第47节 Kubernetes 概念以及架构
❤️💕💕新时代拥抱云原生,云原生具有环境统一、按需付费、即开即用、稳定性强特点。Myblog:http://nsddd.top
[TOC]
前言
云计算: 参考上一节学习:云计算是对所有 存储资源、网络资源、计算资源的抽象
控制平面将大量的节点抽象出来:
- 谁能参与计算
- 共有多少 CPU
- 共有多少内存
- 业务不需要在乎我的程序跑在哪个节点
过去这段时间里,作业管理平台主要是2个方向:
以Openstack为典型的虚拟化平台:
这种虚拟化平台可以认为是在很多台物理机上都安装Hypervisor,在Hypervisor上启动很多个虚拟机,再把这些虚拟机组成一个大的云平台。
最终交付的产品形态:一个个的OS。在这个OS上去部署应用因此后续工作(应用部署、应用升级、应用管理)与底层的基础云平台有着相对比较明显的界限:
- IaaS:Infrastructure as a Service
- PaaS:Platform as a Service
- SaaS:Software as a Service
虚拟机构建和业务代码部署是分离的.这种可变的基础架构使后续维护风险变大。
以谷歌Borg为典型的基于进程的作业调度平台:
google 走的是另一条路,事实证明现在是对的。
谷歌Borg云计算平台
[[Borg]]是Google内部用于管理公司内部所有作业的一个作业管理平台。Kubernetes的前身即为Borg。
Borg is a cluster manager used by Google.[1][2] It led to widespread use of similar approaches such as Docker and Kubernetes.[3]
Borg并没有使用虚拟化技术。它的主要实现方式是使用轻量级的作业调度。也就是说Borg调度的是进程。
如果你的兴趣强烈,或许你可以看看 Google 在 2015 年发表的 Borg 论文:
- https://research.google/pubs/pub43438
Borg本身利用了一些容器技术:
- Cgroup技术就是Google开源给Linux的
- Namespace的前身:
chroot和jail但这也带来了一些缺点:- 对象之间的强依赖job和task是强包含关系,不利于重组
- 所有容器共享IP,会导致端口冲突,隔离困难等问题
- 为超级用户添加复杂逻辑,导致系统过于复杂
Borg主要支持的业务
主要支持的业务:
- Production Workload(生产业务):这类业务包括Gmail、Google Docs、Web Search等服务
- Non-prod Workload(离线作业):比如AI方向、大数据方向的批处理作业
Production Workload 和 Non-prod Workload的区别:
- Production Workload 要求高可用,要求永远在线。它对资源的开销可能并不是特别大,也不是大量地消耗计算资源的服务(除非负载特别高,但负载一般也是有波峰波谷的,不是一直高负载的)
- Non-prod Workload 一般用于批处理作业。对资源开销的要求会比较高(比如启动一个AI训练时,会疯狂的吃CPU/GPU)。但Non-prod Workload对可用性的要求比Production Workload低。更直观的说,当你发起一个批处理作业时,你不能要求该作业马上返回结果,因为这个批处理作业本身需要时间(有可能是几分钟,几小时,几天甚至几个月)。对于Non-prod Workload的时效性要求较低。
Google通过把在线业务和离线业务混合部署的方式,使得整个数据中心的资源利用率有了一个本质提升。
Borg 提供三个好处:
- 向用户隐藏资源管理和故障处理的细节,用户只需专注于应用程序开发
- 高可靠性和高可用性的操作,同时支持应用程序相关特性
- 有效的在数以万计的机器上运行工作负载
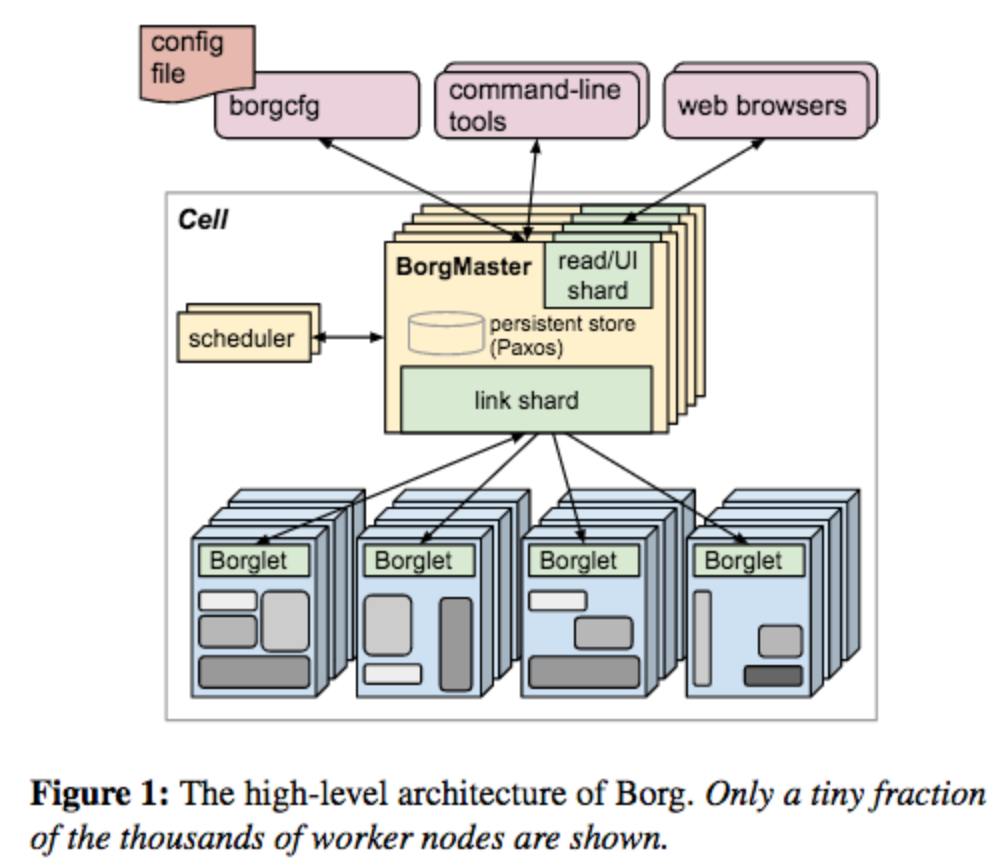
概念
Borg 的面向用户为运行 Google 应用程序和服务的 Google 开发者和系统管理员(Google 内部称为网站高可用工程师或者简写 SRE)。用户向 Borg 以作业( jobs )的方式提交工作,每个 job 由包含着相同程序的一个或多个任务( tasks )组成。每个 job 运行在一个 Borg cell (一组机器集合管理单元) 上。
The workload
Borg cells 包括两种类型的 workload。第一种是那些长时间运行的服务,并且对请求延迟敏感(几微秒到几百毫秒之间)。这类服务一般是直接面向终端用户的产品,如 Gmail、Google Docs 和 Web 搜索以及内部基础设施服务(如 BigTable)。另外一种是那些运行几秒或者几天即可完成的批处理作业,这类服务对短期性能波动不敏感。
一个典型的 cell,一般分配 70% CPU 资源,实际使用为 60%,分配 55% 的内存资源,实际使用为 85%。
Clusters and cells
1个Cell上跑1个集群管理系统Borg
我理解Cell就是Kubernetes中的Cluster。
通过定义Cell可以让Borg对服务器资源进行统一抽象,作为用户就无需知道自己的应用跑在哪台机器上,也不用关心资源分配、程序安装、依赖管理、健康检查及故障恢复等
一个 cell 的机器都归属于单个集群,通过高性能的数据中心级别的光纤网络连接。一个集群部署在一个独立的数据中心建筑中,多个数据中心建筑构成一个 site 。一个集群通常包括一个大规模的 cell 和许多小规模的测试或者特殊目的的 cells。尽量避免单点故障。
排除测试 cells,一个中等规模的 cell 一般由 10k 机器组成。一个 cell 中的机器规格是不同的,诸如配置(CPU、RAM、磁盘、网络),处理器型号,性能等方面。用户无需关心这些差异,Borg 确定在哪个 cell 上运行任务,分配资源,安装程序和依赖项,并监控应用运行状况以及在运行失败时重启。
Jobs and tasks
Task即为进程。多个Task组成1个Job。
我理解Job就是Kubernetes中的Pod;Task就是Kubernetes中的Container
一个 Borg job 的属性包括名字、属主以及 tasks 数量。通过一些约束,可以强制 Job 的 tasks 在具有特定属性的机器上运行,例如处理器架构、操作系统版本,或者额外的 IP 地址。约束是分软限制和强限制。可以指定 job 运行顺序,如一个 job 在另外一个 job 运行之后再启动。一个 job 只能运行在一个 cell 上。
每个 task 映射成一组 Linux 进程运行在一台机器的一个容器中。大部分的 Borg workload 都不是运行在虚拟机中,不想在虚拟化上花费精力是一方面。另外,设计 Borg 的时候还没有出现硬件虚拟化。task 也有拥有属性,例如资源需求等。大多数的 task 属性同它们的 job 一样,不过也可以被覆盖。如提供 task 专用的命令行参数,以及 CPU、内存、磁盘空间、磁盘 IO 大小、TCP 端口等都可以分配设置。用户通过 RPC 与 Borg 交互来操作 job,大多数是通过命令行工具完成的,其它的则通过监控系统。大部分 job 描述文件是用声明式配置语言 BCL (GCL 变体) 编写的。

用户可以修改一个运行中的 job 属性值并发布到 Borg,然后 Borg 按照新的 job 配置来更新 tasks。更新通常是以滚动方式完成,并且可以对更新导致的任务中断(重新调度或者抢占)的数量进行限制,任何导致更多中断的更改都会被跳过。
tasks 需要能够处理 Unix SIGTERM 信号, 以便在被强制发送 SIGKILL 之前,可以有时间进行清理,保存状态,完成当前执行请求,拒绝新的请求。在实践中,规定时间有 80% 的可以正常处理信号。
Allocs(allocation)
Borg alloc 是可以运行在一个或多个 tasks 的机器上的一组预留资源。无论资源是否使用,资源仍分配。Allocs 可以被用于将来的 tasks 资源使用,在停止和启动 task 之间保留资源,并且可以将不同 jobs 的 tasks 聚集到同一台机器上。一个 alloc 的资源和机器上资源类似的方式处理,多个 tasks 运行在 alloc 上是共享资源的,如果一个 alloc 必须重新分配到另外一台主机,它的 tasks 也会同它一起重新被调度。
一个 alloc 集合和 job 很像,它是一组分配在多台机器上的预留资源。一旦创建一个 alloc 集合,就可以提交一个或多个 jobs 运行在其中。为简洁起见,通常使用 "task" 引用 alloc 或者一个顶级的 task(alloc 之外的 task) 和 "job" 来引用一个 job 或者 alloc 集合。
Priority, quota, and adminssion control
优先级和配额用于防止运行的比实际能容纳多的这种负载情况。每个 job 都有一个 priority 优先级,一个小的正整数。高优先级的 task 可以在牺牲较低优先级的 task 来获取资源,甚至是以抢占方式。 Borg 为不同用途定义不同的优先级:监控、生产、批处理和 best effort。
针对生产级别的 jobs 是禁止 task 互相抢占的。优先级决定 jobs 在 cell 中处于运行还是等待状态。 Quota 配额被用于确定调度哪些 jobs。配额表示为一段时间内(通常为几个月)给定优先级的资源量(CPU、RAM、磁盘等)。这些值指定了用户的 job 在请求时间段内可以使用的最大资源量。配额检查是准入控制的一部分,配额不足情况下,job 会被拒绝调度。
高优先级的配额成本比低优先级要高。生产级别的配额仅限于 cell 中实际可用资源,因此用户提交满足生产级别 job 运行预期的资源配额。虽然不建议用户配置超买,但是很多用户都会比实际的需要配额要大,以防止后续用户增长可能造成的资源短缺。对于超买,应对方案就是超卖。
配额分配的使用在 Borg 之外进行处理,和物理容量设计密切相关,结果反映在不同数据中心的配额价格和可用性上。Borg 通过 capability 系统,给予某些用户特殊权限,如允许管理员删除或者修改任意 cell 中的 job,或者运行用户访问受限的内核功能或者 Borg 操作,如禁用其 jobs 预算。
Naming and monitoring
Borg的服务发现通过BNS(Borg Name Service)来实现。
例: 50.jfoo.ubar.cc.borg.google.com
cc: 表示Cell名ubar: 表示用户名jfoo: 表示Job名50: 表示当前服务是Job中的第几个Task
我理解Naming就是Kubernetes中的Service。
在Borg上运行的每一个服务,都可以通过Naming服务来暴露其域名,以便集群外部的流量来访问该服务。在微服务架构下,Micro Service A和Micro Service B之间,就可以通过这种Naming Service来完成微服务之间的调用。
综上所述,Borg其实隐含了3层含义:
- 集群(计算资源)管理的概念。需要把多台机器组成一个集群(Cell),然后交给Borg的控制平面去管理
- 作业的描述和调度的概念。因此Borg是一个作业调度平台
- 服务发现的概念。Naming的存在是为了解决微服务之间的调用问题,因此Borg是一个服务发现平台
只是提供创建和运行是不够的,服务客户端和相关系统需要能够访问到对应的服务,即使被重新调度到新的机器上。因此,Borg 针对每个 task 创建一个稳定的 "Borg name service" (BNS),包括 cell 名,job 名和 task 数量。Borg 用这个名字将 task 的主机名和端口写入到 Chubby 一致且高可用的文件中,该文件用于 RPC 系统查找 task 端。BNS 名也用于 task DNS 名构成基础,如用户 ubar 在 cell cc 上执行的 job jfoo 第 50 个 task,可以通过 50.jfoo.ubar.cc.borg.google.com 访问。Borg 还会在发生变化的时候把 job 大小和 task 健康信息写入到 Chubby,以使得负载均衡器可以获取到请求路由指向。
几乎所有运行在 Borg 上的 task 都包含一个内建的 HTTP server,用于发布 task 的健康信息和数千个性能指标(如 RPC 延迟)。Borg 监控健康检测 URL 并且在 tasks 无响应或者返回错误的 HTTP 码时重启。其它的数据会被监控工具追踪展示在 Dashboards 上并且在服务级别(SLO)问题时告警。
用户可以通过一个名叫 Sigma 提供的 Web 用户界面上,检查 jobs 的状态,查看特定的 cell,或者深入查看各个 jobs 和 tasks,检测它们的资源占用,详细的日志和执行历史,以及最终的宿命。应用程序会产生大量的日志,通过日志轮转避免磁盘空间不足,并且在任务退出后保留一段时间以协助进行调试。如果一项工作没有运行,Borg 会提供一个 "有待处理的" 注释,以及如何修改 job 资源请求用以更好的适配 cell。
Borg 记录所有 job 提交和 task 事件,详细到每个 task 资源使用信息记录在基础设施存储。这是一个可伸缩的只读数据存储,并且由 Dremel(Google 交互式数据分析系统)提供类 SQL 方式进行交互。数据被用于计费,调试 job 和系统故障以及长期的容量规划。它也提供 Google 集群工作负载跟踪数据。
所有的这些特性帮助用户理解和调试 Borg 以及他们的 jobs,并且帮助我们的 SREs 每人管理数万台主机。
应用高可用
高可用是在线业务的命。如果一个应用失去了高可用性,那它就完全没有办法提供稳定的在线服务,这个后果是不可承受的。现在人们之所以用Kubernetes平台,就是因为它对高可用的场景做了很丰富的支持。
被抢占的non-prod任务放回pending queue,等待重新调度
在线业务应该永远保证其高可用,这是第一目标。因此当在线业务对资源有需求时,这种需求应该优先保证。所以Borg在这方面做了一些事情: 当在线业务有资源需求时(例如要部署一个在线业务,或者要扩容一个在线业务),Borg就会为这个在线业务做调度。 假设调度时,集群中已经没有可用资源了,Borg会去杀离线业务。也就是把离线业务的资源抢过来给在线业务,让在线业务先跑。
但是离线业务也没有直接丢弃,而是把这个离线业务放回pending queue中,等到有资源时再重新跑。
这样既保证了在线业务的高可用,又保证了离线业务的作业不会丢失,不会处于异常状态。
多副本应用跨故障域部署。所谓故障域有大有小,比如相同机器、相同机架或者相同电源插座等,一挂全挂
Borg 提供了一些能力,来支持跨地域的、跨故障域的部署。高可用往往通过冗余部署来实现。
举个例子,常态下1个服务只有1个副本。当这个副本出现故障时,就意味着这个服务不可用了。想要保持这个服务高可用,多部署几份,在这几份前面配个负载均衡即可。
10万台机器,如果被分成10个Cell,那就是10个集群,每个集群1万个节点。这样的话就把整个数据中心切割成了不同的故障域。假设其中1个Cell出现故障,其他Cell不受影响
假设所有的冗余都部署在了同一台机器上,那么当这台机器出现故障时,冗余部署就失去了意义。因此Borg提供了一个 跨故障域(包括跨节点、跨机架、跨可用区、跨数据中心等)的多副本部署能力。
对于类似服务器或操作系统升级的维护操作,避免大量服务器同时进行
支持幂等性,支持客户端重复操作。
幂等: 针对一个程序,给定其同样的输入,让该程序运行N次,该程序返回的N个结果是一样的,则称该程序是幂等的; 若返回结果不同,则该程序就不是幂等的。
解决幂等的方式就是声明式,让机器自己去找最优解(去重)。
那如何保证幂等:
- 要有一个用于处理输入的逻辑
- 输入尽可能是一个声明式的输入。所谓声明式的输入,指的是尽可能地声明它是什么,而非输入指令、动作。因为指令、动作有可能不是幂等的
Borg支持声明式的输入。 例如: 声明一个作业,声明时定义好该作业需要的资源、要运行的应用等信息。那么这样的一个声明式指令无论发送多少次,其最终执行的结果都是一样的。
当服务器状态变为不可用时,要控制重新调度任务的速率。因为Borg无法区分是节点故障还是出现了短暂的网络分区。如果是网络分区,则等待网络恢复更利于保障服务的可用性
当某种 任务@服务器 的组合出现故障时,下次重新调度时,避免这种组合再次出现,因为极大可能会再次出现相同的故障
记录详细的内部信息,便于故障排查和分析
保障应用高可用的关键性设计原则: 无论何种原因,即使Borgmaster或者Borglet挂掉、失联,都不能杀掉正在运行的服务(Task)
Borg系统自身高可用
Borgmaster组件多副本设计
Borgmaster组件多副本是为了保障Borg自身的高可用。无论是数据存储的高可用,还是Borgmaster这个控制平面的高可用,Borg都要保证。
采用一些简单和底层(low-level)的工具来部署Borg系统实例,避免引入过多的外部依赖
每个
Cell的Borg均独立部署,避免不同Borg系统相互影响每个Cell独立部署,这样保证了整个数据中心的高可用。1个Cell坏了其他的Cell还活着,这样故障的Cell就成为了一个局部的故障。这个故障也只影响到了坏掉的Cell所管理的节点。换言之就是通过Cell将整个数据中心划分成了不同的故障域
资源利用率
通过将在线任务(prod)和离线任务(non-prod Batch)混合部署:
- 空闲时离线任务可以充分利用计算资源
- 繁忙时在线任务通过抢占的方式保证优先得到执行,合理地利用资源(我理解的是 Kubernetes 的调度)
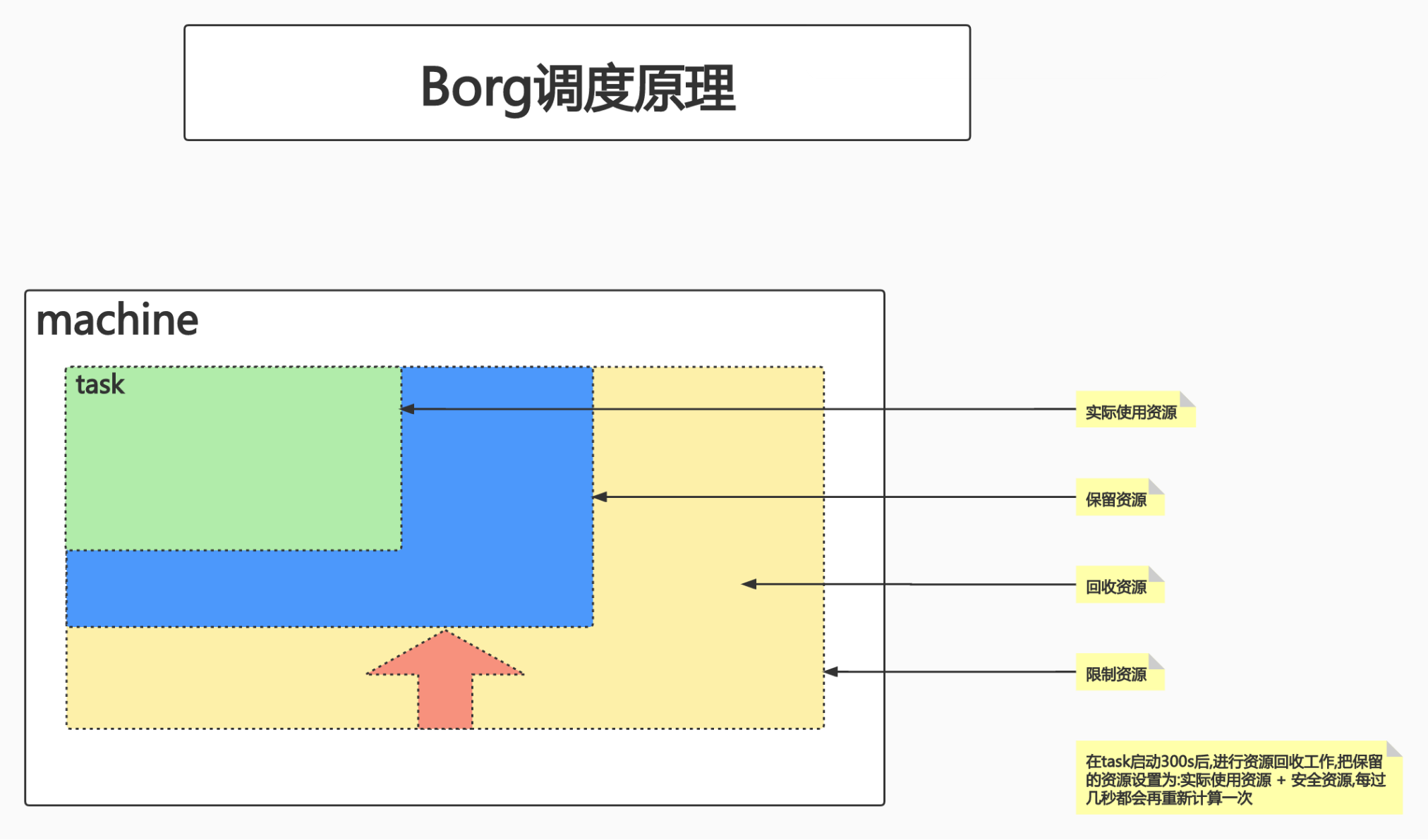
Borg的调度原理
很多人用云平台,都会有一个理想化的、先入为主的需求。比如一个业务开发人员,他的主要目标除了写好业务逻辑外,根本的核心需求就是业务的高可用。
想要达到这个目标,
- 第一:代码要足够健壮
- 第二,要为服务预留足够的资源。至于到底预留多少才算是预留了"足够"的资源,这就是一个可以深入讨论的点了。
一般的做法可以先做个压测。先限网,TPS(Transactions Per Second,每秒传输的事务处理个数,即服务器每秒处理的事务数)为10,压测100次,查看资源的使用情况。那么这个资源使用情况就已经是基于10倍的请求量得出的结果了。
之后在申请资源时,按照这个结果申请资源。因为业务高峰期时要保证资源是足够的,所以开发人员都会尽可能多地去申请资源。多申请资源就会多占用资源,但常态下业务又达不到很高的资源利用率,最终很有可能的结果是:90%的资源都浪费掉了。
Borg实现了一种机制:允许用户申请资源,但是在任务启动后会不停地监控作业,确认作业真正使用的资源数量。如果Borg发现作业用到的资源远远小于申请时的资源,就会进行回收。
保留的资源数量 = (1 + 阈值) * 作业真实使用的资源
将剩余的部分(即申请的资源数量 - 保留的资源数量)全都回收掉。这样就有效提升了整个集群的资源利用率。
换言之,用户可以声明很多的资源,但是当用户提交的作业达不到一定的利用率时,Borg会把用户声明的资源中的一部分回收走,交给其他作业使用。这样整个集群的资源利用率就提高了。
隔离性
安全性隔离:
早期使用
chroot、jail,后期版本基于Namespace早期的iPhone越狱,其实就是
chroot和jail
性能隔离:
采用基于Cgroup的容器技术实现
在线任务(prod)是延时敏感(latency-sensitive)型的,优先级高,而离线任务(non-prod、Batch)优先级低。(确定了调度策略)
Borg通过不同优先级之间的抢占式调度来优先保障在线任务的性能,牺牲离线任务。
Borg将资源分成两类:
compressible: 可压榨的,CPU是可压榨资源,资源耗尽不会导致进程终止CPU是一个分时复用的资源,对于一个给定型号的CPU,它的CPU时间片数量是固定的。CPU时间片按照调度器的策略分配,每个进程最终都会分到一些时间片。当竞争较大的时候,所有进程都按照预先分配的比率,少分配一些时间片。这样的结果是: 进程的性能会慢一些,但整个程序不会退出。
non-compressible: 不可压榨的,内存是不可压榨资源,资源耗尽会导致进程被终止1台机器的内存大小是固定的(此处假设主板上所有的内存槽都插满了),如果所有进程都在疯狂占用内存,那最终的结果只能是: 没有可以分配的内存了。磁盘也属于不可压榨资源。不可压榨资源在利用率上一旦到达了边界,OS就只能终止进程。
什么是 Kubernetes
Kubernetes是谷歌开源的容器集群管理系统,是谷歌多年大规模容器管理技术Borg的开源版本,主要功能包括:
- 基于容器的应用部署、维护和滚动升级
- 负载均衡和服务发现
- 跨机器和跨地区的集群调度
- 自动伸缩
- 无状态服务 和 有状态服务
- 插件机制保证扩展性
⚠️ 深入剖析 Kubernetes 书中,我们知道 有状态应用部署要求很高。
无状态应用可以有相同的解决方案,但是有状态应用应该提前部署和设计,并且专业的人去维护。
Kubernetes 大部分都是无状态应用。因为有状态应用可能需要领域专家去维护和设计,成本很高。
Kubernetes 概念
Kunbernetes遵循了声明式系统的原则。Kunbernetes是构建与声明式系统之上的一个云管理平台。Kunbernetes中所有代管的对象(计算节点、服务、作业等)全部抽象成了标准API。这之后,就把这些API作为统一的规范,和一些大厂联合背书,让大家都遵循同样的规则下场玩游戏。这样一来,这套API就成了事实标准。这意味着所有下场玩游戏的玩家,都只能向这套标准靠拢。把目光看向未来,标准已然存在,标准可以演进,但标准很难被取代。取代一个已存在的标准,这件事可以称之为"革命"。
命令式(Imperative) VS 声明式(Declarative)
最最最熟悉的莫过于 命令式:
在软件工程领域,命令式系统是写出解决某个问题、完成某个任务或者达到某个目标的明确步骤。此方法明确写出系统应该执行某指令,并且期待系统返回期望结果
命令式系统通常是微管理的系统,因为要随时观察目标的变化。发一条指令给目标,让目标按照指令去做。目标按照指令做完了之后再返回,之后再发下一条指令给目标,以此类推。
这种系统的特性是返回较快。可以基于上一次返回的结果判断下一次做出何种指示。
声明式系统该做什么
在软件工程领域,声明式系统指程序代码描述系统应该做什么而不是怎么做。 仅限于描述要达成什么目的,至于如何达成这个目的,交给系统解决
声明式系统中间有一个运转的过程。调用者(用户)只能告知系统自己想要达到的目标,对于中间执行的过程,调用者不加干涉。
声明式系统规范
命令式:
- 我要你做什么,怎么做,请严格按照我说的做
声明式:
- 我需要你帮我做点事,但是我只告诉你我需要你做什么,而非你应该如何做
- 直接声明: 我直接告诉你我需要什么
- 间接声明: 我不直接告诉你我的需求,我会把我的需求放在特定的地方,请在方便的时候拿出来处理
幂等性:
- 状态固定,每次我要你做的事,请给我返回相同的结果
面向对象的:
- 把一切抽象成对象
声明式系统适用于微服务架构。很多时候调用者发送一个请求给Server端时,调用者是不知道一个Server端到底要针对这个请求处理多久的。如果按照交互式的系统,那么客户端就阻塞在发送请求之后了。整个系统的并发能力就会很差。
Kubernetes 架构
我们回过头看 Kubernetes 和 Borg 类似的架构:
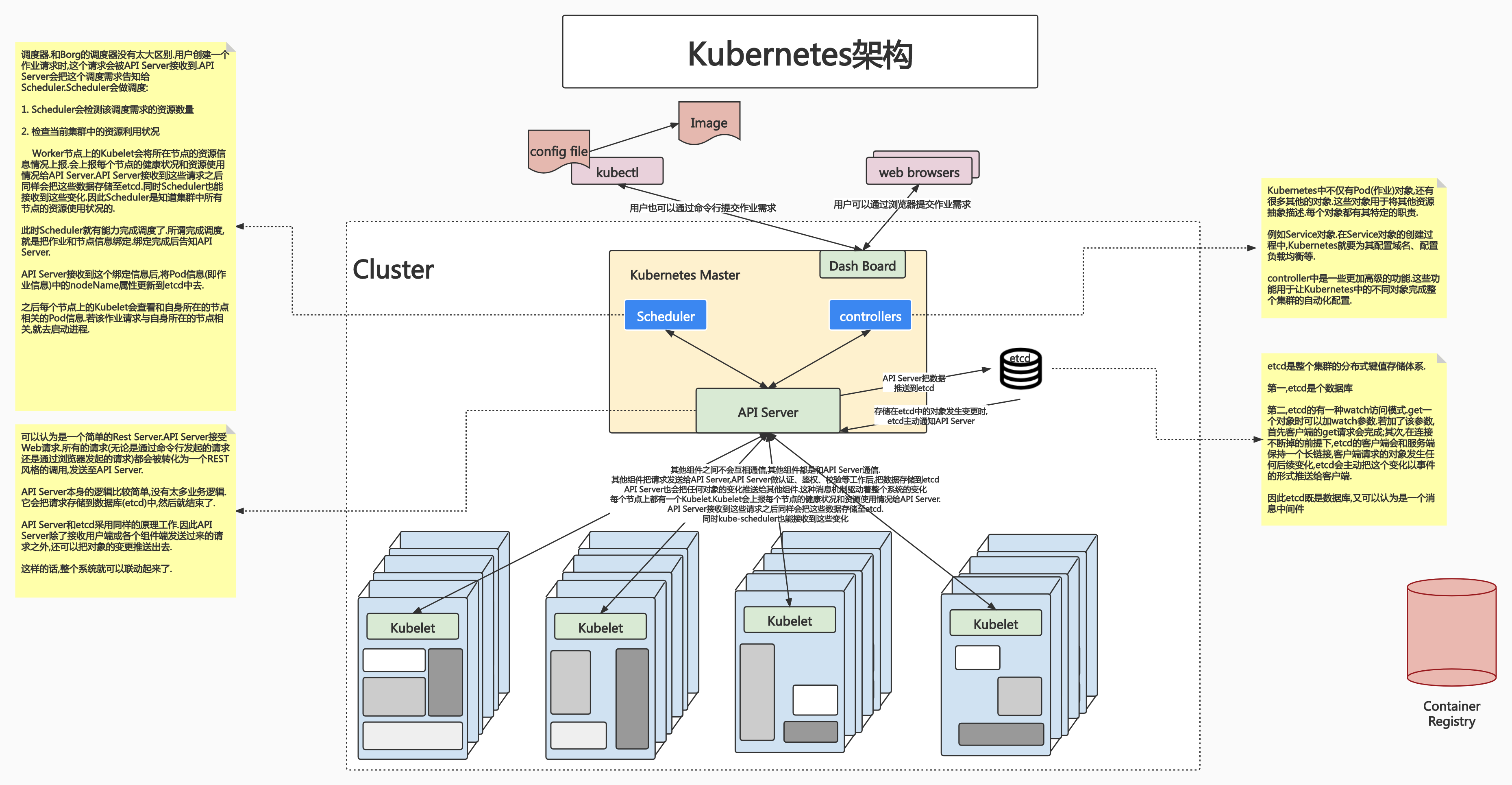
Kubernetes 的主节点
和Borg一样,假设集群中有5000个节点,选2~3台节点作为管理节点即可。管理节点上运行的就是控制平面的组件。
etcd 基于 raft 算法,保证最优 3 个节点,并且是 奇数节点
etcd是CoreOS基于Raft开发的分布式key-value存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)
- 基本的key-value存储
- 监听机制
- key的过期以及续约机制,用于监控和服务发现
- 原子CAS和CAD,用于分布式锁和leader选举
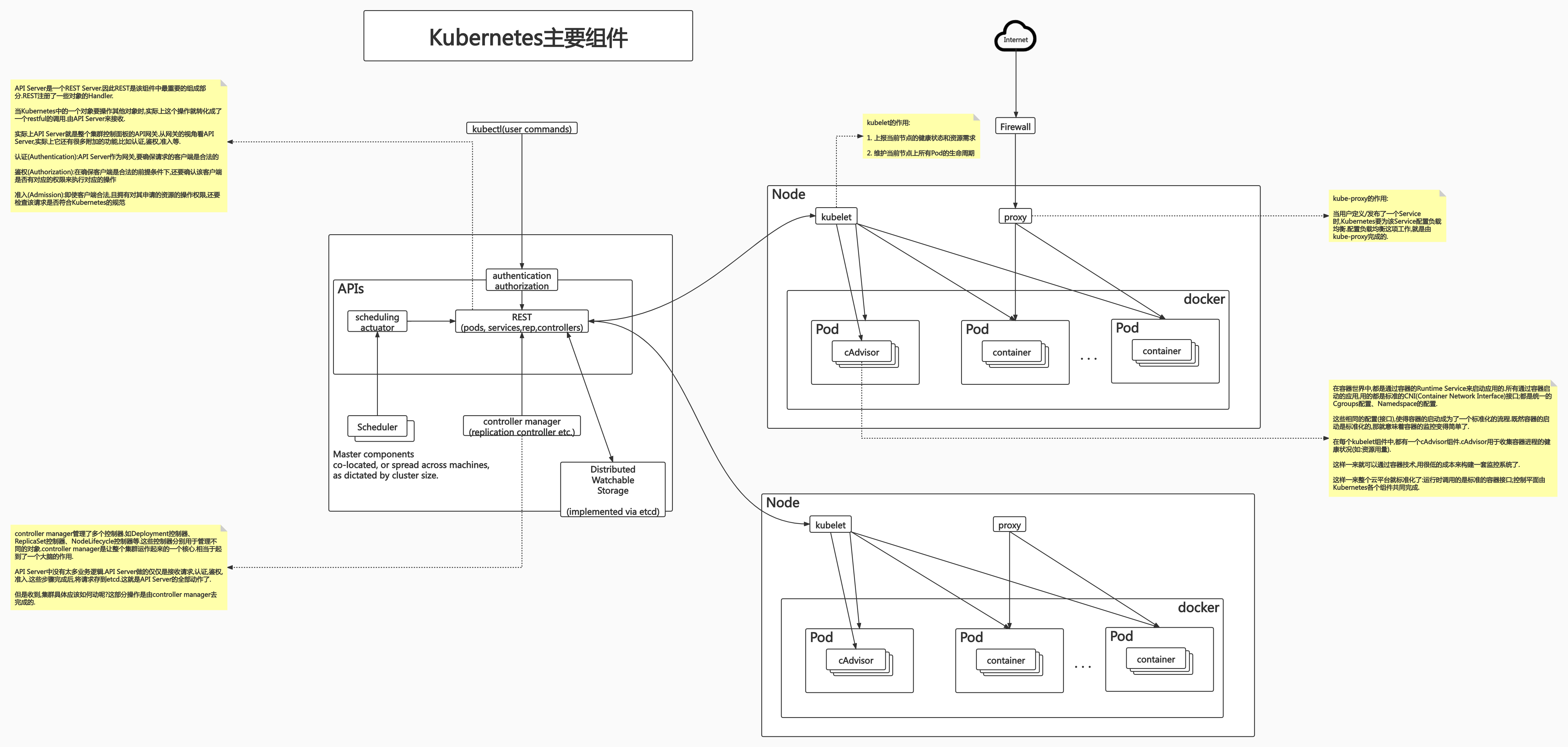
API Server(API服务器)
这是Kubernetes控制面板中唯一带有用户可访问API以及用户可交互的组件。API Server会暴露一个RESTful的Kubernetes API并使用JSON格式的清单文件(manifest files)
Cluster Data Store(集群的数据存储)
Kubernetes使用etcd存储数据。这是一个强大的、稳定的、高可用的键值存储,被Kubernetes用于长久储存所有的API对象
Scheduler(调度器)
调度器会监控新建的pods(一组或一个容器)并将其分配给节点
其实Scheduler和Controller没有本质区别,只是它专职做调度。
Kubernetes 工作节点
kubelet
负责调度到对应节点的Pod的生命周期管理,执行任务并将Pod状态报告给主节点的渠道,通过容器运行时(拉取镜像、启动和停止容器等)来运行这些容器。它还会定期执行被请求的容器的健康探测程序
kube-proxy
负责节点的网络,在主机上维护网络规则并执行连接转发。它还负责对正在服务的pods进行负载均衡。
不管是 master 节点,或者是 worker 节点,每一个组件都是非常非常复杂的。
ETCD
ETCD 的学习笔记,之前做的比较全面了,直接参考 这一篇笔记~
API Server
Kube-APIServer是Kubernetes最重要的核心组件之一。API Server本身是一个REST Server,因此它的扩展比较简单。
和etcd不同。etcd是一个有状态应用的集群。对于这种有状态应用,加减member或替换member还是有些复杂的。 像etcd就需要花一些时间做配置。因为在有状态应用的集群中,每一个member都是有意义的。比如向集群(假设此时集群中有n个member)中添加一个member,那么所有member的协商对象就会发生改变。原来有n个memeber参与协商,添加后有n+1个member参与,所以etcd要去更改所有memeber的协商对象,修改协商对象的一些配置文件。
但对于像API Server这种无状态应用的集群,横向扩展比较简单。
提供集群管理的REST API接口
包括以下的功能:
- 认证(Authentication)
- 授权(Authorization)
- 准入(Admission)
准入(Admission) 分为两个阶段:
(1)Mutating
当用户要创建一个对象时,创建请求发送到了API Server。但从集群的视角看这个对象,还需要给这个对象做一些变形(比如: 增加一些属性;修改该对象的某些值等操作)。 这些操作在准入的Mutating阶段完成。在API Server接收到请求之后,直到该请求存储至etcd的路径过程中,向原始的需求中添加一些其他的属性。添加这些属性是为了后续方便做一些平台层面的操作。
(2)Validating
Validating阶段之前是Mutating阶段。当一个请求对象经历了Mutating阶段后,发生了变形。但变形后的请求对象不一定还是一个合法对象。Validating阶段就是负责对变形后的请求做校验的。
准入阶段不通过,则整个请求不会被存储至etcd。
结构图
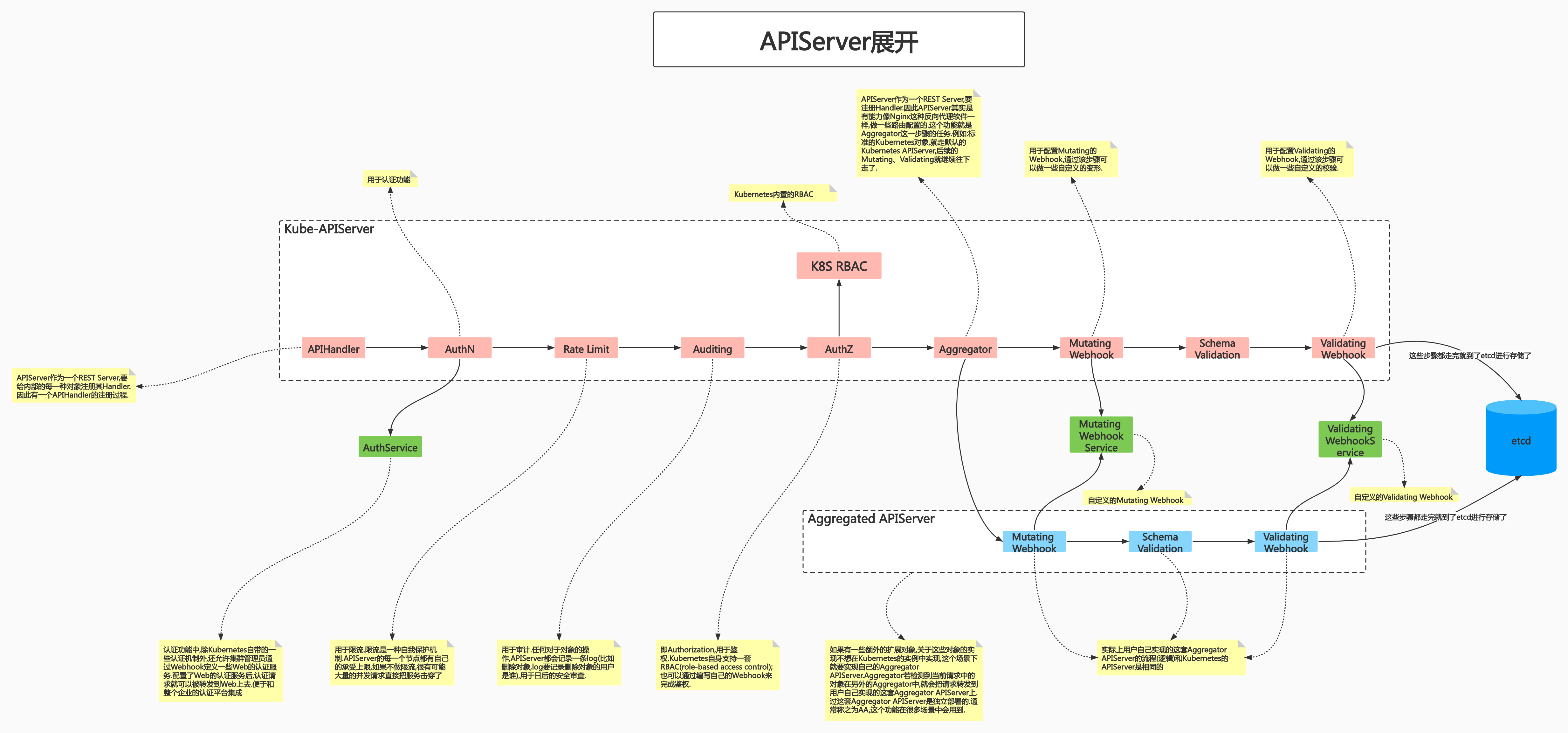
其他模块通过APIServer查询或修改数据,只有APIServer才能操作etcd
提供数据的缓存
提供etcd数据缓存以减少集群对etcd的访问
API Server本身还是个缓存。
API Server是唯一和etcd通信的组件。etcd是一个分布式K-V存储服务。由于是分布式存储服务,所以性能并不会特别好。如果请求是海量的,那么etcd一定是无法及时处理的。
因此API Server中维护了一份数据缓存。 API Server本身就会缓冲客户端对etcd的压力。对读操作而言,API Server也有缓存。如果客户端认同缓存中的内容,则这个读请求就不会发送至etcd。
Controller Manager
控制器的概念那可太多了~
Controller Manager是集群的大脑,是确保整个集群动起来的关键
Controller Manager的作用是确保Kubernetes遵循声明式系统规范,确保系统的真实状态(Actual State)与用户定义的期望状态(Desired State)一致
其实所有的控制器都遵循了同样的规范。先读取用户请求中的抽象对象,这个抽象对象中有用户的期望状态(Desired State)。读取到Desired State后,控制器就要去做真实的配置了。控制器要确保系统的真实状态(Actual State)和用户的期望状态保持一致。
Controller Manager是多个控制器的组合,每个Controller事实上都是一个control loop,负责侦听其管控的对象,当对象发生变更时完成配置
Controller 配置失败通常会触发自动重试,整个集群会在控制器不断重试的机制下确保 最终一致性(Eventual Consisitency)
如果配置出现了错误,控制器要自动重试,直到所有的请求都被满足,才放弃重试。这种不断重试的机制最终要达到的目的是: 最终一致性(Eventual Consisitency)
例: 用户提交了一个创建Pod的请求。在该请求中,用户描述该Pod需要4个CPU。但当前集群中已经没有任何节点能够满足该需求了,此时该Pod处于Pending的状态。即: 因为没有适合的节点,所以调度不成功。但这个调度后续还会不断重试,直到能够满足该请求的需求(可能是别的资源消失(退出),释放了足够多的资源; 也可能是当前集群中有新的节点加入进来),调度器会自动调用这个处于Pending状态的Pod,最终把这个Pod启动起来。
所谓 Eventual Consisitency,即从用户的视角看,不需要明显的重试,只需告知平台用户的期望,其他的工作由平台来完成。
但是从原有系统切到Kubernetes的情况下,往往会出现很多 不适应性。
例如: 原有系统中,某服务要求3个实例。迁移到Kubernetes时,Kubernetes会去创建Pod(实际上是1个Pod的3个副本),但Kubernetes并不保证一定能创建出3个能够运行的(处于Running)状态的Pod。但在原有系统中,对于申请资源是有其自己的失败机制的(比如提交申请后拿不到3个实例则判定为申请失败)。直白一点的说法就是: 原有系统有其自己的申请失败机制,和Kubernetes为确保Eventual Consisitency的重试机制相冲突
因此这种最终一致性的适应性是需要去理解的。
在本例中,就可以使用超时控制的思路来解决这个问题。为该次申请设置一个超时时间(假设超时时间为T小时),若提交申请后的T小时当Kubernetes还没有为该申请成功创建出3个处于Running状态的Pod,则报错。报错后就可以使用原有系统的申请失败机制来处理了。这样就可以与原有系统适配了。
工作流程
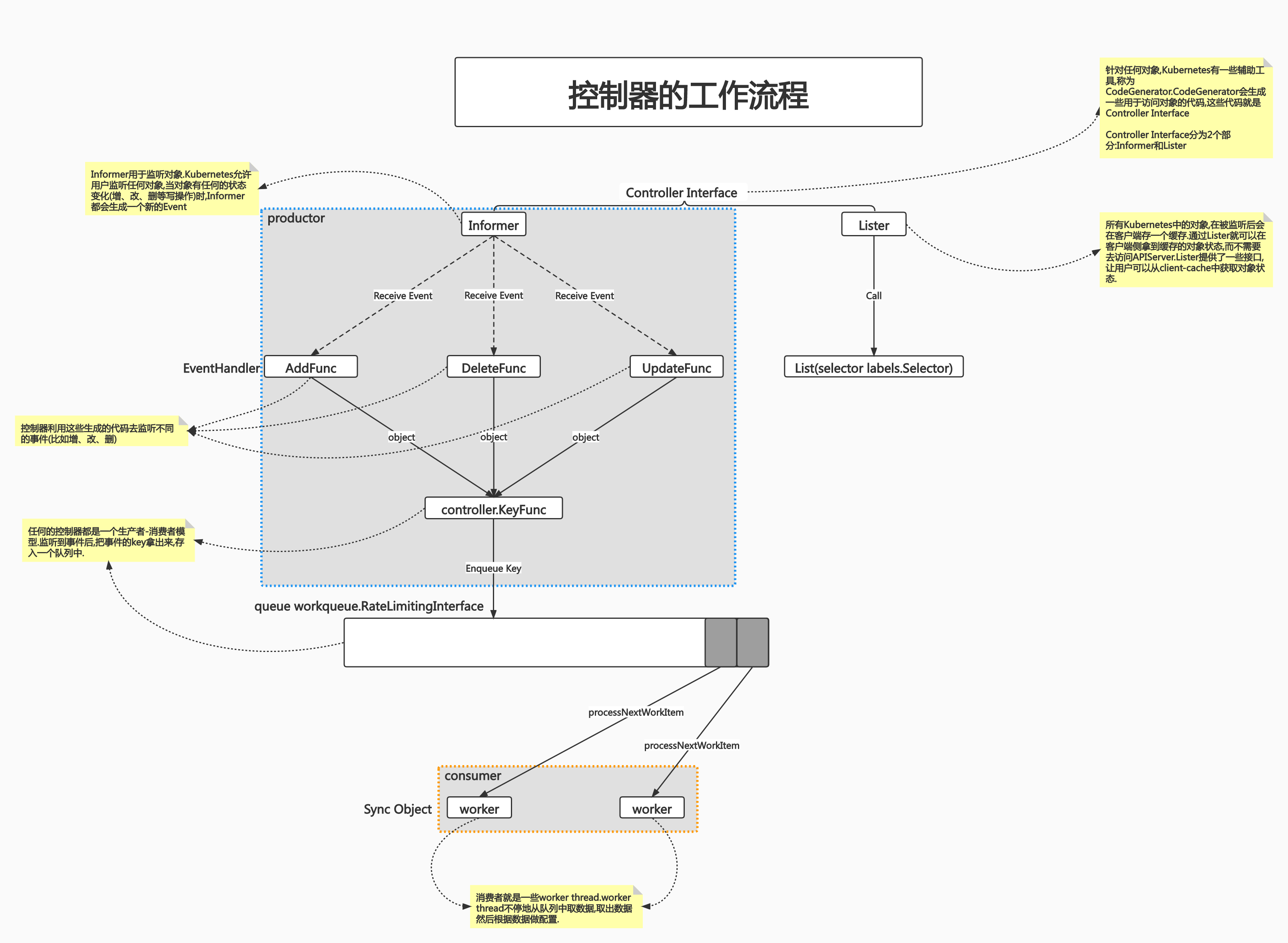
Informer 内部机制
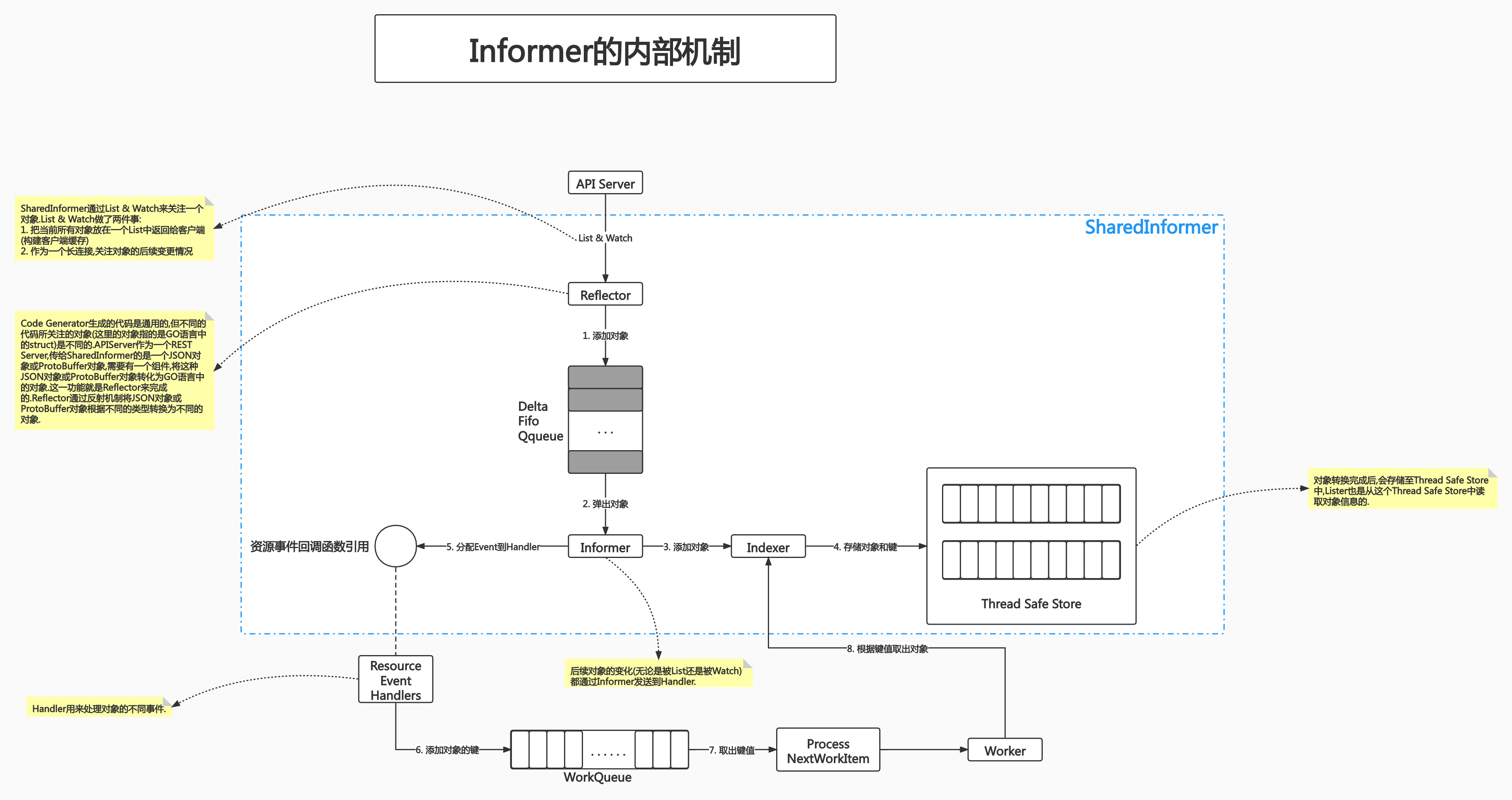
Kubernetes 中使用 http 进行通信,如何不依赖中间件的情况下保证消息的实时性,可靠性和顺序性等呢?答案就是利用了 Informer 机制。Informer 的机制,降低了了 Kubernetes 各个组件跟 Etcd 与 Kubernetes API Server 的通信压力。
这么一说,可能还是不理解,雀氏,我参考收集了书籍和文档,归纳如下:
设计 Kubernetes 的架构是特别复杂的,这些人也都是Linux特别牛的人才。
我们都知道 Kubernetes 中有很多 API 对象,我们定义这些对象的时候,只需要去定义他们的数据结构。
数据结构创建好后,会通过 API Server 发布, 然后我们就可以查看了。
Kubernetes 中所有对象的 访问 都是通过 API Server 去做的~
Informer 就是会提供
List & Watch机制,启动后会发送一个长连接到 API Server。先 list 一下,后 watch 一下。Reflector 通过反射机制解析 key,(swagger.json),将序列化 对象 转化为 Go语言 对象,放入 map。
后面是一个环状数据结构,然后我们往其中写入数据,数据满了就弹出老对象。放入 informer 中,然后就像图中说的,添加对象,同时分配 Event 到 Handler……
对象的信息 会 存储在本地缓存,所以我们后面读取对象的时候应该去
Therad Safe Store读取,而不是去 API Server 中读取。当我们需要更新对象的时候,需要去 API Server 中。
这样依赖 informer,降低了了 Kubernetes 各个组件跟 Etcd 与 Kubernetes API Server 的通信压力。
相关文章:
这里需要对应 Kubernetes 的代码去看。该部分的代码主要位于client-go这个第三方包中。
此部分的逻辑主要位于
/vendor/k8s.io/client-go/tools/cache包中,代码目录结构如下:
cache
├── controller.go # 包含:Config、Run、processLoop、NewInformer、NewIndexerInformer
├── delta_fifo.go # 包含:NewDeltaFIFO、DeltaFIFO、AddIfNotPresent
├── expiration_cache.go
├── expiration_cache_fakes.go
├── fake_custom_store.go
├── fifo.go # 包含:Queue、FIFO、NewFIFO
├── heap.go
├── index.go # 包含:Indexer、MetaNamespaceIndexFunc
├── listers.go
├── listwatch.go # 包含:ListerWatcher、ListWatch、List、Watch
├── mutation_cache.go
├── mutation_detector.go
├── reflector.go # 包含:Reflector、NewReflector、Run、ListAndWatch
├── reflector_metrics.go
├── shared_informer.go # 包含:NewSharedInformer、WaitForCacheSync、Run、HasSynced
├── store.go # 包含:Store、MetaNamespaceKeyFunc、SplitMetaNamespaceKey
├── testing
│ ├── fake_controller_source.go
├── thread_safe_store.go # 包含:ThreadSafeStore、threadSafeMap
├── undelta_store.go
架构设计:
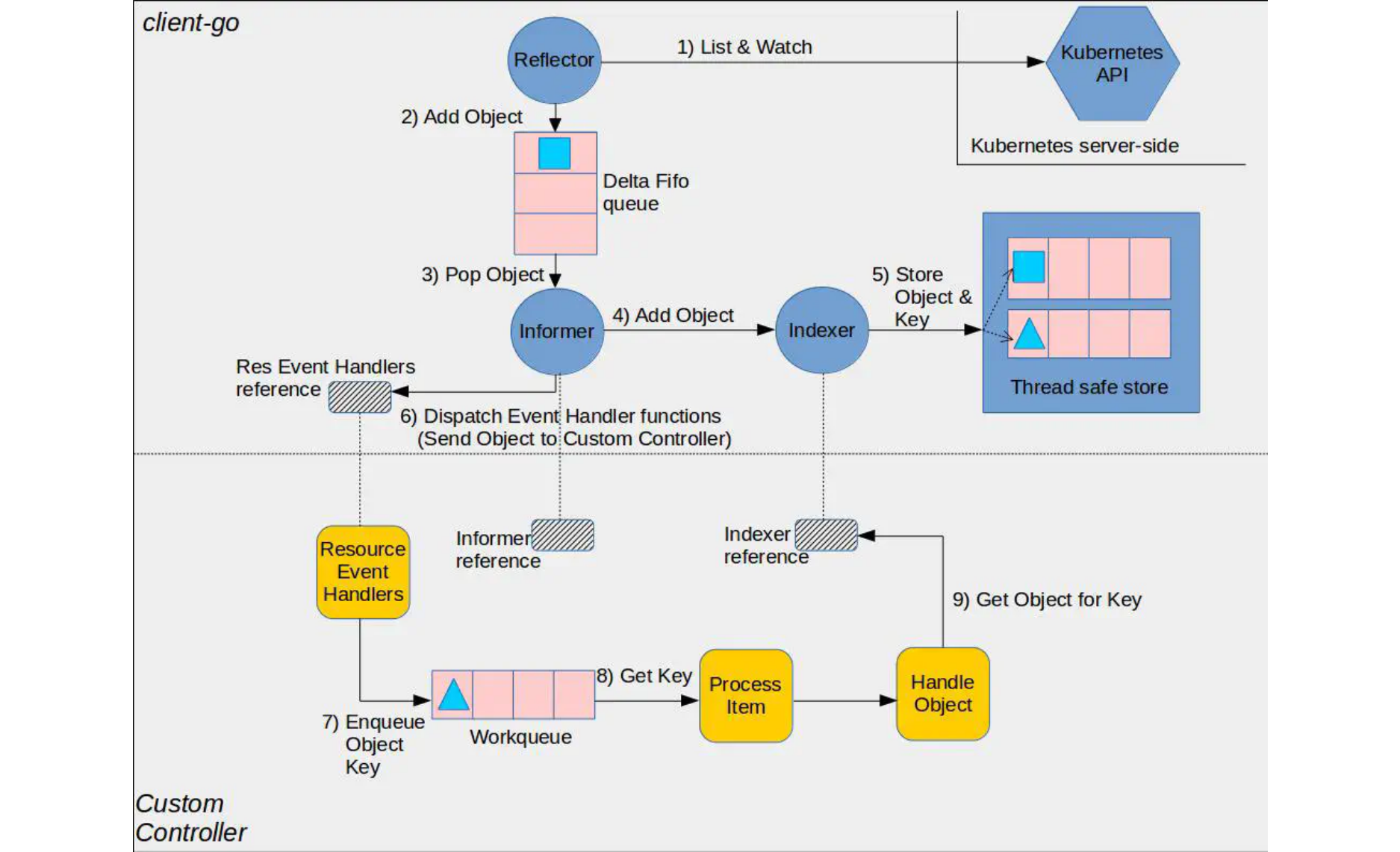
⚠️ 这张图分为两部分,黄色图标是开发者需要自行开发的部分,而其它的部分是 client-go 已经提供的,直接使用即可。
- Reflector:用于 Watch 指定的 Kubernetes 资源,当 watch 的资源发生变化时,触发变更的事件,比如 Added,Updated 和 Deleted 事件,并将资源对象存放到本地缓存 DeltaFIFO;
- DeltaFIFO:拆开理解,FIFO 就是一个队列,拥有队列基本方法(ADD,UPDATE,DELETE,LIST,POP,CLOSE 等),Delta 是一个资源对象存储,保存存储对象的消费类型,比如 Added,Updated,Deleted,Sync 等;
- Indexer:Client-go 用来存储资源对象并自带索引功能的本地存储,Reflector 从 DeltaFIFO 中将消费出来的资源对象存储到 Indexer,Indexer 与 Etcd 集群中的数据完全保持一致。从而 client-go 可以本地读取,减少 Kubernetes API 和 Etcd 集群的压力。
看书本上的一个例子,想使用 Informer 的关键流程如下:
clientset, err := kubernetes.NewForConfig(config)
stopCh := make(chan struct{})
defer close(stopch)
sharedInformers := informers.NewSharedInformerFactory(clientset, time.Minute)
informer := sharedInformer.Core().V1().Pods().Informer()
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{} {
// ...
},
UpdateFunc: func(obj interface{} {
// ...
},
DeleteFunc : func(obj interface{} {
// ...
})
informer.Run(stopCh)
})
Deployment 协同工作原理
先安装集群:
/root/workspces/sealer/_output/bin/sealer/linux_amd64/sealer run docker.io/sealerio/kubernetes:v1.22.15 --masters 192.168.137.133 --nodes 192.168.137.134 192.168.137.135 --user root --passwd 123456
在 master 节点上创建文件 nginx-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
Deployment对象用于描述一个无状态应用部署的对象。
在这个yaml文件中,template部分是一个模板。用户希望在Kubernetes上部署一个应用。应用在Kubernetes集群内部,就是一个Pod.此处用户指定:
- 在该Pod中使用nginx镜像(
spec.template.spec.containers.image) - 指定该Pod的副本数为1(
spec.replicas)
创建Deployment对象
kubectl create -f nginx-deploy.yaml -v 9
- 此处选项
-v 9表示查看创建时的日志信息.
读取配置文件
I0216 15:53:28.032360 1045972 loader.go:372] Config loaded from file: /home/soap/.kube/config
/home/soap/.kube/config即kubectl默认读取的配置文件.soap@k8s-master:~$ cat /home/soap/.kube/config apiVersion: v1 clusters: - cluster: certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMvakNDQWVhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1ESXdPVEE0TXpBek5Wb1hEVE15TURJd056QTRNekF6TlZvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTndnCmd3S1owUTlCcFBZTXJtSXYwK21yaEZuUWg1WDJhencyV1kxbUcxWnBNM3hLVXpsYnd1eGJZTkd5MWRWMXVOVDYKZTBMdFZqckNOZHBRWGhqYUI3UHJqbDRSR1RoT1FjQkFKMTNWclMva0hFVTFpWkdiOFhsdUJsa1JFRW1ZcEttdAo0R3dLbUJNdERYcENQdXdLVW5Ya05OamV4QlByWWF1bEcya0crL1oza2dGZnhIR2JBQjNjb25TamgxZTVlSzl5CkVUZXR2REE1cVBUS0hYRWlSdy91Uy9zdkQyWXBxVGpDOHRCeENNeGhGeXh2eXpIVVdQYlFjdTg0TG9pY0d0L2UKVUFDT1N3VUpiMTlndGlWSzlVWlZnb2V1bFZaS0Y2UHh2ZzkvRHhqc01ZQ1hZTXJCWXY3bUVIRU1DbVRBMWsvMApLY2FaOEo1dmVZWWlDVXUxM3FVQ0F3RUFBYU5aTUZjd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZNR0IrQUw4UGFZbVIwM1ZDNEJZUmsyNG5zT3hNQlVHQTFVZEVRUU8KTUF5Q0NtdDFZbVZ5Ym1WMFpYTXdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBR1dGd3YyT0EzV3lxemlRQXRPUQpKeEY2emFGL2pTQnJoSGc3WGV0NjdhcEZuRkFDaDZFbklTam9xd3ZEQ2MyQ0U1aHBtblNiT0luNUpxaThpeE5QCitKSGYxeXFmaHVrSWc0RjVUL0VjWnJGQXBPYWNHcVhlbTMzbWlLc0k1ZU5CUUY1WXFSeHVFai82bWt4WXlSUEcKMGNhd3VWeUlRMm01VTZPa3RnUW5neUtrS3BrQk5BcWcranJRTi9CdVoxTGRZcElvVXVpMVZxbHJhSmRTbG00RQplOWk3ekhIM3VOajdEdTJTdERreXdkOWF2VGMzRjBTRXI2TXd5cTZrdVgraFB3a2ZZeHNzNTlDc1E1alp3cGFhCkp0Skw2Ni9xaDFieTREbjNZOE5UaDlNZnRlMWRoc1pXaGVkYmZta3ErWVY2TlowTWJlRC9ZZ2lmNFJKM1U5V3cKNnVFPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg== server: https://192.168.0.154:6443 name: kubernetes contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes current-context: kubernetes-admin@kubernetes kind: Config preferences: {} users: - name: kubernetes-admin user: client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURJVENDQWdtZ0F3SUJBZ0lJR3dSdXh4ZFFjbzR3RFFZSktvWklodmNOQVFFTEJRQXdGVEVUTUJFR0ExVUUKQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TWpBeU1Ea3dPRE13TXpWYUZ3MHlNekF5TURrd09ETXdNemRhTURReApGekFWQmdOVkJBb1REbk41YzNSbGJUcHRZWE4wWlhKek1Sa3dGd1lEVlFRREV4QnJkV0psY201bGRHVnpMV0ZrCmJXbHVNSUlCSWpBTkJna3Foa2lHOXcwQkFRRUZBQU9DQVE4QU1JSUJDZ0tDQVFFQTZVenhRY1BBNUowcFJTc3UKcklOMkZKNFMwZUpwOFZkRmRidXM4Q0syQzk3Snl0eG9WRXJ2c0g1U1BUWU1kdWJRdFFkRkl2UzZYTHVnNmYzZQpaa0NVNmd5bit2bEIyNDRKQU15RFlPOG1GbU5RM3dKQUhRYXhsUTBITTdkUFhBZDJqOFVoZzZNRlRheGgxMmtNCjV4OXNJdndRM0c3LzFOZ240MnhoeWpZZDhlaGNkMFduNTJkY3VhNXcwU1FPN09mY0FkMU02TkU4dG1qMHZRejQKYU10MDFteXU5R0VKQU5nRFAxZXZZeTVLYTFDd0lGbEM0UVVVRXBSc3hud3EybW04amdEN3p1RXV1TDE2eEJocgphc1ZHWXhjcEMxQUxUNjFhbGU1TURBblc3RFZXL1R4cEgxZ3ROOENhOTVONTNITVAvc0NpMGh2bjlDM1FOaXc1CkQzc2ZMd0lEQVFBQm8xWXdWREFPQmdOVkhROEJBZjhFQkFNQ0JhQXdFd1lEVlIwbEJBd3dDZ1lJS3dZQkJRVUgKQXdJd0RBWURWUjBUQVFIL0JBSXdBREFmQmdOVkhTTUVHREFXZ0JUQmdmZ0MvRDJtSmtkTjFRdUFXRVpOdUo3RApzVEFOQmdrcWhraUc5dzBCQVFzRkFBT0NBUUVBeUhwaWdjdFpOVzd5ZStIc3Z2OWF1b0JQU05DdEJKZU8wbGtPClM3YmNwcTRSaFRQdVo0VzhtK3BzNGF5QndaQUtOTDQ5MXdYbVZqWE5ETG1IQ0FXb3dObldyVGNrZHR4UGtXeTUKNmFpSHdYaVUxK2dPRFlFQzdDTGlKR3RIRHZ4dkRvM2xRb2FBZEVpNnF5TVUvUmJIajRPTmduQ1VYSHNpMFB1WQppSHNZQWUxT2VTVmlKeVhBK1RjZ3RZZlc1N0xubnJ0WThsaWJYNzZHU1RaVHBlUUtiOUcyU3ZESitkQVpWYVhPCkUrZE1rays1Q0V4d1BTZEVDNnVEcjlkMVliSGNabEE2VlRpRnYrakpHWDdYZEd2ODI1bWhmUmRKc21LVGpmTjcKSHZiVEI4SFhyNkJIQ1d3emZmOXA0OXNnWUNVRHpLRmcwaWhmdStNQVZjeGtUMHlLRVE9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg== client-key-data: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFb3dJQkFBS0NBUUVBNlV6eFFjUEE1SjBwUlNzdXJJTjJGSjRTMGVKcDhWZEZkYnVzOENLMkM5N0p5dHhvClZFcnZzSDVTUFRZTWR1YlF0UWRGSXZTNlhMdWc2ZjNlWmtDVTZneW4rdmxCMjQ0SkFNeURZTzhtRm1OUTN3SkEKSFFheGxRMEhNN2RQWEFkMmo4VWhnNk1GVGF4aDEya001eDlzSXZ3UTNHNy8xTmduNDJ4aHlqWWQ4ZWhjZDBXbgo1MmRjdWE1dzBTUU83T2ZjQWQxTTZORTh0bWowdlF6NGFNdDAxbXl1OUdFSkFOZ0RQMWV2WXk1S2ExQ3dJRmxDCjRRVVVFcFJzeG53cTJtbThqZ0Q3enVFdXVMMTZ4QmhyYXNWR1l4Y3BDMUFMVDYxYWxlNU1EQW5XN0RWVy9UeHAKSDFndE44Q2E5NU41M0hNUC9zQ2kwaHZuOUMzUU5pdzVEM3NmTHdJREFRQUJBb0lCQURwamFWWCtPZjU5WHVEUwp4K0doSFNKWDFYbjE0bkhtVjVuNW1IU1pHMXFwTFhPNTZkcCt6cklyUzBYS2l5QU84RmorTXMxbTFtVnpCL2pICjhxdEFxb1JSR3BGelpJb2dhQnh0RXN4bHpmQjRkcnI1Z3paQWdKMC9IM2hQL21xWDY1SmIwZUZ5SVZlcE51dUUKZlJnekF3dFdicG5jcGVhTkdwNk9kNEwyUEZSWVNxaXZIZWQrYTFmT3hOeVNOUkQ0TkVXMzB1M2Q4OGk4c1pSUApsRlFuWTRlVytqaUc2Vmx1RzduUHNobDdGdzdIM09IOUZJMjFCbURMbmt6alI5SExNZTJhYllnSS96RWFtOGJXCkZObjFSVnpIVXNHYnRYZmpMTy8zT2lmVTY4MUdHZ1FSbU5GZ09NK1NrTjh4VEs4Rzd4QjBMdExVQ2RMVDVuTW0KZndtQ3VRRUNnWUVBNmF6MHQ2UEdOR0JEUXJoNHdWNGNZNlNuOTMzWDc3bEdEcmVhWWNDOVBnRHBJUGxkSUVJQwp1UThTaHNTOFRUSWsya05MK1FyWlorZUNRVmE5MEFXbHY4S0NiRXg3NzFkcS9BUDM4YkVsOXZ5eS9sZktXQjNlCng4OVFVNjlQUWdialJXaGF5VTJTS0ZtRzVlRE9iaVcxMEt5SWNmSXNCZ0hpUzJSR1hsdlpKY0VDZ1lFQS81YlEKVWhXc3lic2ZRTVlPUXkwQjVCYzRvZWF5K2ltc2RoRHF1azhZWFQ3TDZtTUNJYjF2MmhnZVErb1A5cU9LUEtpOApKbnoyY3N2czhZWUJ4UXFZeWc2U1JXMWhDNmQza00xRldKckhmdERiZXdFMS9VNlQ1L29XMWVJd3ZTRTVtMDEzClFqQTNURUwzM2RSSEQ2UlQ5Skd4V2JCcHpReTFNZno5OHl5NDRPOENnWUE3RjRiSERiNW9ybE0wQXl4ZVVldEIKODNpYWFKTjd4dEdGbFQ2UUs4cHZiSkdIeWllWHFibkFqS1ExdW5pWDJPOWkxcFBXeGJ5V3Z2KzhnQy85OC8rbgpUNHZsMFMyaUord2hFT3ZaamQrNDVzeG83MUIzR2c2bFhyTEVodGUzTGNDNVk1dFp2cWtRVlJ0ODlHMmZneC9JClJtazJ6M1A4ak90cC8xQ2dPZi9ld1FLQmdRRGxoYVM4SWhUUjhBVm40TFFNSlUzT2JBQUNmQzc3c2hMYXorUksKdlI3UEZjWi9UTHdzV25jb3JvSDNVU2xXdnBRMFZ2N252VTUvMXB1SVpXUVBjNjJ6dmhRaTNzL0liSEpXQ2RDZAplaGx1eTlaZGhyL2FJd2QxeWNOWi9VN3hlUFhIZm5CN2N0c2wwL25OTG9WR0NiY1BLUXJQMVRtZDF5eWNvR25aClI2OGE1d0tCZ0dmUmdqSEUzTWdKZkIrL09BR1lNYlhSMzZuQmYvVWozNktTZ1JYK2ZQRnRpWndDNXpIZ1FydHYKejI4N0lEWERIWlVxeEhrZkVJN1k2eld4aHpLVStwdnFpOFB5NzhRb3FmbkprdDBpVDM2bFRic0dUZHJvZW56Kwp2VEhYUjJEbk9yUDRjNHZYVEFGRzNiUUNsS0w1SUxaMHI1YjlmZGozRGJDRlJzNktBU1JJCi0tLS0tRU5EIFJTQSBQUklWQVRFIEtFWS0tLS0tCg==可以看到配置文件中有APIServer的地址和用于用户认证的身份信息
有了这些信息之后,kubectl就把请求发送到了APIServer的地址
I0216 15:53:28.033943 1045972 round_trippers.go:466] curl -v -XGET -H "Accept: application/com.github.proto-openapi.spec.v2@v1.0+protobuf" -H "User-Agent: kubectl/v1.23.3 (linux/amd64) kubernetes/816c97a" 'https://192.168.0.154:6443/openapi/v2?timeout=32s'
soap@k8s-master:~$ kubectl get rs
NAME DESIRED CURRENT READY AGE
...
nginx-deployment-6799fc88d8 1 1 1 20m
...
控制器工作
APIServer在完成认证、鉴权、准入的步骤后,将请求存储至etcd。存储完毕后控制器开始工作。
本例中我们创建的是一个 Deployment 对象,因此是由 Deployment Controller来完成这项工作.。Deployment对象有其语义,Deployment对象表示用户希望创建一个Pod(本例中创建的是只有1个副本的Pod).
Deployment Controller会去解析Deployment对象,并创建ReplicaSet对象(副本集对象)。相当于Deployment Controller告知APIServer:Deployment Controller要创建一个ReplicaSet对象,并将模板(yaml文件中的template部分)发送给APIServer.
ReplicaSet对象同样经过认证、鉴权、准入的步骤后,被存储至了etcd.之后ReplicaSet Controller会Watch APIServer,监听ReplicaSet对象。当ReplicaSet Controller监听到ReplicaSet对象被创建后,同样会去解析该ReplicaSet对象。通过解析得知副本数量、Pod模板等信息后,ReplicaSet Controller就可以完成Pod的创建了。
创建Pod这一操作同样也作为一个请求被发送到了APIServer。该Pod在创建时没有经过调度。
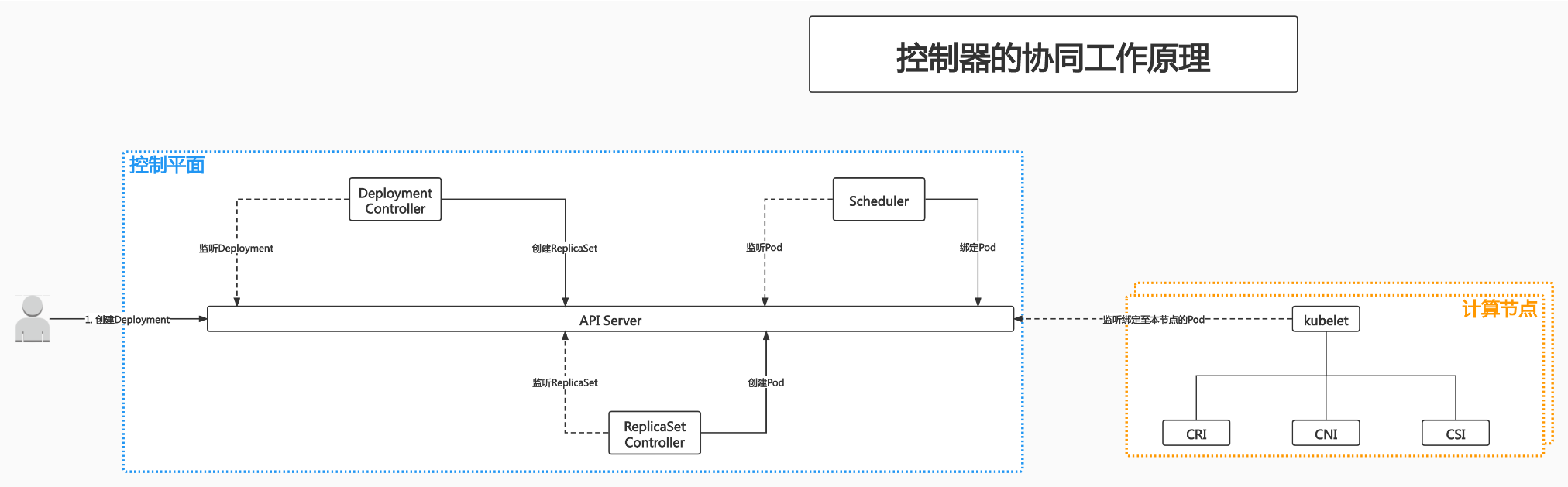
可以看到 deployment 并不是直接控制 pod ,而是 通过 创建 ReplicaSer 间接的控制 / 创建 Pod ,但是 deployment 只是负责水平迁移。所以是一个 双层控制器 实现故障转移和 HA(通过滚动升级实现)~
最后节点的 kubelet 就开始干活了,kubelet 监听绑定至本节点的 pod,然后去查一查,这个 pod 有没有 run。
init pod actions:
Kubernetes 在启动 docker 的时候,只是启动 runtime,然后调用 网络插件 CNI。
如果需要存储,就有 CSI。
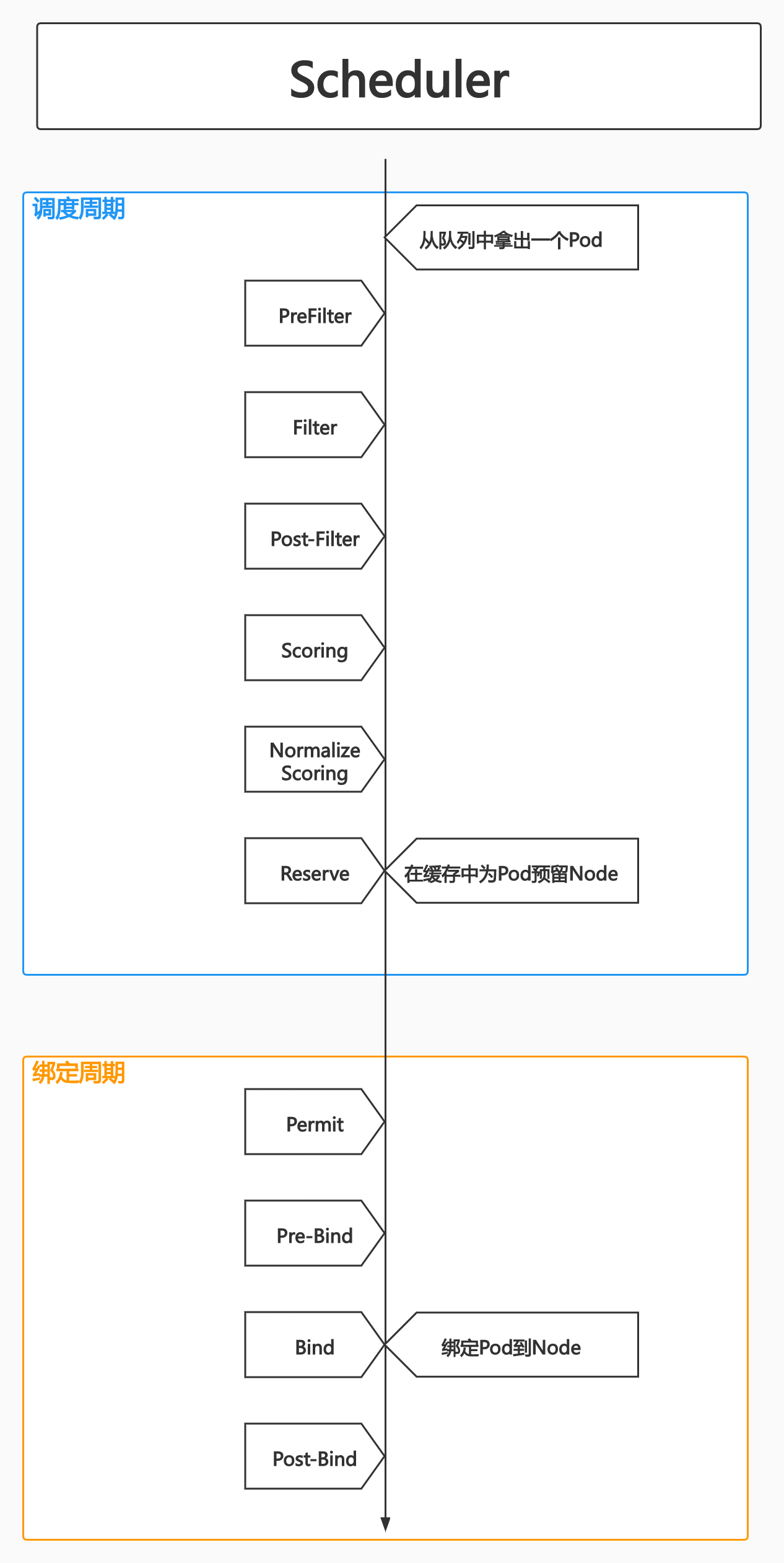
Scheduler
特殊的Controller,工作原理与其他控制器并无差别。
Scheduler的特殊职责:监控当前集群中所有未调度的Pod,并且获取当前集群所有节点的健康状况和资源使用情况,为待调度的Pod选择最佳计算节点,完成调度。
调度阶段
Predict
过滤不能满足业务需求的节点,如资源不足、端口冲突等。
Priority
按既定要素将满足调度需求的节点评分,选择最佳节点(调度算法)。
Bind
将计算节点与Pod绑定,完成调度。
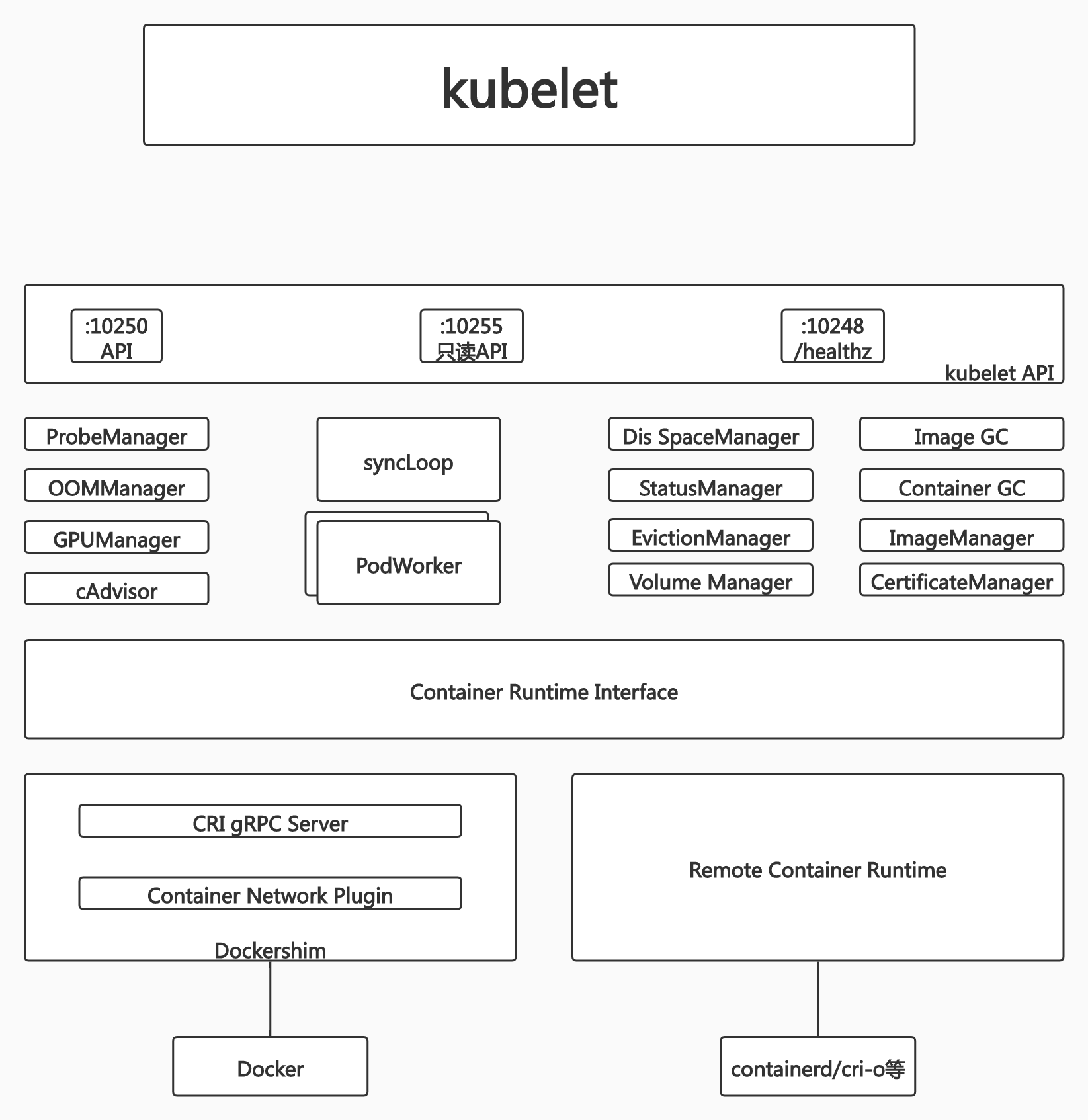
Kubelet
Kubernetes的初始化系统(init system)
很重要的组件,负责启动 pod,职责也是非常复杂的。
从不同源获取Pod清单,并按需求启停Pod核心组件
- Pod清单可以从本地文件目录、给定的HTTPServer、Kuber-APIServer等源头获取
- Kubelet将运行时(runtime),网络和存储抽象成了CRI、CNI和CSI
负责汇报当前节点的资源信息和健康状态
负责Pod的健康检查和状态汇报。
调度阶段完成后,目标节点上的kubelet会发现该Pod和当前节点存在绑定关系,kubelet会调用CRI、CNI和CSI来启动这个容器。
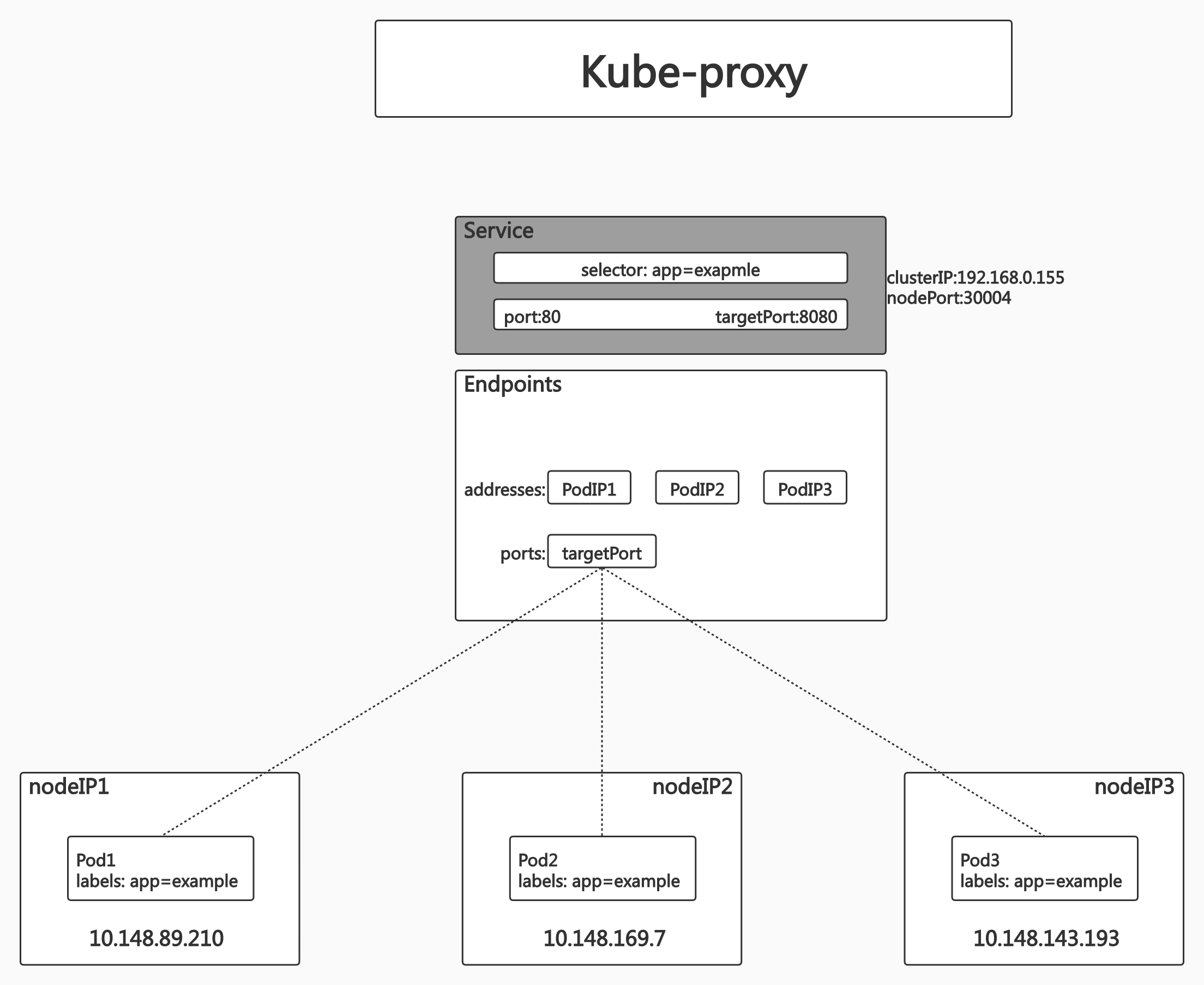
Kube-proxy
kube-proxy 也是在每个节点上都运行的。它是实现Kubernetes Service 机制的重要组件。毫无意外,kube-proxy 也是一个“控制器”。它也从API Server 监听Service 和Endpoint对象的变化,并根据Endpoint 对象的信息设置Service 到后端Pod 的路由,维护网络规则,执行TCP、UDP 和SCTP 流转发。
监控集群中用户发布的服务,并完成负载均衡的配置。
每个节点的 Kube-proxy 都会配置相同的负载均衡策略,使得整个集群的服务发现建立在分布式负载均衡器之上,服务调用无需经过额外的网络跳转(Network Hop)
负载均衡配置基于不同的插件实现 userspace
OS网络协议栈不同的Hooks点和插件:
- iptabes
- ipvs
Add-ons
以上都是Kubernetes的核心组件,Kubernetes还有一些 Add-on.
以下服务之所以以
Add-on的形式提供应用,是因为没有以上所讲的核心组件,整个集群是跑不起来的。但集群能够跑起来了(换言之核心组件都有了)剩下的应用就可以以附件的形式(或者说以普通用户(non root \ rootless)的形式),创建一个Pod来搭载应用。
**当然,核心的组件,和 Add-ons 的装法是不一样的,核心组件是通过二进制方式,启动。 **
推荐的 Add-ons
- kube-dns:负责为整个集群提供 DNS 服务;
- Ingress Controller:为服务提供外网入口;
- MetricsServer:提供资源监控;
- Dashboard:提供 GUI;
- Fluentd-Elasticsearch:提供集群日志采集、存储与查询。
了解 Kubectl
Kubectl 和 Kubeconfig
kubectl 是一个 Kubernetes 的命令行工具,它允许Kubernetes 用户以命令行的方式与 Kubernetes 交互,其默认读取配置文件 ~/.kube/config。
- kubectl 会将接收到的用户请求转化为 rest 调用以 rest client 的形式与 apiserver 通讯。
- apiserver 的地址,用户信息等配置在 kubeconfig。
通过 -v 参数打印日志以查看 kubectl 具体执行流程:
❯ kubectl get po -v 9
I0303 09:04:45.314593 137729 loader.go:372] Config loaded from file: /root/.kube/config
I0303 09:04:45.360723 137729 round_trippers.go:435] curl -v -XGET -H "Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json" -H "User-Agent: kubectl/v1.22.15 (linux/amd64) kubernetes/1d79bc3" 'https://apiserver.cluster.local:6443/api/v1/namespaces/default/pods?limit=500'
I0303 09:04:45.393763 137729 round_trippers.go:454] GET https://apiserver.cluster.local:6443/api/v1/namespaces/default/pods?limit=500 200 OK in 32 milliseconds
....
可以看到 kubectl 是对 API 的封装。
我们看一下配置文件有什么:
我们可以看一下所有的命令都会读取 kubectl 配置文件
- contexts:我们用哪个用户去链接
- current-context:如果我们不指定 context,那么使用的是哪个(默认)
- 用户的 Key 和 Secret
常用命令
kubectl get po –o yaml -w
-o yaml:输出详细信息为 yaml 格式。-w:watch 该对象的后续变化。-o wide:以详细列表的格式查看对象。
-o yaml不是很常用,我们更多的时候可以用kubectl get po -owide多输出几个字段。
kubectl describe 展示资源的详细信息和相关 Event
kubectl exec 提供进入运行容器的通道,可以进入容器进行 debug 操作。
kubectl logs 可查看 pod 的标准输入(stdout, stderr),与 tail 用法类似
kubectl api-resources 可以查看 Kubernetes 为我们提供的对象,有长名和短名字。
获取命名空间:
❯ k get ns
NAME STATUS AGE
default Active 10m
kube-node-lease Active 10m
kube-public Active 10m
kube-system Active 10m
K8s 设计理念
可扩展性:
- 基于CRD的扩展
- 插件化的生态系统
高可用:
- 基于 replicaset,statefulset 的应用高可用
- Kubernetes 组件本身高可用
可移植性:
- 多种 host Os 选择
- 多种基础架构的选择
- 多云和混合云
安全:
- 基于 TLS 提供服务
- Serviceaccount 和 user
- 基于 Namespace 的隔离
- secret
- Taints,psp, networkpolicy
分层架构
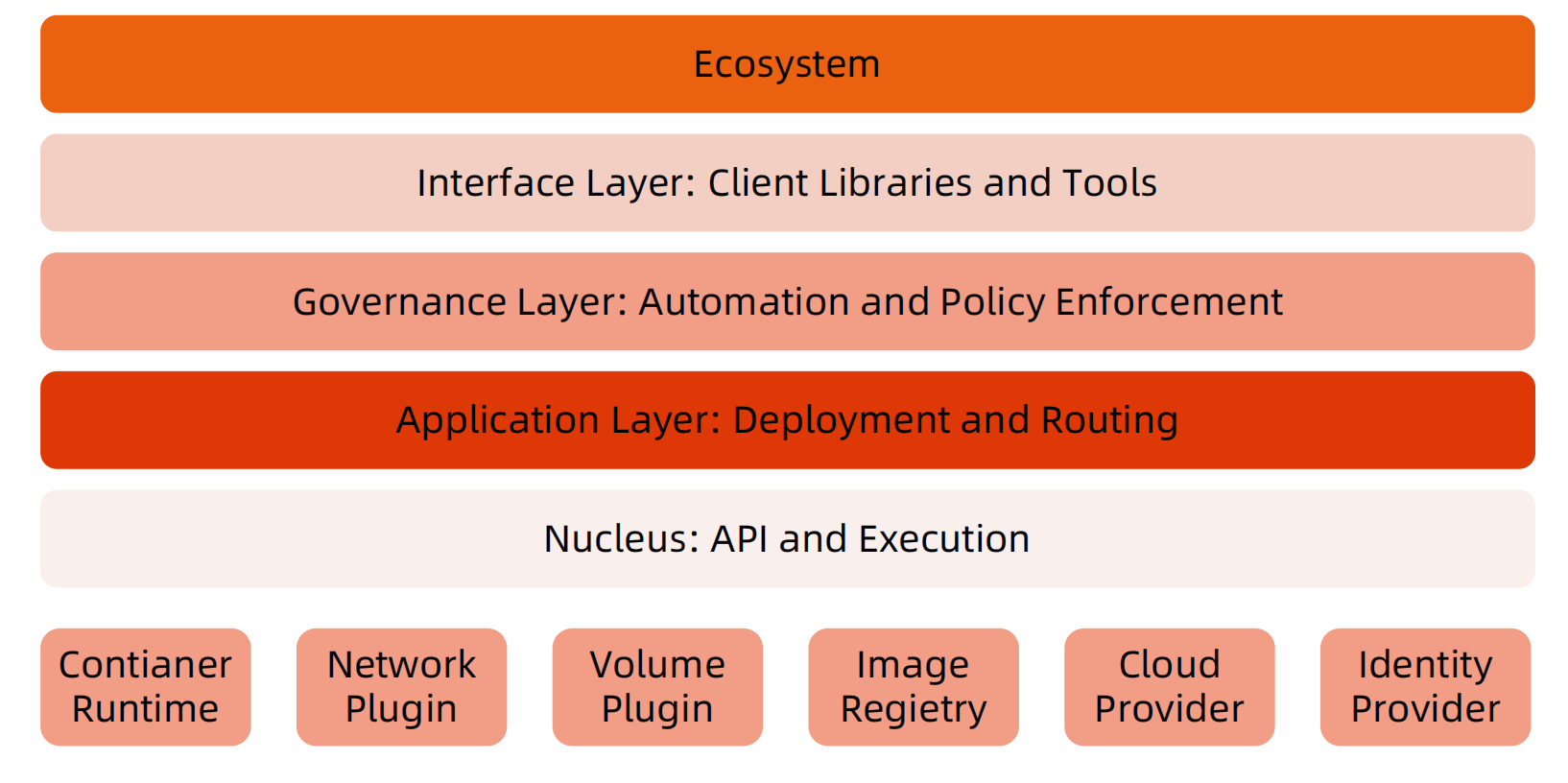
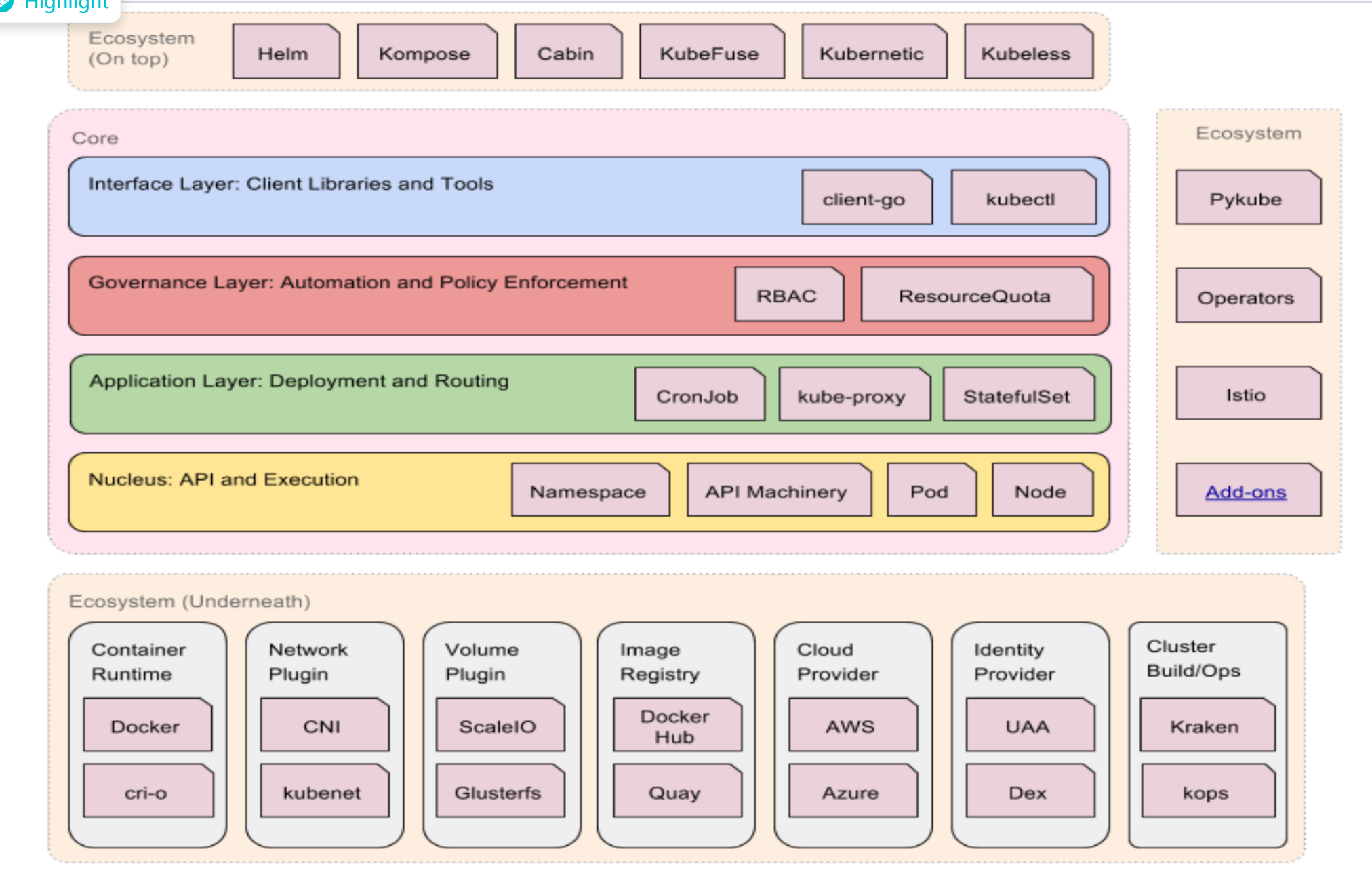
核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境。
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)。
管理层:系统度量(如基础设施、容器和网络的度量)、自动化(如自动扩展、动态 Provision 等)、策略管理(RBAC、Quota、PSP、NetworkPolicy 等)。
接口层:Kubectl 命令行工具、客户端 SDK 以及集群联邦。
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴:
- Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等;
- Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等。
如果你一定要分类的话,Kubernetes 和 docker 是和 paas 相关的。
分为两个视角:分别是集群管理员的视角和应用开发者的视角:
同样的分为两个平面:
- 数据平面: pod、PVC、Service、Ingress
- 控制平面:核心组件、插件、用户空间控制器、Assertion
Kubernetes 本身也是有分层架构,这保证了他的可扩展性。
API 设计理念
所有 API 都应是声明式的:
- 相对于命令式操作,声明式操作对于重复操作的效果是稳定的,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。
- 声明式操作更易被用户使用,可以使系统向用户隐藏实现的细节,同时也保留了系统未来持续优化的可能性。
- 此外,声明式的 API 还隐含了所有的 API 对象都是名词性质的,例如 Service、Volume 这些 API 都是名词,这些名词描述了用户所期望得到的一个目标对象。
API 对象是彼此互补而且可组合的:
- 这实际上鼓励 API 对象尽量实现面向对象设计时的要求,即“高内聚,松耦合”,对业务相关的概念有一个合适的分解,提高分解出来的对象的可重用性。
要在云原生基础上实现功能,先抽象出 API,即对象设计。
高层 API 以操作意图为基础设计:
- 如何能够设计好 API,跟如何能用面向对象的方法设计好应用系统有相通的地方,高层设计一定是从业务出发,而不是过早的从技术实现出发。
- 因此,针对 Kubernetes 的高层 API 设计,一定是以 Kubernetes 的业务为基础出发,也就是以系统调度管理容器的操作意图为基础设计。
低层 API 根据高层 API 的控制需要设计:
- 设计实现低层 API 的目的,是为了被高层 API 使用,考虑减少冗余、提高重用性的目的,低层 API 的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑。
尽量避免简单封装,不要有在外部 API 无法显式知道的内部隐藏的机制:
- 简单的封装,实际没有提供新的功能,反而增加了对所封装 API 的依赖性。
- 例如 StatefulSet 和 ReplicaSet,本来就是两种 Pod 集合,那么 Kubernetes 就用不同 API 对象来定义它们,而不会说只用同一个 ReplicaSet,内部通过特殊的算法再来区分这个 ReplicaSet 是有状态的还是无状态。
API 操作复杂度与对象数量成正比:
- API 的操作复杂度不能超过 O(N),否则系统就不具备水平伸缩性了。
API 对象状态不能依赖于网络连接状态:
- 由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证 API 对象状态能应对网络的不稳定,API 对象的状态就不能依赖于网络连接状态。
尽量避免让操作机制依赖于全局状态:
- 因为在分布式系统中要保证全局状态的同步是非常困难的。
Kubernetes 如何通过对象的组合完成业务描述
我们知道 Kubernetes 中组合也是很重要的,Kubernetes 是如何使用组合的:
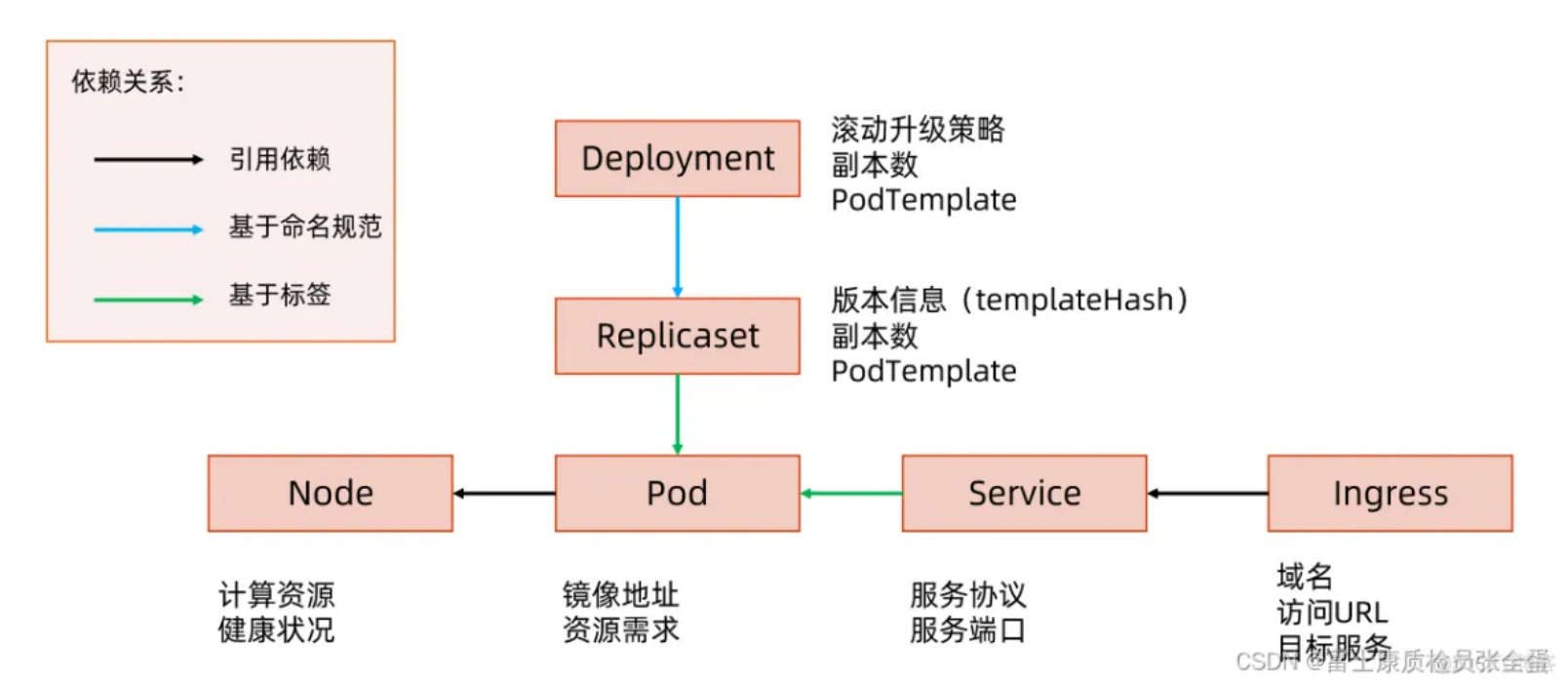
通过一个deployment创建一次业务部署这样的对象,deployment control会去建replicaset,replicaset会去建pod,pod会被调度器产生绑定关系,这是业务部署描述的部分,还有涉及的对象就是业务要发布的时候,我要去定义一个service,service创建之后kube-proxy会为它配置各种负载均衡的配置以及dns会为它配置域名服务,要将服务发布出去我要去定义一个service对象,service又可以通过ingress一个流量入口来发布到整个集群数据面API网关里面。
所以通过各种对象的组合来完成整个业务部署的描述。
注意命名规范的业务逻辑和基于标签的业务逻辑。
deployment 是根据 HASH 决定创建的 Replicaset 的名字,如果我们程序的 bug 导致Hash 算法变了,那么就会产生严重的程序漏洞。
集群中的每一个对象都有一个名称来标识在同类资源中的唯一性。
每个 Kubernetes 对象也有一个 UID 来标识在整个集群中的唯一性。
比如,在同一个名字空间 中只能有一个名为 myapp-1234 的 Pod,但是可以命名一个 Pod 和一个 Deployment 同为 myapp-1234。
对于用户提供的非唯一性的属性,Kubernetes 提供了标签(Label)和 注解(Annotation)机制。
架构设计原则
- 只有 APIServer 可以直接访问 etcd 存储,其他服务必须通过 Kubernetes API 来访问集群状态;
- 单节点故障不应该影响集群的状态;
- 在没有新请求的情况下,所有组件应该在故障恢复后继续执行上次最后收到的请求(比如网络分区或服务重启等);
- 所有组件都应该在内存中保持所需要的状态,APIServer 将状态写入 etcd 存储,而其他组件则通过 APIServer 更新并监听所有的变化;
- 优先使用事件监听而不是轮询。
通俗易懂解释轮询,侦听和回调区别:
- 轮询:过10分钟就到女朋友宿舍前面去看她有没有回来、没回来我就再去打游戏。
- 监听:我搬个凳子坐到她宿舍前、直到她回来。
- 回调:在她门口贴个条子:回来后请打电话至011 。
引导(Bootstrapping)原则
k8s 安装、引导原则
Self-hosting是目标。- 减少依赖,特别是稳态运行的依赖。
- 通过分层的原则管理依赖。
Self-hosting:
Kubernetes 可用性是第一原则,HA。
第二保证控制平面也是高可用的,如果我们把 Kubernetes 的控制平面组件也容器化了,那么是不是可以让 Kubernetes 自己管自己了。
,但是没有
kebelet,因为kubelet需要启动 pod 是 Kubernetes 的初始化(init) 系统,所以不是以容器的形式。
Kubelet 拉取机制:
监听 API Server~
查看 Kubelet 配置:

cat /var/lib/kubelet/config.yaml
可以发现有一个
staticPodPath,kubelet 会一直扫描 staticPodPath 目录中的文件,只要我们把任意一个 pod 丢进去, kubelet 就认为你会启动这个。❯ ls /etc/kubernetes/manifests etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml ❯ cat /etc/kubernetes/manifests/kube-scheduler.yamlkubelet 是一个 普通的进程~
循环依赖问题的原则:
- 同时还接受其他方式的数据输入(比如本地文件等),这样在其他服务不可用时还可以手动配置引导服务;
- 状态应该是可恢复或可重新发现的;
- 支持简单的启动临时实例来创建稳态运行所需要的状态,使用分布式锁或文件锁等来协调不同状态的切换(通常称为 pivoting 技术);
- 自动重启异常退出的服务,比如副本或者进程管理器等。
核心技术概念和 API 对象
云计算相关标准(抽象)的定义,保证了 k8s 处于不败之地。
因为当前所有云厂商都认可了 k8s 这套标准,后续就算有新的技术出现也必定遵循这套标准,否则云厂商肯定不会认可。
API 对象是 Kubernetes 集群中的管理操作单元。
Kubernetes 集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的 API 对象,支持对该功能的管理操作。
每个 API 对象都有四大类属性:
- TypeMeta:定义的对象是什么
- MetaData:定义的对象名字和标签等基础属性
- Spec:用户的期望值是什么
- Status:由系统的控制器实现的,用户无需关心(默认)
TypeMeta
Kubernetes对象的最基本定义,它通过引入**GKV(Group,Kind,Version)**模型定义了一个对象的类型。
1. Group
Kubernetes 定义了非常多的对象,如何将这些对象进行归类是一门学问,将对象依据其功能范围归入不同的分组,比如把支撑最基本功能的对象归入 core 组,把与应用部署有关的对象归入 apps 组,会使这些对象的可维护性和可理解性更高。
2. Kind
定义一个对象的基本类型,比如 Node、Pod、Deployment 等。
3. Version
社区每个季度会推出一个 Kubernetes 版本,随着 Kubernetes 版本的演进,对象从创建之初到能够完全生产化就绪的版本是不断变化的。与软件版本类似,通常社区提出一个模型定义以后,随着该对象不断成熟,其版本可能会从 v1alpha1 到 v1alpha2,或者到 v1beta1,最终变成生产就绪版本 v1。
MetaData
Metadata 中有两个最重要的属性:Namespace和Name,分别定义了对象的Namespace 归属及名字,这两个属性唯一定义了某个对象实例。
1. Label
顾名思义就是给对象打标签,一个对象可以有任意对标签,其存在形式是键值对。Label 定义了对象的可识别属性,Kubernetes API 支持以 Label 作为过滤条件查询对象。
- Label 是识别 Kubernetes 对象的标签,以 key/value 的方式附加到对象上。
- key 最长不能超过 63 字节,value 可以为空,也可以是不超过 253 字节的字符串。
- Label 不提供唯一性,并且实际上经常是很多对象(如 Pods)都使用相同的 label 来标志具体的应用。
- Label 定义好后其他对象可以使用 Label Selector 来选择一组相同 label 的对象
- Label Selector 支持以下几种方式:
- 等式,如 app=nginx 和 env!=production;
- 集合,如 env in (production, qa);
- 多个 label(它们之间是 AND 关系),如 app=nginx,env=test。
2. Annotation
Annotation 与 Label 一样用键值对来定义,但 Annotation 是作为属性扩展,更多面向于系统管理员和开发人员,因此需要像其他属性一样做合理归类。
- Annotations 是 key/value 形式附加于对象的注解。
- 不同于 Labels 用于标志和选择对象,Annotations 则是用来记录一些附加信息,用来辅助应用部署、安全策略以及调度策略等。
- 比如 deployment 使用 annotations 来记录 rolling update 的状态。
3. Finalizer
Finalizer 本质上是一个资源锁,Kubernetes 在接收某对象的删除请求时,会检查 Finalizer 是否为空,如果不为空则只对其做逻辑删除,即只会更新对象中的 metadata.deletionTimestamp 字段。
4. ResourceVersion
ResourceVersion 可以被看作一种乐观锁,每个对象在任意时刻都有其 ResourceVersion,当 Kubernetes 对象被客户端读取以后,ResourceVersion 信息也被一并读取。此机制确保了分布式系统中任意多线程能够无锁并发访问对象,极大提升了系统的整体效率。
[root@dev ~]# kubectl get ns kube-system -oyaml
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: "2023-03-03T11:44:55Z"
labels:
kubernetes.io/metadata.name: kube-system
name: kube-system
resourceVersion: "5"
uid: d0c7cf7a-7430-4d7f-a9fe-5fb2e66e0e0a
spec:
finalizers:
- kubernetes
status:
phase: Active
Spec 和 Status
Spec 和 Status 才是对象的核心。
- Spec 是用户的期望状态,由创建对象的用户端来定义。
- Status 是对象的实际状态,由对应的控制器收集实际状态并更新。
- 与 TypeMeta 和 Metadata 等通用属性不同,Spec 和 Status 是每个对象独有的。
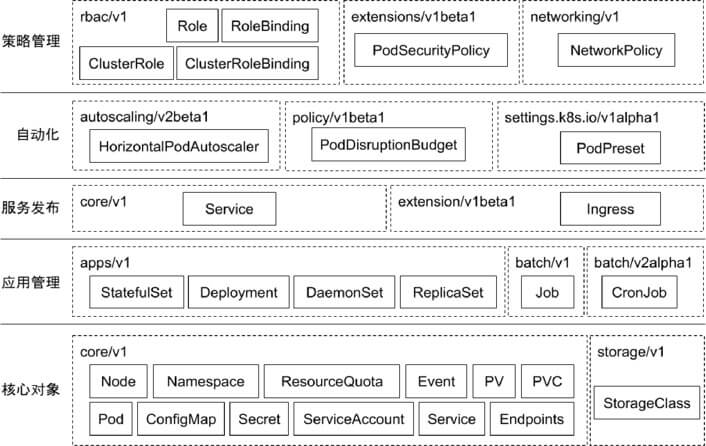
常用对象及其分组
核心对象概览
Node
- Node 是 Pod 真正运行的主机,可以物理机,也可以是虚拟机。
- 为了管理 Pod,每个 Node 节点上至少要运行 container runtime(比如 Docker 或者 Rkt)、Kubelet 和 Kube-proxy 服务。
- 是一个计算节点的对象
Namespace
Namespace 是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。
docker 中也提到过,我们可以建不同个 虚拟目录 然后将不同项目和不同组织项目放在一起。
常见的 pods, services, replication controllers 和 deployments 等都是属于某一个 Namespace 的(默认是 default),而 Node, persistentVolumes等则不属于任何 Namespace。
创建的时候不加 namespace,那么默认是:default
kubectl create -f nginx-deploy.yaml --namespace kube-system相同名称的对象可以放入到不同的namespaces,同名文件可以放入不同目录。
Pod
- Pod 是一组紧密关联的容器集合,它们共享 PID、IPC、Network 和 UTS namespace,是 Kubernetes 调度的基本单位。
- Pod 的设计理念是支持多个容器在一个 Pod 中共享网络和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。
- 同一个 Pod 中的不同容器可共享资源:
- 共享网络
Namespace; - 可通过挂载存储卷共享存储;
- 共享 Security Context。
- 共享网络
存储卷
通过存储卷可以将外挂存储挂载到 Pod 内部使用。
存储卷定义包括两个部分: Volume 和 VolumeMounts。
- Volume:定义 Pod 可以使用的存储卷来源;
- VolumeMounts:定义存储卷如何 Mount 到容器内部
Pod 网络
Pod的多个容器是共享网络 Namespace 的,这意味着:
- 同一个 Pod 中的不同容器可以彼此通过 Loopback 地址访问:
- 在第一个容器中起了一个服务 http://127.0.0.1 。
- 在第二个容器内,是可以通过
http Get http://172.0.0.1访问到该地址的。
- 这种方法常用于不同容器的互相协作。
资源限制
Kubernetes 通过 Cgroups 提供容器资源管理的功能,可以限制每个容器的 CPU 和内存使用,比如对于刚才创建的 deployment,可以通过下面的命令限制nginx 容器最多只用 50% 的 CPU 和 128MB 的内存:
$ kubectl set resources deployment nginx-app -c=nginx --limits=cpu=500m,memory=128Mi
deployment "nginx" resource requirements updated
等同于在每个 Pod 中设置 resources limits。
健康检查
Kubernetes 作为一个面向应用的集群管理工具,需要确保容器在部署后确实处在正常的运行状态。
1. 探针类型:
- LivenessProbe
- 探测应用是否处于健康状态,如果不健康则删除并重新创建容器。
- ReadinessProbe
- 探测应用是否就绪并且处于正常服务状态,如果不正常则不会接收来自 Kubernetes Service 的流量。
- StartupProbe
- 探测应用是否启动完成,如果在
failureThreshold*periodSeconds周期内未就绪,则会应用进程会被重启。
- 探测应用是否启动完成,如果在
2. 探活方式:
- Exec
- TCP socket
- HTTP
ConfigMap
- ConfigMap 用来将非机密性的数据保存到键值对中。
- 使用时, Pods 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。
- ConfigMap 将环境配置信息和 容器镜像解耦,便于应用配置的修改。
Secret
- Secret 是用来保存和传递密码、密钥、认证凭证这些敏感信息的对象。
- 使用 Secret 的好处是可以避免把敏感信息明文写在配置文件里。
- Kubernetes 集群中配置和使用服务不可避免的要用到各种敏感信息实现登录、认证等功能,例如访问 AWS 存储的用户名密码。
- 为了避免将类似的敏感信息明文写在所有需要使用的配置文件中,可以将这些信息存入一个 Secret 对象,而在配置文件中通过 Secret 对象引用这些敏感信息。
- 这种方式的好处包括:意图明确,避免重复,减少暴漏机会。
用户(User Account)& 服务帐户(Service Account)
顾名思义,用户帐户为人提供账户标识,而服务账户为计算机进程和 Kubernetes 集群中运行的 Pod 提供账户标识。
用户帐户和服务帐户的一个区别是作用范围:
- 用户帐户对应的是人的身份,人的身份与服务的 Namespace 无关,所以用户账户是跨 Namespace 的;
- 而服务帐户对应的是一个运行中程序的身份,与特定 Namespace 是相关的。
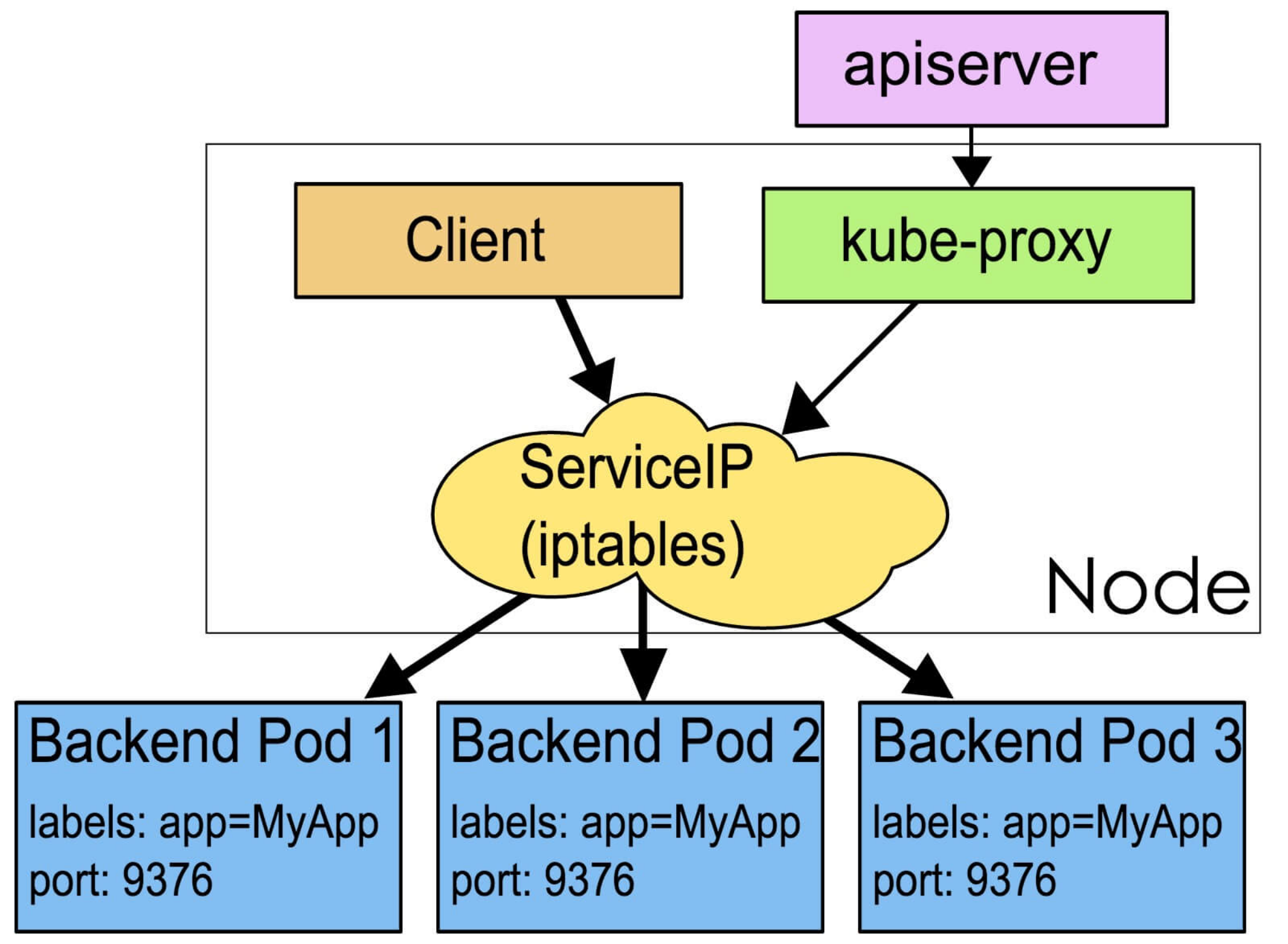
Service
Service 是应用服务的抽象,通过 labels 为应用提供负载均衡和服务发现。匹 配 labels 的 Pod IP 和端口列表组成 endpoints,由 Kube-proxy 负责将服务IP 负载均衡到这些 endpoints 上。
每个 Service 都会自动分配一个 cluster IP(仅在集群内部可访问的虚拟地址) 和 DNS 名,其他容器可以通过该地址或 DNS 来访问服务,而不需要了解后端容器的运行。
Replica Set
- Pod 只是单个应用实例的抽象,要构建高可用应用,通常需要构建多个同样的副本,提供同一个服务。
- Kubernetes 为此抽象出副本集 ReplicaSet,其允许用户定义 Pod 的副本数,每一个 Pod 都会被当作一个无状态的成员进行管理,Kubernetes 保证总是有用户期望的数量的 Pod 正常运行。
- 当某个副本宕机以后,控制器将会创建一个新的副本。
- 当因业务负载发生变更而需要调整扩缩容时,可以方便地调整副本数量。
Deployment
- 部署表示用户对 Kubernetes 集群的一次更新操作。
- 部署是一个比 RS 应用模式更广的 API 对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。
- 滚动升级一个服务,实际是创建一个新的 RS,然后逐渐将新 RS 中副本数增加到理想状态,将旧 RS 中的副本数减小到 0 的复合操作。
- 这样一个复合操作用一个 RS 是不太好描述的,所以用一个更通用的 Deployment 来描述。
- 以 Kubernetes 的发展方向,未来对所有长期伺服型的的业务的管理,都会通过 Deployment 来管理。
StatefulSet(有状态服务集)
- 对于 StatefulSet 中的 Pod,每个 Pod 挂载自己独立的存储,如果一个 Pod 出现故障,从其他节点启动一个同样名字的Pod,要挂载上原来 Pod 的存储继续以它的状态提供服务。
- 适合于 StatefulSet 的业务包括数据库服务 MySQL 和 PostgreSQL,集群化管理服务 ZooKeeper、etcd 等有状态服务。
- 使用 StatefulSet,Pod 仍然可以通过漂移到不同节点提供高可用,而存储也可以通过外挂的存储来提供高可靠性,StatefulSet 做的只是将确定的 Pod 与确定的存储关联起来保证状态的连续性。
有状态服务比较复杂~
Statefulset 与 Deployment 的差异
身份标识
- StatefulSet Controller 为每个 Pod 编号,序号从0开始。
数据存储
- StatefulSet 允许用户定义 volumeClaimTemplates,Pod 被创建的同时,Kubernetes 会以volumeClaimTemplates 中定义的模板创建存储卷,并挂载给 Pod。
StatefulSet 的升级策略不同:
- onDelete
- 滚动升级
- 分片升级
Job
- Job 是 Kubernetes 用来控制批处理型任务的 API 对象。
- Job 管理的 Pod 根据用户的设置把任务成功完成后就自动退出。
- 成功完成的标志根据不同的 spec.completions 策略而不同:
- 单 Pod 型任务有一个 Pod 成功就标志完成;
- 定数成功型任务保证有 N 个任务全部成功;
- 工作队列型任务根据应用确认的全局成功而标志成功。
DaemonSet
- 长期伺服型和批处理型服务的核心在业务应用,可能有些节点运行多个同类业务的 Pod,有些节点上又没有这类 Pod 运行;
- 而后台支撑型服务的核心关注点在 Kubernetes 集群中的节点(物理机或虚拟机),要保证每个节点上都有一个此类 Pod 运行。
- 节点可能是所有集群节点也可能是通过 nodeSelector 选定的一些特定节点。
- 典型的后台支撑型服务包括存储、日志和监控等在每个节点上支撑 Kubernetes 集群运行的服务。
存储 PV 和 PVC
- PersistentVolume(PV)是集群中的一块存储卷,可以由管理员手动设置,或当用户创建 PersistentVolumeClaim(PVC)时根据 StorageClass 动态设置。
- PV 和 PVC 与 Pod 生命周期无关。也就是说,当 Pod 中的容器重新启动、Pod 重新调度或者删除时,PV 和 PVC 不会受到影响,Pod 存储于 PV 里的数据得以保留。
- 对于不同的使用场景,用户通常需要不同属性(例如性能、访问模式等)的 PV。
CustomResourceDefinition
- CRD 就像数据库的开放式表结构,允许用户自定义 Schema。
- 有了这种开放式设计,用户可以基于 CRD 定义一切需要的模型,满足不同业务的需求。
- 社区鼓励基于 CRD 的业务抽象,众多主流的扩展应用都是基于 CRD 构建的,比如 Istio、Knative。
- 甚至基于 CRD 推出了 Operator Mode 和 Operator SDK,可以以极低的开发成本定义新对象,并构建新对象的控制器。
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©