默认 Kubernetes Scheme,以便能够记录到其事件。基于新
Scheme创建一个事件记录recorder,用于记录来自 “sample-controller” 的事件。基于函数入参及刚刚构造的
recorder,初始化 Controller。设置对
Foo资源变化的事件处理函数(Add、Update 均通过 enqueueFoo 处理)设置对
Deployment资源变化的事件处理函数(Add、Update、Delete 均通过 handleObject 处理)返回初始化的
Controller。
进一步,分析 enqueueFoo 以及 handleObject 的实现
// enqueueFoo takes a Foo resource and converts it into a namespace/name
// string which is then put onto the work queue. This method should *not* be
// passed resources of any type other than Foo.
func (c *Controller) enqueueFoo(obj interface{}) {
var key string
var err error
if key, err = cache.MetaNamespaceKeyFunc(obj); err != nil {
utilruntime.HandleError(err)
return
}
c.workqueue.AddRateLimited(key)
}
// handleObject will take any resource implementing metav1.Object and attempt
// to find the Foo resource that 'owns' it. It does this by looking at the
// objects metadata.ownerReferences field for an appropriate OwnerReference.
// It then enqueues that Foo resource to be processed. If the object does not
// have an appropriate OwnerReference, it will simply be skipped.
func (c *Controller) handleObject(obj interface{}) {
var object metav1.Object
var ok bool
if object, ok = obj.(metav1.Object); !ok {
tombstone, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
utilruntime.HandleError(fmt.Errorf("error decoding object, invalid type"))
return
}
object, ok = tombstone.Obj.(metav1.Object)
if !ok {
utilruntime.HandleError(fmt.Errorf("error decoding object tombstone, invalid type"))
return
}
klog.V(4).Infof("Recovered deleted object '%s' from tombstone", object.GetName())
}
klog.V(4).Infof("Processing object: %s", object.GetName())
if ownerRef := metav1.GetControllerOf(object); ownerRef != nil {
// If this object is not owned by a Foo, we should not do anything more
// with it.
if ownerRef.Kind != "Foo" {
return
}
foo, err := c.foosLister.Foos(object.GetNamespace()).Get(ownerRef.Name)
if err != nil {
klog.V(4).Infof("ignoring orphaned object '%s' of foo '%s'", object.GetSelfLink(), ownerRef.Name)
return
}
c.enqueueFoo(foo)
return
}
}
📜 对上面的解释:
- enqueueFoo 就是解析 Foo 资源为
namespace/name形式的字符串,然后入队 - handleObject 监听了所有实现了
metav1的资源,但只过滤出owner是Foo的,将其解析为namespace/name入队
在构造 Controller 时就已经初始化好事件收集这部分的工作了, 那如何处理队列里的这些事件呢?那就是 Run 函数的操作过程:
Run 函数操作:
// Run will set up the event handlers for types we are interested in, as well
// as syncing informer caches and starting workers. It will block until stopCh
// is closed, at which point it will shutdown the workqueue and wait for
// workers to finish processing their current work items.
func (c *Controller) Run(threadiness int, stopCh <-chan struct{}) error {
defer utilruntime.HandleCrash()
defer c.workqueue.ShutDown()
// Start the informer factories to begin populating the informer caches
klog.Info("Starting Foo controller")
// Wait for the caches to be synced before starting workers
klog.Info("Waiting for informer caches to sync")
if ok := cache.WaitForCacheSync(stopCh, c.deploymentsSynced, c.foosSynced); !ok {
return fmt.Errorf("failed to wait for caches to sync")
}
klog.Info("Starting workers")
// Launch two workers to process Foo resources
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
klog.Info("Started workers")
<-stopCh
klog.Info("Shutting down workers")
return nil
}// Run will set up the event handlers for types we are interested in, as well
// as syncing informer caches and starting workers. It will block until stopCh
// is closed, at which point it will shutdown the workqueue and wait for
// workers to finish processing their current work items.
func (c *Controller) Run(threadiness int, stopCh <-chan struct{}) error {
defer utilruntime.HandleCrash()
defer c.workqueue.ShutDown()
// Start the informer factories to begin populating the informer caches
klog.Info("Starting Foo controller")
// Wait for the caches to be synced before starting workers
klog.Info("Waiting for informer caches to sync")
if ok := cache.WaitForCacheSync(stopCh, c.deploymentsSynced, c.foosSynced); !ok {
return fmt.Errorf("failed to wait for caches to sync")
}
klog.Info("Starting workers")
// Launch two workers to process Foo resources
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
klog.Info("Started workers")
<-stopCh
klog.Info("Shutting down workers")
return nil
}
Run 函数的执行过程大体如下:
- 等待 Informer 同步完成,
- 并发 runWorker,处理队列内事件
runWorker 的定义
// runWorker is a long-running function that will continually call the
// processNextWorkItem function in order to read and process a message on the
// workqueue.
func (c *Controller) runWorker() {
for c.processNextWorkItem() {
}
}
// processNextWorkItem will read a single work item off the workqueue and
// attempt to process it, by calling the syncHandler.
func (c *Controller) processNextWorkItem() bool {
obj, shutdown := c.workqueue.Get()
if shutdown {
return false
}
// We wrap this block in a func so we can defer c.workqueue.Done.
err := func(obj interface{}) error {
// We call Done here so the workqueue knows we have finished
// processing this item. We also must remember to call Forget if we
// do not want this work item being re-queued. For example, we do
// not call Forget if a transient error occurs, instead the item is
// put back on the workqueue and attempted again after a back-off
// period.
defer c.workqueue.Done(obj)
var key string
var ok bool
// We expect strings to come off the workqueue. These are of the
// form namespace/name. We do this as the delayed nature of the
// workqueue means the items in the informer cache may actually be
// more up to date that when the item was initially put onto the
// workqueue.
if key, ok = obj.(string); !ok {
// As the item in the workqueue is actually invalid, we call
// Forget here else we'd go into a loop of attempting to
// process a work item that is invalid.
c.workqueue.Forget(obj)
utilruntime.HandleError(fmt.Errorf("expected string in workqueue but got %#v", obj))
return nil
}
// Run the syncHandler, passing it the namespace/name string of the
// Foo resource to be synced.
if err := c.syncHandler(key); err != nil {
// Put the item back on the workqueue to handle any transient errors.
c.workqueue.AddRateLimited(key)
return fmt.Errorf("error syncing '%s': %s, requeuing", key, err.Error())
}
// Finally, if no error occurs we Forget this item so it does not
// get queued again until another change happens.
c.workqueue.Forget(obj)
klog.Infof("Successfully synced '%s'", key)
return nil
}(obj)
if err != nil {
utilruntime.HandleError(err)
return true
}
return true
}
processNextWorkItem 的处理流程大体如下:
- 从队列取出待处理对象
- 调用
syncHandler处理
再来分析 syncHandler 的处理细节:
syncHandler 就是一个最核心的实现了,这个实现也是比较有意思的,该函数比较实际状态和期望状态,并尝试将两者融合。然后,它更新 Foo 资源的 Status 块以反映资源的当前状态。所以核心步骤就是两个步骤
// syncHandler compares the actual state with the desired, and attempts to
// converge the two. It then updates the Status block of the Foo resource
// with the current status of the resource.
func (c *Controller) syncHandler(key string) error {
// Convert the namespace/name string into a distinct namespace and name
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
utilruntime.HandleError(fmt.Errorf("invalid resource key: %s", key))
return nil
}
// Get the Foo resource with this namespace/name
foo, err := c.foosLister.Foos(namespace).Get(name)
if err != nil {
// The Foo resource may no longer exist, in which case we stop
// processing.
if errors.IsNotFound(err) {
utilruntime.HandleError(fmt.Errorf("foo '%s' in work queue no longer exists", key))
return nil
}
return err
}
deploymentName := foo.Spec.DeploymentName
if deploymentName == "" {
// We choose to absorb the error here as the worker would requeue the
// resource otherwise. Instead, the next time the resource is updated
// the resource will be queued again.
utilruntime.HandleError(fmt.Errorf("%s: deployment name must be specified", key))
return nil
}
// Get the deployment with the name specified in Foo.spec
deployment, err := c.deploymentsLister.Deployments(foo.Namespace).Get(deploymentName)
// If the resource doesn't exist, we'll create it
if errors.IsNotFound(err) {
deployment, err = c.kubeclientset.AppsV1().Deployments(foo.Namespace).Create(newDeployment(foo))
}
// If an error occurs during Get/Create, we'll requeue the item so we can
// attempt processing again later. This could have been caused by a
// temporary network failure, or any other transient reason.
if err != nil {
return err
}
// If the Deployment is not controlled by this Foo resource, we should log
// a warning to the event recorder and ret
if !metav1.IsControlledBy(deployment, foo) {
msg := fmt.Sprintf(MessageResourceExists, deployment.Name)
c.recorder.Event(foo, corev1.EventTypeWarning, ErrResourceExists, msg)
return fmt.Errorf(msg)
}
// If this number of the replicas on the Foo resource is specified, and the
// number does not equal the current desired replicas on the Deployment, we
// should update the Deployment resource.
if foo.Spec.Replicas != nil && *foo.Spec.Replicas != *deployment.Spec.Replicas {
klog.V(4).Infof("Foo %s replicas: %d, deployment replicas: %d", name, *foo.Spec.Replicas, *deployment.Spec.Replicas)
deployment, err = c.kubeclientset.AppsV1().Deployments(foo.Namespace).Update(newDeployment(foo))
}
// If an error occurs during Update, we'll requeue the item so we can
// attempt processing again later. THis could have been caused by a
// temporary network failure, or any other transient reason.
if err != nil {
return err
}
// Finally, we update the status block of the Foo resource to reflect the
// current state of the world
err = c.updateFooStatus(foo, deployment)
if err != nil {
return err
}
c.recorder.Event(foo, corev1.EventTypeNormal, SuccessSynced, MessageResourceSynced)
return nil
}
syncHandler 的处理逻辑大体如下:
根据
namespace/name获取 foo 资源根据
foo,获取其Deployment名称,进而获取 deployment 资源(没有就为其创建)根据
foo的Replicas更新deployment的Replicas(如果不匹配)更新
foo资源的状态为最新deployment的状态(其实就是AvailableReplicas)
由此,可知 foo 的实现实体其实就是 deployment
这里也有一个比较有意思的现象,我们学习 Kubernetes 的时候也知道 Deployment 控制 Pod 是通过两层控制器来实现的,Deployment 控制器使用 ReplicaSet 控制器来确保指定数量的 Pod 始终在运行。当 Deployment 控制器检测到 Pod 数量不足或 Pod 不存在时,它会启动一个新的 ReplicaSet,以便确保指定数量的 Pod 始终在运行。然后,它逐步将新的 ReplicaSet 中的 Pod 替换为旧的 ReplicaSet 中的 Pod,直到旧的 ReplicaSet 中的所有 Pod 都被替换为止。这样,Deployment 控制器就可以实现无宕机更新和回滚操作,从而确保应用程序的高可用性和可靠性。
看下 deployment 的实现代码:
这里也就是 controller 的最终部分了,创建了一个 Deployment 对象,当然在后面会更新实际状态。
// newDeployment creates a new Deployment for a Foo resource. It also sets
// the appropriate OwnerReferences on the resource so handleObject can discover
// the Foo resource that 'owns' it.
func newDeployment(foo *samplev1alpha1.Foo) *appsv1.Deployment {
labels := map[string]string{
"app": "nginx",
"controller": foo.Name,
}
return &appsv1.Deployment{
ObjectMeta: metav1.ObjectMeta{
Name: foo.Spec.DeploymentName,
Namespace: foo.Namespace,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(foo, schema.GroupVersionKind{
Group: samplev1alpha1.SchemeGroupVersion.Group,
Version: samplev1alpha1.SchemeGroupVersion.Version,
Kind: "Foo",
}),
},
},
Spec: appsv1.DeploymentSpec{
Replicas: foo.Spec.Replicas,
Selector: &metav1.LabelSelector{
MatchLabels: labels,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: labels,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: "nginx",
Image: "nginx:latest",
},
},
},
},
},
}
}
简单逻辑就是根据 foo 资源的 namespace、name、deploymentname、replicas 信息
创建 nginx deployment 而已。
需要注意的是 OwnerReferences 里需要与 Foo 类型绑定(Group、Version、Kind),主要是要与采集处匹配,因为 handleObject 中的筛选 Foo 资源代码是根据 Kind 值做的
if ownerRef.Kind != "Foo" {
return
}
自定义 Controller 是如何与 crd.yaml 定义关联的?
我们知道,一开始是通过 crd.yaml 来通告 kubernetes 我们自定义资源的 scheme 的,这里在补充一点,虽然代码生成器的逻辑实现一直有问题,但是太底层的功能,大部分时候都不会直接去用。适当的理解底层实现(informer)的巧妙之后,看一下 controller-runtime的代码,知道怎么用它封装的cache。然后就是关注在 应用要做的事情上,做这部分的实现就够了。有一个特殊情况就是,在这个过程中,你的代码要用另外的CRD,这个时候会麻烦一点。早期的时候,需要搞几步生成代码的操作。但是现在只要是kubebuilder框架生成的CRD,框架生成的代码里会有 addtoscheme 的实现,只需要import 之后,registry一下,就完事儿了。
- 那是如何与 Controller 关联的呢?其实就在于
pkg/apis目录下,满满也都是 Kubernetes 的味道,在资源定义中,不管是 k3s、k0s、还是 Kubernetes,总是不可忽视的是 pkg/apis 目录。 pkg/apis下定义了自定义资源的相关属性信息,我们简单看下:pkg/samplecontroller/v1alpha1/register.go(处理类型 Schema)
// SchemeGroupVersion is group version used to register these objects
var SchemeGroupVersion = schema.GroupVersion{Group: samplecontroller.GroupName, Version: "v1alpha1"}
// Kind takes an unqualified kind and returns back a Group qualified GroupKind
func Kind(kind string) schema.GroupKind {
return SchemeGroupVersion.WithKind(kind).GroupKind()
}
// Resource takes an unqualified resource and returns a Group qualified GroupResource
func Resource(resource string) schema.GroupResource {
return SchemeGroupVersion.WithResource(resource).GroupResource()
}
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
AddToScheme = SchemeBuilder.AddToScheme
)
// Adds the list of known types to Scheme.
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(SchemeGroupVersion,
&Foo{},
&FooList{},
)
metav1.AddToGroupVersion(scheme, SchemeGroupVersion)
return nil
}
与之前的 crd 定义对比下:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: foos.samplecontroller.k8s.io
spec:
group: samplecontroller.k8s.io
version: v1alpha1
names:
kind: Foo
plural: foos
scope: Namespaced
会发现 controller 与 crd 两者的 group、version 都是一致的,这意味着什么?
var SchemeGroupVersion = schema.GroupVersion{Group: samplecontroller.GroupName, Version: "v1alpha1"}
在 Kubernetes 中,namespace 和 name 可以唯一标识一个资源,通过 group 和 version,可以唯一标识 Kubernetes API 中的一个 API 资源。
而且 metadata 的 name 是符合 <plural>.<group> 规范的,那么回到开头的解释,在 k8s 系统中,一旦创建了 CRD,对该 CRD 的增删改查其实就已经被支持了,我们的 Controller 只是监听自己感兴趣的资源事件,做出真实的部署、更新、移除等动作。
在最后,我们也会扩展自己的 类型 blog。
Kubebuilder
快速创建一个 mydemo:
❯ go mod init mydemo
go: creating new go.mod: module mydemo
❯ kubebuilder init --domain mydomain.com
❯ tree -L 2
.
├── Dockerfile
├── Makefile
├── PROJECT
├── README.md
├── cmd
│ └── main.go
├── config
│ ├── default
│ ├── manager
│ ├── prometheus
│ └── rbac
├── go.mod
├── go.sum
└── hack
└── boilerplate.go.txt
最后创建CRD:
❯ kubebuilder create api --group mygroup --version v1beta1 --kind GenericDaemon
kubebuilder 为我们创建了API的源,以访问 api/v1beta1 下的CRD。您可以看到创建的文件与我们之前在 sample-controller 中编辑的文件类似。
写一些代码:
我们需要修改 GenericDaemon 的结构,为我们的对象添加必要的字段。不要忘记记录字段,以便文档生成器可以创建良好的文档:
// api/v1beta1/genericdaemon_types.go
[...]
// GenericDaemonSpec defines the desired state of GenericDaemon
type GenericDaemonSpec struct {
// Label is the value of the 'daemon=' label to set on a node that should run the daemon
Label string `json:"label"`
// Image is the Docker image to run for the daemon
Image string `json:"image"`
}
// GenericDaemonStatus defines the observed state of GenericDaemon
type GenericDaemonStatus struct {
// Count is the number of nodes the daemon is deployed to
Count int32 `json:"count"`
}
[...]
然后让我们按照 genericdaemon_controller.go 文件中的TODO说明进行操作。首先在 add 函数中,让我们听 DaemonSet 而不是 Deployment :
// pkg/controller/genericdaemon/genericdaemon_controller.go
func add(mgr manager.Manager, r reconcile.Reconciler) error {
[...]
// watch a Daemonset created by GenericDaemon
err = c.Watch(&source.Kind{Type: &appsv1.DaemonSet{}}, &handler.EnqueueRequestForOwner{
IsController: true,
OwnerType: &mygroupv1beta1.GenericDaemon{},
})
[...]
}
第二,让我们编写 Reconcile 函数的代码。
// ...
部署和 play
❯ make
❯ make docker-build IMG=cubxxw/genericdaemon
❯ make docker-push IMG=cubxxw/genericdaemon
❯ make deploy
如果您检查 make deploy 命令的输出,您可以看到该命令为operator 部署了CRD、RBAC角色和角色绑定以访问必要的对象,为operator 创建了命名空间,为operator 创建了服务和statefulset。
此时,operator 应运行:
❯ kubectl get pods --namespace=mygroup-system
❯ kubectl logs mygroup-controller-manager-6bdb7f7f88-vnhhb --namespace=mygroup-system
我们现在可以个性化生成的 GenericDaemon 样本:
❯ cat config/samples/mygroup_v1beta1_genericdaemon.yaml
apiVersion: mygroup.mydomain.com/v1beta1
kind: GenericDaemon
metadata:
labels:
app.kubernetes.io/name: genericdaemon
app.kubernetes.io/instance: genericdaemon-sample
app.kubernetes.io/part-of: mygroup
app.kubernetes.io/managed-by: kustomize
app.kubernetes.io/created-by: mygroup
name: genericdaemon-sample
spec:
image: httpd
label: http
并创建它:
❯ kubectl apply -f config/samples/mygroup_v1beta1_genericdaemon.yaml
genericdaemon.mygroup.mydomain.com/genericdaemon-sample created
❯ kubectl get genericdaemon
NAME AGE
genericdaemon-sample 11s
博客元数据
可以将Sample-Controller用于管理 我的博客(docker.nsddd.top OR go.nsddd.top) 的元数据。
按照上面学习编写 controller 的逻辑,我把步骤分为三步(针对 kubebuilder ):
- Create CRD and CR object
- Write controller code
- Deploy controller
不仅如此,我希望将 Kubebuilder 和 code-generator 相结合,使用Kubebuilder生成CRD和一整套控制器架构,再使用 code-generator 生成 informers、listers、clientsets等。
针对通过代码生成器写 controller:
- 定义CRD
- 生成自定义资源的Clientset、Informers、Listers等
- 编写Controller等代码
定义自定义描述
取名为:cat crd-blog.yaml
❯ cat artifacts/examples/crd-blog.yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: blogs.controller.nsddd.top
spec:
group: controller.nsddd.top
version: v1beta1
names:
kind: Blog
plural: blogs
scope: Namespaced
部署该资源定义:
❯ k apply -f artifacts/examples/crd-blog.yaml
customresourcedefinition.apiextensions.k8s.io/blogs.controller.nsddd.top created
❯ k get crd
NAME CREATED AT
blogs.controller.nsddd.top 2023-04-09T04:13:15Z
构建 examples example-blog.yaml:
❯ cat example-blog.yaml
apiVersion: controller.nsddd.top/v1beta1
kind: Blog
metadata:
name: example-blog
spec:
deploymentName: example-blog
replicas: 1
title: "example blog"
author: "Xinwei Xiong"
content: "blog content"
lastUpdate: "2023-04-09"
prev: ""
next: ""
❯ k apply -f artifacts/examples/example-blog.yaml
blog.controller.nsddd.top/example-blog created
❯ k get Blog
NAME AGE
example-blog 61s
当然这还远远不够,没有 controller。
开发关于 blog 资源操控的 controller 端代码
首先在 pkg/apis 下创建目录 nsdddcontroller,然后将 samplecontroller 里的所有文件复制到 nsdddcontroller,我们在学习 sample-controller 的时候演示过案例genericdaemon。
为了 符合 Kubernetes 的版本规范,我们将其作为 bate 版本,可以对外提供~
❯ tree nsdddcontroller
nsdddcontroller
├── register.go
└── v1beta1
├── doc.go
├── register.go
└── types.go
修改注册表的配置:
pkg/apis/nsdddcontroller/register.go
package nsdddcontroller
// GroupName is the group name used in this package
const (
GroupName = "nsdddcontroller.k8s.io"
)
修改 type 文件:
pkg/apis/nsdddcontroller/v1bate1/types.go
package v1beta1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// Blog is a specification for a Blog resource
type Blog struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec BlogSpec `json:"spec"`
Status BlogStatus `json:"status"`
}
// BlogSpec is the spec for a Blog resource
type BlogSpec struct {
DeploymentName string `json:"deploymentName"`
Replicas *int32 `json:"replicas"`
Title string `json:"title"`
Author string `json:"author"`
Content string `json:"content"`
LastUpdate string `json:"lastUpdate"`
Prev string `json:"prev"`
Next string `json:"next"`
}
// BlogStatus is the status for a Blog resource
type BlogStatus struct {
AvailableReplicas int32 `json:"availableReplicas"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// BlogList is a list of Blog resources
type BlogList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata"`
Items []Blog `json:"items"`
}
代码生成器
修改 hack/update-codegen.sh,增加对 Blog 的代码生成命令(对 nsdddcontroller 包的代码生成)
在此之前你应该用 git 备份一下,并且准备代码生成器脚本或者二进制
code-generator❯ go mod vendor ❯ chmod +x vendor/k8s.io/code-generator/generate-groups.sh
echo "===> Generating genericdaemon code for Blog"
"${CODEGEN_PKG}"/generate-groups.sh "deepcopy,client,informer,lister" \
k8s.io/sample-controller/pkg/client_Blog \
k8s.io/sample-controller/pkg/apis \
nsdddcontroller:v1Bate1 \
--output-base "$(dirname "${BASH_SOURCE[0]}")/../../.." \
--go-header-file "${SCRIPT_ROOT}"/hack/boilerplate.go.txt
⚠️ 这里有个坑记录下,我用代码生成器生成的一直有问题,使用的是 GO111MODULE=on 模块。修改后的脚本如下:
获取 许可证头文件的变量和 获取包的路径:
SCRIPT_ROOT=$(dirname "${BASH_SOURCE[0]}")/..
CODEGEN_PKG=${CODEGEN_PKG:-$(cd "${SCRIPT_ROOT}"; ls -d -1 ./vendor/k8s.io/code-generator 2>/dev/null || echo ../code-generator)}
脚本将
SCRIPT_ROOT变量设置为脚本文件的目录名称,然后将CODEGEN_PKG变量设置为code-generator软件包的路径。如果未设置CODEGEN_PKG环境变量,则脚本会检查SCRIPT_ROOT路径的vendor目录中是否安装了code-generator软件包,并相应地设置CODEGEN_PKG变量。
❯ pwd
/root/workspaces/sample-controller
❯ vendor/k8s.io/code-generator/generate-groups.sh \
"deepcopy,client,informer,lister" \
k8s.io/sample-controller/pkg/generated_blog \
k8s.io/sample-controller/pkg/apis \
nsdddcontroller:v1Bate1 \
--output-base "/root/workspaces" \
--go-header-file "hack/boilerplate.go.txt"
写 controller
规范性的将 controller 放入到 pkg 中,而不是 rootfs,取名为 pkg/blog_controller.go
整个控制器逻辑都写出来会有些混乱,为了有助于理解,我们继承第一次阅读 controller.go 的时候的逻辑,再对 controller 进行一次深入阅读和编写。
Controller 结构体的定义:
// BlogController is the controller implementation for Blog resources
type BlogController struct {
// kubeclientset is a standard kubernetes clientset
kubeclientset kubernetes.Interface
// shidaclientset is a clientset for our own API group
nsdddclientset clientset.Interface
deploymentsLister appslisters.DeploymentLister
deploymentsSynced cache.InformerSynced
blogsLister listers.BlogLister
blogsSynced cache.InformerSynced
workqueue workqueue.RateLimitingInterface
recorder record.EventRecorder
}
这里定义了一些 Clientset,用来对 Kubernetes 的 API Server 进行交互,这里也定义了一些 Lister,用来获取 Kubernetes 的 API 的信息,在 Lister 中利用缓存也能减少对 API Server 的访问压力。
workqueue 和 Informer 共同完成 Kubernetes controller 的核心:调谐的步骤
继续,找到初始化 Controller 的地方(NewBlogController),这个逻辑作为入口供 main.go 初始化,所以和 Run() 用大写调用。
func NewBlogController(
kubeclientset kubernetes.Interface,
nsdddcclientset clientset.Interface,
deploymentInformer appsinformers.DeploymentInformer,
blogInformer informers.BlogInformer) *BlogController {
klog.V(4).Info("Creating event broadcaster")
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&typedcorev1.EventSinkImpl{Interface: kubeclientset.CoreV1().Events("")})
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: blogControllerAgentName})
controller := &BlogController{
kubeclientset: kubeclientset,
nsdddcclientset: nsdddcclientset,
deploymentsLister: deploymentInformer.Lister(),
deploymentsSynced: deploymentInformer.Informer().HasSynced,
blogsLister: blogInformer.Lister(),
blogsSynced: blogInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "Blogs"),
recorder: recorder,
}
klog.Info("Setting up event handlers")
blogInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.enqueueBlog,
UpdateFunc: func(old, new interface{}) {
controller.enqueueBlog(new)
},
})
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*appsv1.Deployment)
oldDepl := old.(*appsv1.Deployment)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
// Periodic resync will send update events for all known Deployments.
// Two different versions of the same Deployment will always have different RVs.
return
}
controller.handleObject(new)
},
DeleteFunc: controller.handleObject,
})
return controller
}
AddToScheme 用于向 runtime.Scheme 中添加新的 API 对象。runtime.Scheme 是一个存储 Kubernetes API 对象 Schema 的对象,用于跨 API 版本和 API 组共享类型信息。通过使用 AddToScheme 方法,您可以将自定义 API 对象添加到 runtime.Scheme 中,以便在 Kubernetes API 中使用自定义 API 对象。
Scheme 是一个用于存储 Kubernetes API 对象 Schema 的对象,它是 Kubernetes API 的一部分,用于跨 API 版本和 API 组共享类型信息。它允许注册和管理自定义 API 对象,并且还提供了一些辅助方法,例如序列化和反序列化 Kubernetes 对象。
我们知道了 Informer 是用于Informer 监视某些资源的对象,它会在资源发生变化时通知控制器。那么 定义的 HasSynced 是什么,我们可以看下定义:
HasSynced 是一个函数,用于检查 Informer 是否已经完成了资源的同步。当调用 Informer 的 HasSynced 函数时,如果所有监控的资源都已经同步完成,函数将返回 true。
AddEventHandler 是一个为 Informer 注册事件处理函数。
其他的定义部分:
展开代码块
/*
Copyright 2017 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package main
import (
"context"
"fmt"
"time"
appsv1 "k8s.io/api/apps/v1"
corev1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/api/errors"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime/schema"
utilruntime "k8s.io/apimachinery/pkg/util/runtime"
"k8s.io/apimachinery/pkg/util/wait"
appsinformers "k8s.io/client-go/informers/apps/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/kubernetes/scheme"
typedcorev1 "k8s.io/client-go/kubernetes/typed/core/v1"
appslisters "k8s.io/client-go/listers/apps/v1"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/record"
"k8s.io/client-go/util/workqueue"
"k8s.io/klog/v2"
nsdddv1beta1 "k8s.io/sample-controller/pkg/apis/nsdddcontroller/v1beta1"
clientset "k8s.io/sample-controller/pkg/generated_blog/clientset/versioned"
samplescheme "k8s.io/sample-controller/pkg/generated_blog/clientset/versioned/scheme"
informers "k8s.io/sample-controller/pkg/generated_blog/informers/externalversions/nsdddcontroller/v1beta1"
listers "k8s.io/sample-controller/pkg/generated_blog/listers/nsdddcontroller/v1beta1"
)
const blogControllerAgentName = "nsddd-controller"
const (
// BlogSuccessSynced is used as part of the Event 'reason' when a Blog is synced
BlogSuccessSynced = "Synced"
// BlogErrResourceExists is used as part of the Event 'reason' when a Blog fails
// to sync due to a Deployment of the same name already existing.
BlogErrResourceExists = "ErrResourceExists"
// BlogMessageResourceExists is the message used for Events when a resource
// fails to sync due to a Deployment already existing
BlogMessageResourceExists = "Resource %q already exists and is not managed by Blog"
// BlogMessageResourceSynced is the message used for an Event fired when a Blog
// is synced successfully
BlogMessageResourceSynced = "Blog synced successfully"
)
// BlogController is the controller implementation for Blog resources
type BlogController struct {
// kubeclientset is a standard kubernetes clientset
kubeclientset kubernetes.Interface
// nsdddclientset is a clientset for our own API group
nsdddclientset clientset.Interface
deploymentsLister appslisters.DeploymentLister
deploymentsSynced cache.InformerSynced
blogsLister listers.BlogLister
blogsSynced cache.InformerSynced
// workqueue is a rate limited work queue. This is used to queue work to be
// processed instead of performing it as soon as a change happens. This
// means we can ensure we only process a fixed amount of resources at a
// time, and makes it easy to ensure we are never processing the same item
// simultaneously in two different workers.
workqueue workqueue.RateLimitingInterface
// recorder is an event recorder for recording Event resources to the
// Kubernetes API.
recorder record.EventRecorder
}
// NewBlogController returns a new sample controller
func NewBlogController(
kubeclientset kubernetes.Interface,
nsdddclientset clientset.Interface,
deploymentInformer appsinformers.DeploymentInformer,
blogInformer informers.BlogInformer) *BlogController {
// Create event broadcaster
// Add sample-controller types to the default Kubernetes Scheme so Events can be
// logged for sample-controller types.
utilruntime.Must(samplescheme.AddToScheme(scheme.Scheme))
klog.V(4).Info("Creating event broadcaster")
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&typedcorev1.EventSinkImpl{Interface: kubeclientset.CoreV1().Events("")})
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: blogControllerAgentName})
controller := &BlogController{
kubeclientset: kubeclientset,
nsdddclientset: nsdddclientset,
deploymentsLister: deploymentInformer.Lister(),
deploymentsSynced: deploymentInformer.Informer().HasSynced,
blogsLister: blogInformer.Lister(),
blogsSynced: blogInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "Blogs"),
recorder: recorder,
}
klog.Info("Setting up event handlers")
// Set up an event handler for when Blog resources change
blogInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.enqueueBlog,
UpdateFunc: func(old, new interface{}) {
controller.enqueueBlog(new)
},
})
// Set up an event handler for when Deployment resources change. This
// handler will lookup the owner of the given Deployment, and if it is
// owned by a Blog resource will enqueue that Blog resource for
// processing. This way, we don't need to implement custom logic for
// handling Deployment resources. More info on this pattern:
// https://github.com/kubernetes/community/blob/8cafef897a22026d42f5e5bb3f104febe7e29830/contributors/devel/controllers.md
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*appsv1.Deployment)
oldDepl := old.(*appsv1.Deployment)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
// Periodic resync will send update events for all known Deployments.
// Two different versions of the same Deployment will always have different RVs.
return
}
controller.handleObject(new)
},
DeleteFunc: controller.handleObject,
})
return controller
}
// Run will set up the event handlers for types we are interested in, as well
// as syncing informer caches and starting workers. It will block until stopCh
// is closed, at which point it will shutdown the workqueue and wait for
// workers to finish processing their current work items.
func (c *BlogController) Run(threadiness int, stopCh <-chan struct{}) error {
defer utilruntime.HandleCrash()
defer c.workqueue.ShutDown()
// Start the informer factories to begin populating the informer caches
klog.Info("Starting Blog controller")
// Wait for the caches to be synced before starting workers
klog.Info("Waiting for informer caches to sync")
if ok := cache.WaitForCacheSync(stopCh, c.deploymentsSynced, c.blogsSynced); !ok {
return fmt.Errorf("failed to wait for caches to sync")
}
klog.Info("Starting workers")
// Launch two workers to process Blog resources
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
klog.Info("Started workers")
<-stopCh
klog.Info("Shutting down workers")
return nil
}
// runWorker is a long-running function that will continually call the
// processNextWorkItem function in order to read and process a message on the
// workqueue.
func (c *BlogController) runWorker() {
for c.processNextWorkItem() {
}
}
// processNextWorkItem will read a single work item off the workqueue and
// attempt to process it, by calling the syncHandler.
func (c *BlogController) processNextWorkItem() bool {
obj, shutdown := c.workqueue.Get()
if shutdown {
return false
}
// We wrap this block in a func so we can defer c.workqueue.Done.
err := func(obj interface{}) error {
// We call Done here so the workqueue knows we have finished
// processing this item. We also must remember to call Forget if we
// do not want this work item being re-queued. For example, we do
// not call Forget if a transient error occurs, instead the item is
// put back on the workqueue and attempted again after a back-off
// period.
defer c.workqueue.Done(obj)
var key string
var ok bool
// We expect strings to come off the workqueue. These are of the
// form namespace/name. We do this as the delayed nature of the
// workqueue means the items in the informer cache may actually be
// more up to date that when the item was initially put onto the
// workqueue.
if key, ok = obj.(string); !ok {
// As the item in the workqueue is actually invalid, we call
// Forget here else we'd go into a loop of attempting to
// process a work item that is invalid.
c.workqueue.Forget(obj)
utilruntime.HandleError(fmt.Errorf("expected string in workqueue but got %#v", obj))
return nil
}
// Run the syncHandler, passing it the namespace/name string of the
// Blog resource to be synced.
if err := c.syncHandler(key); err != nil {
// Put the item back on the workqueue to handle any transient errors.
c.workqueue.AddRateLimited(key)
return fmt.Errorf("error syncing '%s': %s, requeuing", key, err.Error())
}
// Finally, if no error occurs we Forget this item so it does not
// get queued again until another change happens.
c.workqueue.Forget(obj)
klog.Infof("Successfully synced '%s'", key)
return nil
}(obj)
if err != nil {
utilruntime.HandleError(err)
return true
}
return true
}
// syncHandler compares the actual state with the desired, and attempts to
// converge the two. It then updates the Status block of the Blog resource
// with the current status of the resource.
func (c *BlogController) syncHandler(key string) error {
// Convert the namespace/name string into a distinct namespace and name
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
utilruntime.HandleError(fmt.Errorf("invalid resource key: %s", key))
return nil
}
// Get the Blog resource with this namespace/name
blog, err := c.blogsLister.Blogs(namespace).Get(name)
if err != nil {
// The Blog resource may no longer exist, in which case we stop
// processing.
if errors.IsNotFound(err) {
utilruntime.HandleError(fmt.Errorf("blog '%s' in work queue no longer exists", key))
return nil
}
return err
}
deploymentName := blog.Spec.DeploymentName
if deploymentName == "" {
// We choose to absorb the error here as the worker would requeue the
// resource otherwise. Instead, the next time the resource is updated
// the resource will be queued again.
utilruntime.HandleError(fmt.Errorf("%s: deployment name must be specified", key))
return nil
}
// Get the deployment with the name specified in Blog.spec
deployment, err := c.deploymentsLister.Deployments(blog.Namespace).Get(deploymentName)
// If the resource doesn't exist, we'll create it
if errors.IsNotFound(err) {
deployment, err = c.kubeclientset.AppsV1().Deployments(blog.Namespace).Create(context.TODO(), newBlogDeployment(blog), metav1.CreateOptions{})
}
// If an error occurs during Get/Create, we'll requeue the item so we can
// attempt processing again later. This could have been caused by a
// temporary network failure, or any other transient reason.
if err != nil {
return err
}
// If the Deployment is not controlled by this Blog resource, we should log
// a warning to the event recorder and ret
if !metav1.IsControlledBy(deployment, blog) {
msg := fmt.Sprintf(BlogMessageResourceExists, deployment.Name)
c.recorder.Event(blog, corev1.EventTypeWarning, BlogErrResourceExists, msg)
return fmt.Errorf(msg)
}
// If this number of the replicas on the Blog resource is specified, and the
// number does not equal the current desired replicas on the Deployment, we
// should update the Deployment resource.
if blog.Spec.Replicas != nil && *blog.Spec.Replicas != *deployment.Spec.Replicas {
klog.V(4).Infof("Blog %s replicas: %d, deployment replicas: %d", name, *blog.Spec.Replicas, *deployment.Spec.Replicas)
deployment, err = c.kubeclientset.AppsV1().Deployments(blog.Namespace).Update(context.TODO(), newBlogDeployment(blog), metav1.UpdateOptions{})
}
// If an error occurs during Update, we'll requeue the item so we can
// attempt processing again later. THis could have been caused by a
// temporary network failure, or any other transient reason.
if err != nil {
return err
}
// Finally, we update the status block of the Blog resource to reflect the
// current state of the world
err = c.updateBlogStatus(blog, deployment)
if err != nil {
return err
}
c.recorder.Event(blog, corev1.EventTypeNormal, BlogSuccessSynced, BlogMessageResourceSynced)
return nil
}
func (c *BlogController) updateBlogStatus(blog *nsdddv1beta1.Blog, deployment *appsv1.Deployment) error {
// NEVER modify objects from the store. It's a read-only, local cache.
// You can use DeepCopy() to make a deep copy of original object and modify this copy
// Or create a copy manually for better performance
blogCopy := blog.DeepCopy()
blogCopy.Status.AvailableReplicas = deployment.Status.AvailableReplicas
// If the CustomResourceSubresources feature gate is not enabled,
// we must use Update instead of UpdateStatus to update the Status block of the Blog resource.
// UpdateStatus will not allow changes to the Spec of the resource,
// which is ideal for ensuring nothing other than resource status has been updated.
_, err := c.nsdddclientset.ControllerV1beta1().Blogs(blog.Namespace).UpdateStatus(context.TODO(), blogCopy, metav1.UpdateOptions{})
return err
}
// enqueueBlog takes a Blog resource and converts it into a namespace/name
// string which is then put onto the work queue. This method should *not* be
// passed resources of any type other than Blog.
func (c *BlogController) enqueueBlog(obj interface{}) {
var key string
var err error
if key, err = cache.MetaNamespaceKeyFunc(obj); err != nil {
utilruntime.HandleError(err)
return
}
c.workqueue.AddRateLimited(key)
}
// handleObject will take any resource implementing metav1.Object and attempt
// to find the Blog resource that 'owns' it. It does this by looking at the
// objects metadata.ownerReferences field for an appropriate OwnerReference.
// It then enqueues that Blog resource to be processed. If the object does not
// have an appropriate OwnerReference, it will simply be skipped.
func (c *BlogController) handleObject(obj interface{}) {
var object metav1.Object
var ok bool
if object, ok = obj.(metav1.Object); !ok {
tombstone, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
utilruntime.HandleError(fmt.Errorf("error decoding object, invalid type"))
return
}
object, ok = tombstone.Obj.(metav1.Object)
if !ok {
utilruntime.HandleError(fmt.Errorf("error decoding object tombstone, invalid type"))
return
}
klog.V(4).Infof("Recovered deleted object '%s' from tombstone", object.GetName())
}
klog.V(4).Infof("Processing object: %s", object.GetName())
if ownerRef := metav1.GetControllerOf(object); ownerRef != nil {
// If this object is not owned by a Blog, we should not do anything more
// with it.
if ownerRef.Kind != "Blog" {
return
}
blog, err := c.blogsLister.Blogs(object.GetNamespace()).Get(ownerRef.Name)
if err != nil {
klog.V(4).Infof("ignoring orphaned object '%s' of blog '%s'", object.GetSelfLink(), ownerRef.Name)
return
}
c.enqueueBlog(blog)
return
}
}
// newBlogDeployment creates a new Deployment for a Blog resource. It also sets
// the appropriate OwnerReferences on the resource so handleObject can discover
// the Blog resource that 'owns' it.
func newBlogDeployment(blog *nsdddv1beta1.Blog) *appsv1.Deployment {
labels := map[string]string{
"app": "nginx",
"controller": blog.Name,
}
return &appsv1.Deployment{
ObjectMeta: metav1.ObjectMeta{
Name: blog.Spec.DeploymentName,
Namespace: blog.Namespace,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(blog, schema.GroupVersionKind{
Group: nsdddv1beta1.SchemeGroupVersion.Group,
Version: nsdddv1beta1.SchemeGroupVersion.Version,
Kind: "Blog",
}),
},
},
Spec: appsv1.DeploymentSpec{
Replicas: blog.Spec.Replicas,
Selector: &metav1.LabelSelector{
MatchLabels: labels,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: labels,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: "nginx",
Image: "nginx:latest",
},
},
},
},
},
}
}
启动控制器
最后,在 pkg/main.go 里创建我们的 Blog Controller,并启动控制器
/*
Copyright 2017 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package main
import (
"flag"
"time"
kubeinformers "k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/klog/v2"
// Uncomment the following line to load the gcp plugin (only required to authenticate against GKE clusters).
// _ "k8s.io/client-go/plugin/pkg/client/auth/gcp"
clientset "k8s.io/sample-controller/pkg/generated/clientset/versioned"
informers "k8s.io/sample-controller/pkg/generated/informers/externalversions"
blogclientset "k8s.io/sample-controller/pkg/generated_blog/clientset/versioned"
bloginformers "k8s.io/sample-controller/pkg/generated_blog/informers/externalversions"
"k8s.io/sample-controller/pkg/signals"
)
var (
masterURL string
kubeconfig string
)
func main() {
flag.Parse()
// set up signals so we handle the shutdown signal gracefully
ctx := signals.SetupSignalHandler()
logger := klog.FromContext(ctx)
cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig)
if err != nil {
logger.Error(err, "Error building kubeconfig")
klog.Fatalf("Error building kubeconfig: %s", err.Error())
}
kubeClient, err := kubernetes.NewForConfig(cfg)
if err != nil {
logger.Error(err, "Error building kubernetes clientset")
klog.Fatalf("Error building kubernetes clientset: %s", err.Error())
}
exampleClient, err := clientset.NewForConfig(cfg)
if err != nil {
logger.Error(err, "Error building exampleClient is clientset")
klog.Fatalf("Error building example clientset: %s", err.Error())
}
blogClient, err := blogclientset.NewForConfig(cfg)
if err != nil {
logger.Error(err, "Error building blogClient is clientset")
klog.Fatalf("Error building blog clientset: %s", err.Error())
}
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
exampleInformerFactory := informers.NewSharedInformerFactory(exampleClient, time.Second*30)
blogInformerFactory := bloginformers.NewSharedInformerFactory(blogClient, time.Second*30)
blogController := NewBlogController(kubeClient, blogClient,
kubeInformerFactory.Apps().V1().Deployments(),
blogInformerFactory.Controller().V1beta1().Blogs())
// notice that there is no need to run Start methods in a separate goroutine. (i.e. go kubeInformerFactory.Start(ctx.Done())
// Start method is non-blocking and runs all registered informers in a dedicated goroutine.
kubeInformerFactory.Start(ctx.Done())
exampleInformerFactory.Start(ctx.Done())
blogInformerFactory.Start(ctx.Done())
go func() {
err = blogController.Run(2, ctx.Done())
if err != nil {
klog.Fatalf("Error running controller: %s", err.Error())
}
}()
if err = blogController.Run(2, ctx.Done()); err != nil {
klog.Fatalf("Error running controller: %s", err.Error())
}
}
func init() {
flag.StringVar(&kubeconfig, "kubeconfig", "", "Path to a kubeconfig. Only required if out-of-cluster.")
flag.StringVar(&masterURL, "master", "", "The address of the Kubernetes API server. Overrides any value in kubeconfig. Only required if out-of-cluster.")
}
验证
重新编译 sample-controller 项目,并运行 sample-controller CRD 控制器
# assumes you have a working kubeconfig, not required if operating in-cluster
go build -o sample-controller .
./sample-controller -kubeconfig=$HOME/.kube/config
# create a CustomResourceDefinition
kubectl create -f artifacts/examples/crd-status-subresource.yaml
# create a custom resource of type Foo
kubectl create -f artifacts/examples/example-foo.yaml
# check deployments created through the custom resource
kubectl get deployments
使用 Kubebuilder 构建
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©
关于CRD有一些链接:
- 官方文档:https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/
- 官方解释:https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/#create-a-customresourcedefinition
- CRD Yaml的Schema:https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.13/#customresourcedefinition-v1beta1-apiextensions-k8s-io
- https://kubernetes.feisky.xyz/cha-jian-kuo-zhan/api/customresourcedefinition
- https://book.kubebuilder.io/
- kubernetes write controller
- 书籍:《Kubernetes Operator 开发进阶 - 胡涛》 但不推荐购买~
这篇文章参考的博客连接: