第58节 Kubernetes 网络
❤️💕💕新时代拥抱云原生,云原生具有环境统一、按需付费、即开即用、稳定性强特点。Myblog:http://nsddd.top
[TOC]
Kubernetes 网络基础
网络很难,Kubernetes 的网络更难,后面更是有复杂的网络分治,要理解实现,必须对Kubernetes的网络有着深入的了解。
警告
Kubernetes 往深处挖必须要打好网络的基础,这个很重要 ~
从使用交换机、路由器和以太网电缆的物理网络迁移到使用软件定义网络(SDN)和虚拟接口的虚拟网络需要一段时间。当然,原则是相同的,但有不同的规范和最佳实践。Kubernetes有自己的一套规则,如果您要处理容器和云,了解Kubernetes网络的工作原理会有所帮助。
"网络栈" 包括了网卡(network interface)、回环设备(loopback device)、路由表(routing table) 和 iptables 的规则,这些是构成了网络的发起和响应的基本要素。
网卡工作在 OSI 模型的第二层(数据链路层)和第一层(物理层),负责处理物理网络的数据流。网卡通常由网卡驱动程序控制,网卡驱动程序是运行在内核态的程序。用户态的应用程序可以通过套接字(socket)接口与内核空间的网络协议栈进行通信,从而通过网卡发送和接收网络数据包。在 Linux 系统中,用户态的应用程序通过套接字接口向内核空间发送网络数据包,并通过该接口接收来自内核空间的网络数据包。
这篇文章,我将收集 以下 资料进行整理、说明 💡:
- 《深入剖析Kubernetes》:Kubernetes 网络原理
- 刘超老师的 《趣谈网络协议》
- https://opensource.com/article/22/6/kubernetes-networking-fundamentals
- https://kubernetes.io/docs/concepts/cluster-administration/networking/
- https://dramasamy.medium.com/life-of-a-packet-in-kubernetes-part-1-f9bc0909e051
这篇文章,最终会归纳到 docs: https://docker.nsddd.top Kubernetes / CloudNative
Kubernetes网络模型有几条一般规则需要牢记:
- 每个Pod都有自己的IP地址:不需要在Pod之间创建链接,也不需要将容器端口映射到主机端口。
- 不需要NAT:节点上的Pod应能够与所有节点上的所有Pod通信,而无需NAT。
- Agents 获得所有访问权限:node 上的 agent(system daemons、Kubelet)可以与该节点中的所有Pod通信。
- 共享命名空间:Pod中的容器共享网络名称空间(IP和MAC地址),因此它们可以使用环回地址相互通信。
Kubernetes 中网络的解决方案
Kubernetes网络设计用于确保Kubernetes中的不同实体类型可以通信。Kubernetes基础设施的布局在设计上有很大的分离度。名称空间、容器和Pod旨在保持组件之间的区别,因此高度结构化的通信计划非常重要。

网络是Kubernetes的核心部分,但要准确了解它的工作方式可能会很有挑战性。有4个不同的网络问题需要解决:
- 高度耦合的容器间通信:这个已经被 Pod 和
localhost通信解决了。 - Pod 间通信:这是本文档讲述的重点。
- Pod 与 Service 间通信:涵盖在 Service 中。
- 外部与 Service 间通信:也涵盖在 Service 中。
Kubernetes完全是为了在应用程序之间共享机器。通常,共享计算机需要确保两个应用程序不会尝试使用相同的端口。跨多个开发人员协调端口非常难以大规模进行,并且会使用户面临超出其控制范围的群集级问题。
Container-to-container networking
容器到容器的网络连接通过Pod namespace 进行。namespace空间允许您拥有独立的网络接口和路由表,它们与系统的其余部分隔离并独立运行。 每个Pod都有自己的网络名称空间,Pod内的容器共享相同的IP地址和端口。这些容器之间的所有通信都通过localhost进行,因为它们都是同一名称空间的一部分。(上图中以绿色线表示。)
我们在前面某一节有学过 docker 的网络知识,这很重要不是嘛👀 。我们尝试启动 container:
$ docker run -d -net=host --name nginx-host nginx
我们尝试启动 nginx,但是这种情况下我们知道启动的默认端口是宿主机的 80 端口。
这种方式,虽然和主机使用同一个 网络栈,可以为容器提供良好的网络性能,但是可能会带来共享网络资源带来的一系列问题,如网络隔离性、网络的端口冲突,记得我们的解决方案就是 : Network Namespece.
docker 中在宿主机创建一个 叫 docker0 的网桥,凡是和 docker0 链接的容器,都可以用它来通信,而容器链接到 docker0 的方式,就更加微妙了,使用的方式是 Veth Pair 的虚拟设备。
在 Docker 中,Veth Pair(或称 Veth 对)是一种虚拟网络设备,它由一对虚拟网卡组成,一端连接到 Docker 容器中的网络命名空间,另一端连接到宿主机的网络命名空间。Veth Pair 提供了一种简单而高效的方式,让容器和宿主机之间可以进行网络通信。
Veth Pair 的一个重要特点是,它们是成对出现的,一端连接到 Docker 容器中,另一端连接到宿主机中。由于 Veth Pair 是虚拟设备,所以它们不会占用宿主机中的物理网络接口,从而可以避免网络资源的浪费。
Pod-to-Pod networking
使用Kubernetes时,每个节点都有指定的Pod IP CIDR范围。这可确保每个Pod都收到群集中其他Pod可以看到的唯一IP地址。创建新Pod时,IP地址决不会重叠。与容器到容器网络不同,Pod到Pod通信使用真实的IP,无论您将Pod部署在群集中的同一节点还是不同节点上。
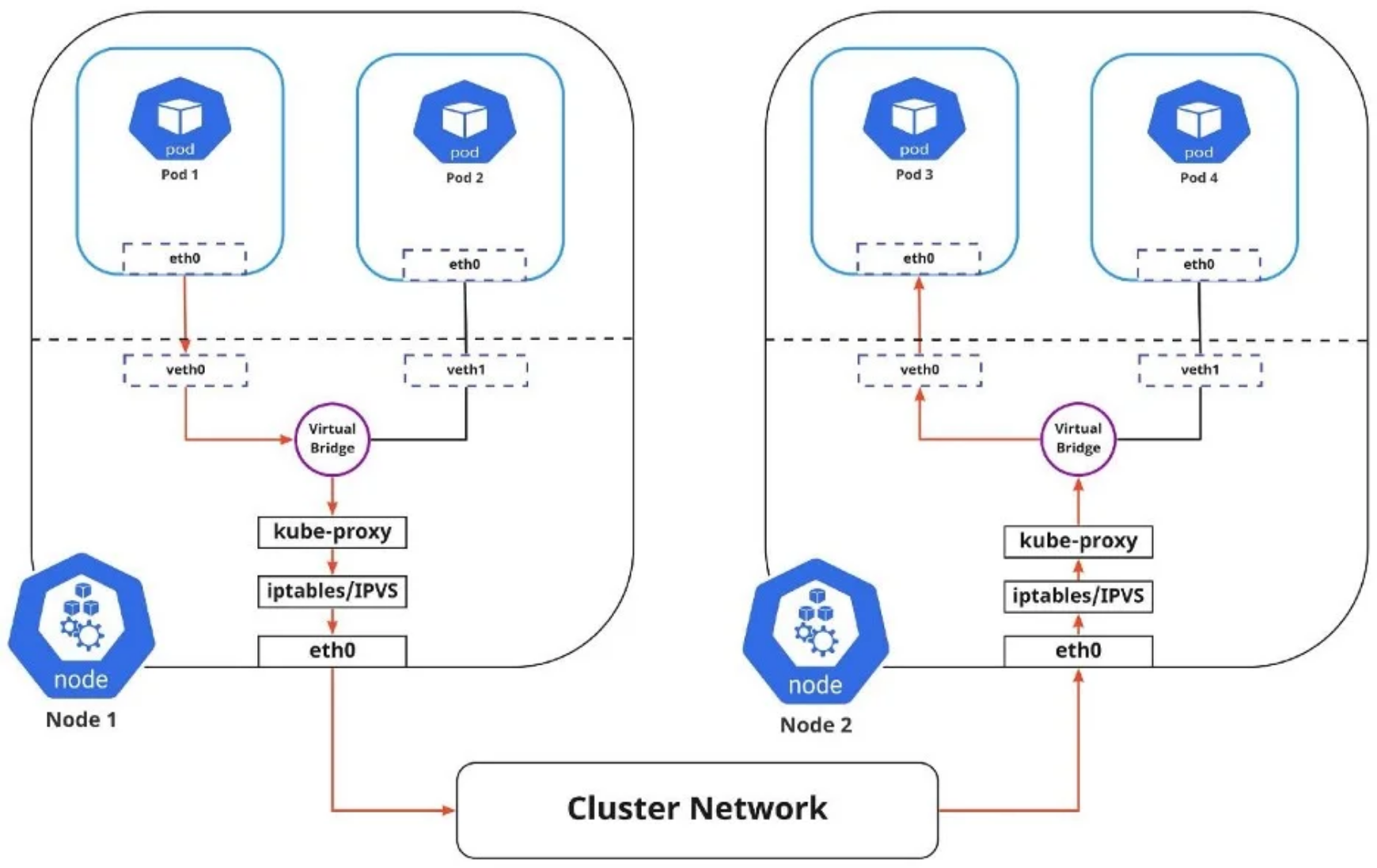
上图中显示,Pod要相互通信,流量必须在 Pod 网络命名空间和根网络命名空间(root network namespace)之间流动。这是通过虚拟以太网设备或veth对(图中veth0到Pod命名空间1,veth1到Pod命名空间2)连接Pod命名空间和根命名空间来实现的。虚拟网桥连接这些虚拟接口,允许流量使用地址解析协议(ARP) 在它们之间流动。
当数据从Pod 1发送到Pod 2时,事件流为:
- Pod 1流量通过eth0流向根网络命名空间的虚拟接口veth0。
- 然后,流量通过veth0到达连接到veth1的虚拟网桥。
- 流量通过虚拟网桥到达veth1。
- 最后,流量通过veth1到达Pod 2的eth0接口。
Pod-to-Service networking
虽然 pod 的 address 是唯一的,但是pod 是非常动态的。它们可能需要根据需求进行扩展或缩减。在应用程序崩溃或节点故障的情况下,可以重新创建它们。这些事件会导致Pod的IP地址发生变化,这将使联网成为一个挑战。
我们要解决 pod 的动态问题,那么就需要:
- 在前端分配静态虚拟IP地址(virtual IP:VIP),以连接与服务关联的任何后端Pod。
- 将寻址到此虚拟IP的任何流量负载平衡到后端Pod集。
- 跟踪Pod的IP地址,这样即使Pod IP地址发生变化,客户端也不会在连接Pod时遇到任何问题,因为它们只直接连接到服务本身的静态虚拟IP地址。
群集内负载平衡以两种方式进行:
Iptables:在此模式下,kube-proxy监视API服务器中的更改。对于每个新服务,它都安装iptables规则,这些规则捕获到服务的clusterIP和端口的流量,然后将流量重定向到服务的后端Pod。Pod是随机选择的。这种模式很可靠,而且系统开销较低,因为Linux Netfilter无需在用户空间和内核空间之间切换即可处理流量。IPVS:IPVS构建在Netfilter之上,实现传输层负载平衡。IPVS使用Netfilter Hook函数,使用hash tables作为底层数据结构,并在内核空间中工作。这意味着IPVS模式下的kube-proxy重定向流量比iptables模式下的kube-proxy具有更低的延迟、更高的吞吐量和更好的性能。
上图显示了从Pod 1到Pod 3,通过服务到不同节点(用红色标记)的包流。由于网桥上运行的 RPC 无法理解服务,因此传输到虚拟网桥的包必须使用默认路由(eth0)。稍后,必须通过iptables过滤这些包,iptables使用kube-proxy在节点中定义的规则。因此,图中显示的是路径。
Internet-to-Service networking
到目前为止,我已经讨论了如何在集群中路由流量。不过,Kubernetes网络还有另一面,那就是将应用程序暴露给外部网络。
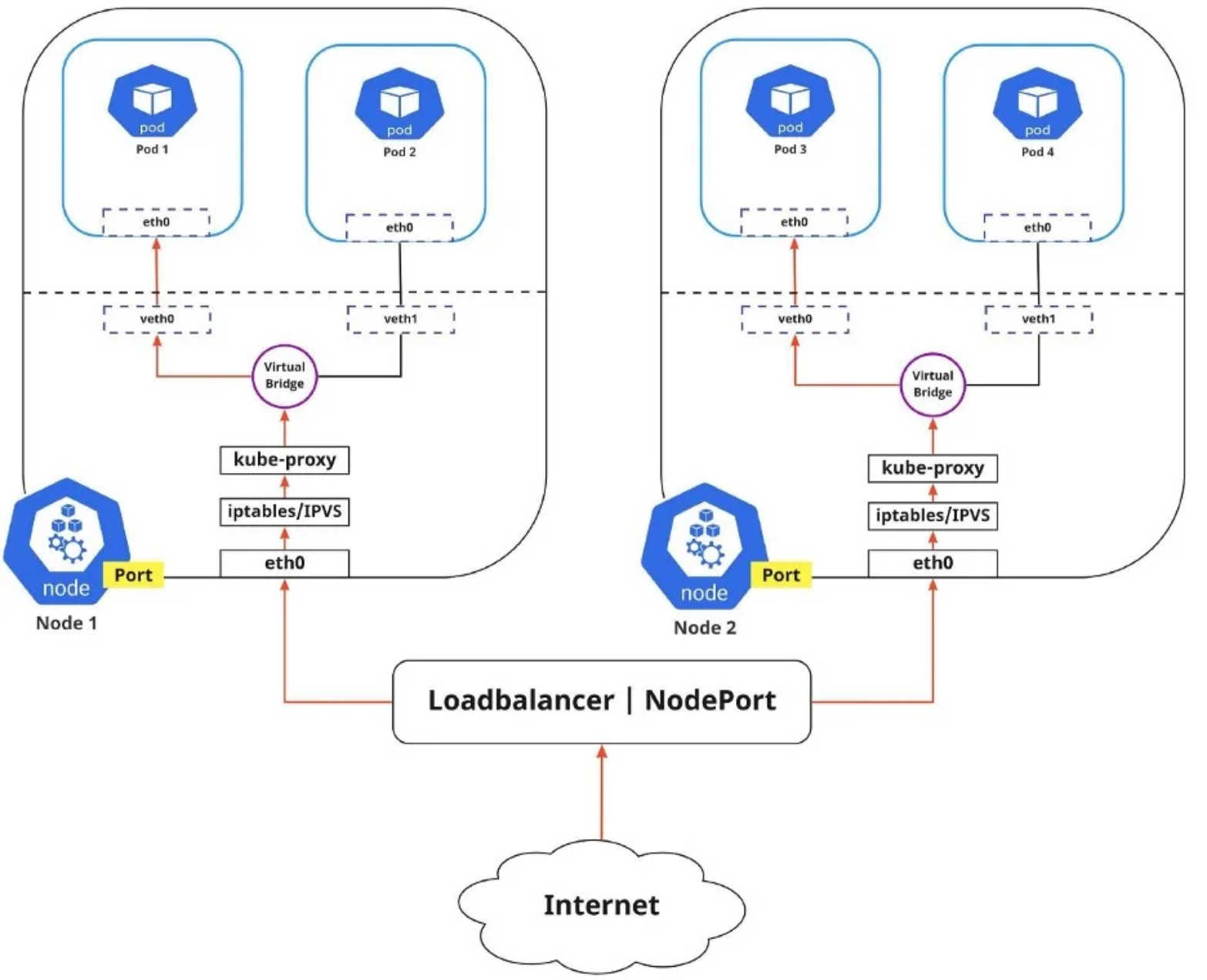
可以通过两种不同的方式将应用程序公开给外部网络:
- Egress:当您希望将流量从Kubernetes服务路由到Internet时,请使用此选项。在本例中,iptables执行源NAT,因此流量似乎来自节点而不是Pod。
- Ingress:这是从外部世界到服务的传入流量。入口还使用连接规则允许和阻止与服务的特定通信。通常,存在两种在不同网络堆栈区域上起作用的入口解决方案:服务负载均衡器和入口控制器。
服务发现(Discovering Services )
Kubernetes提供了一种机制来自动管理容器和服务之间的网络连接,这被称为服务发现。服务发现允许容器和服务互相发现彼此的存在和位置,从而使它们可以进行通信。
Kubernetes 服务发现的方式有两种:
- 环境变量:Pod所在节点上运行 的
kubelet服务负责为每个活动服务设置{SVCNAME}_SERVICE_HOST和{SVCNAME}_SERVICE_PORT格式的环境变量。必须在客户端Pod出现之前创建服务。否则,这些客户机Pod将不会填充其环境变量。 - DNS:DNS服务作为映射到一个或多个DNS服务器Pod的Kubernetes服务实现,这些Pod的调度与任何其他Pod一样。群集中的Pod配置为使用DNS服务,DNS搜索列表包括Pod自己的命名空间和群集的默认域。支持群集的DNS服务器(如CoreDNS)会监视Kubernetes API中的新服务,并为每个服务创建一组DNS记录。如果在整个群集中启用了DNS,则所有Pod都可以通过其DNS名称自动解析服务。Kubernetes DNS服务器是访问ExternalName服务的唯一途径。
此外,Kubernetes还提供了一些特殊的服务发现机制,以便更好地管理服务。例如,可以使用Kubernetes服务对象来定义一组相关的Pod,并为它们分配一个唯一的名称和IP地址。这使得其他服务可以使用该名称来访问这组Pod,而不必担心它们的IP地址会发生变化。
Kubernetes还支持在服务发现过程中使用负载均衡器,以便更好地管理流量。负载均衡器可以根据特定的规则将流量分发到多个容器或服务中,从而确保它们之间的负载均衡和高可用性。
另外,Kubernetes还支持自定义服务发现插件,以便更好地满足特定应用程序的需求。例如,可以使用自定义插件来实现跨多个Kubernetes集群的服务发现。
Kubernetes 服务发布
Kubernetes服务为你提供了一种访问Pod组的方法,通常使用标签选择器进行定义。这可能是试图访问集群中其他应用程序的应用程序,也可能允许您将集群中运行的应用程序公开给外部世界。Kubernetes 服务类型允许您指定所需的服务类型。
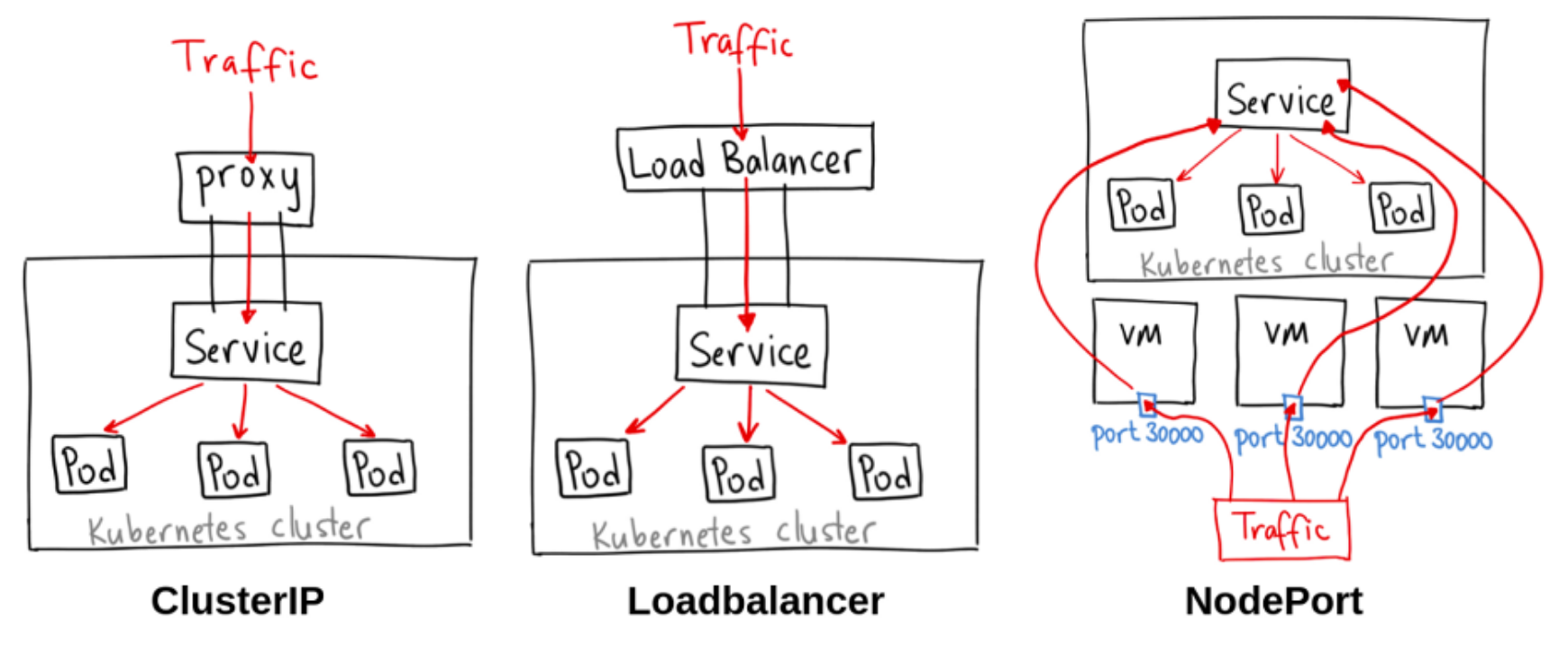
不同的服务类型包括:
- ClusterIP:这是默认的服务类型。它使服务只能从集群内访问,并允许集群内的应用程序相互通信。没有外部访问。
- LoadBalancer(负载均衡器):此ServiceType使用云提供商的负载平衡器向外部公开服务。来自外部负载平衡器的流量被定向到后端Pod。云提供商决定如何进行负载平衡。
- NodePort:这允许外部流量通过打开所有节点上的特定端口来访问服务。发送到该端口的任何流量随后将转发到服务。
- ExternalName(外部名称):此类型的服务通过使用externalName字段的内容将服务映射到DNS名称,方法是返回CNAME记录及其值。不设置任何类型的代理。
CNI
在任何Linux操作系统中,使用 ip 命令创建网络名称空间都非常容易。让我们创建两个不同的网络名称空间,并将它们命名为client和server。
❯ ip netns add client
❯ ip netns add server
❯ ip netns list
server
client
删除 namespace 命令:
ip netns delete <namespace_name>
创建 veth 对以连接这些网络命名空间。将 veth 线对视为两端都有连接器的网线(我们在前面讲过 veth)。
❯ ip link add veth-client type veth peer name veth-server
❯ ip link list | grep veth
12: veth-server@veth-client: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
13: veth-client@veth-server: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
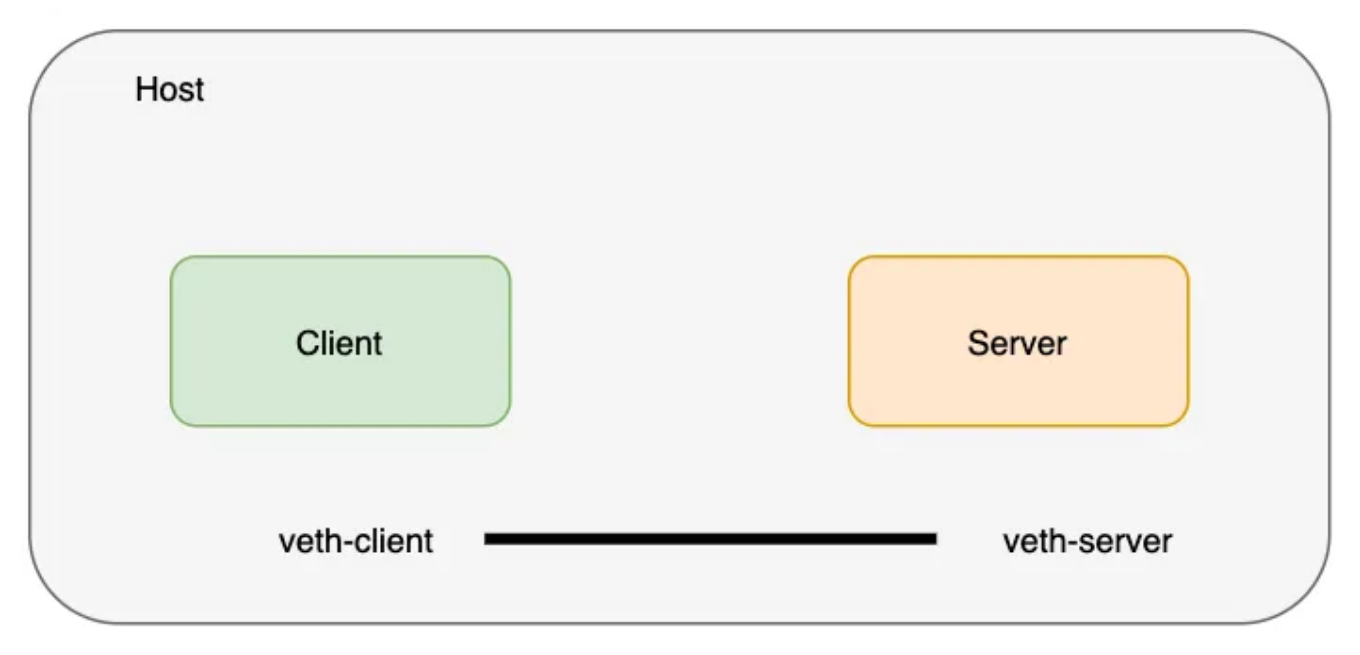
veth 对(电缆)存在于主机网络命名空间中,现在,让我们将 veth 对的两端移到前面创建的它们各自的名称空间中。
❯ ip link set veth-client netns client
❯ ip link set veth-server netns server
❯ ip link list | grep veth # doesn’t exist on the host network namespace now
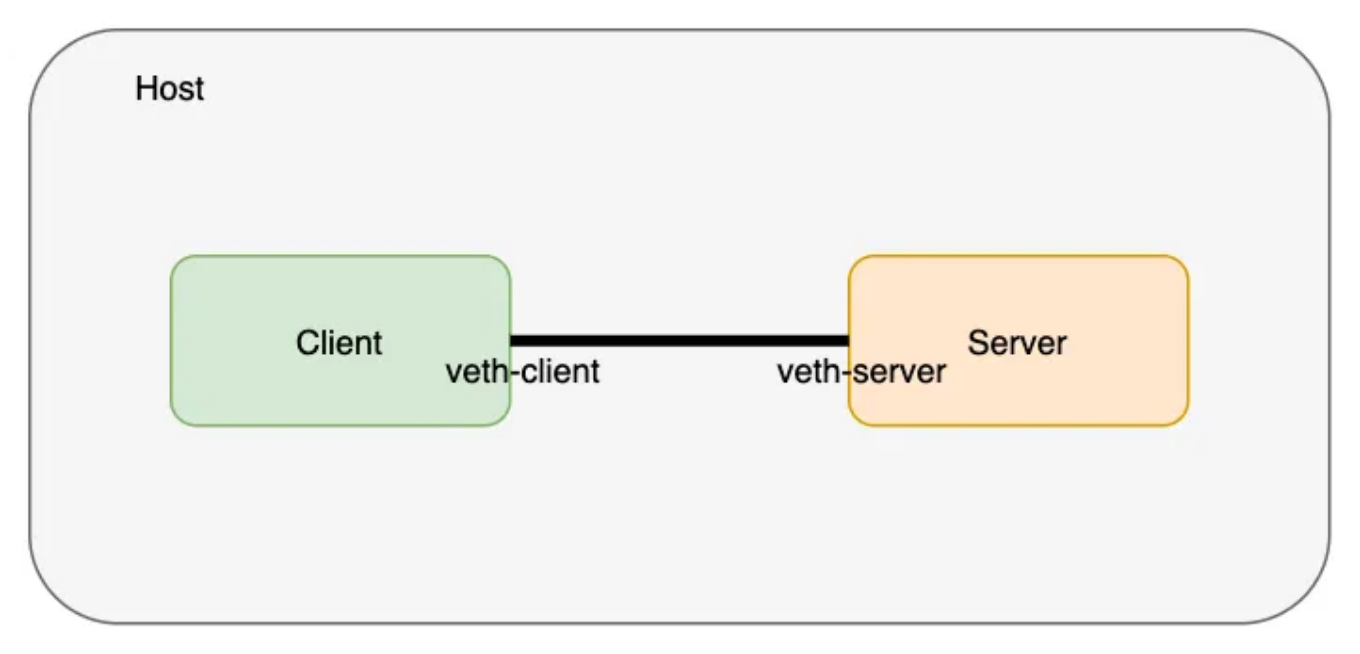
让我们验证 veth 结束实际上存在于名称空间中。我们将从 client 名称空间开始
❯ ip netns exec client ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
13: veth-client@if12: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 16:8c:9a:f4:34:5d brd ff:ff:ff:ff:ff:ff link-netns server
现在,让我们检查 server 名称空间
❯ ip netns exec server ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
12: veth-server@if13: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 4a:36:cf:93:eb:d3 brd ff:ff:ff:ff:ff:ff link-netns client
现在,让我们为这些接口分配IP地址并将其设置为启用状态
❯ ip netns exec client ip address add 10.0.0.11/24 dev veth-client
❯ ip netns exec client ip link set veth-client up
❯ ip netns exec server ip link set veth-server up
❯ ip netns exec server ip address add 10.0.0.12/24 dev veth-server
❯ ip netns exec client ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
13: veth-client@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 16:8c:9a:f4:34:5d brd ff:ff:ff:ff:ff:ff link-netns server
inet 10.0.0.11/24 scope global veth-client
valid_lft forever preferred_lft forever
inet6 fe80::148c:9aff:fef4:345d/64 scope link
valid_lft forever preferred_lft forever
继续看服务端 IP:
❯ ip netns exec server ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
12: veth-server@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 4a:36:cf:93:eb:d3 brd ff:ff:ff:ff:ff:ff link-netns client
inet 10.0.0.12/24 scope global veth-server
valid_lft forever preferred_lft forever
inet6 fe80::4836:cfff:fe93:ebd3/64 scope link
valid_lft forever preferred_lft forever
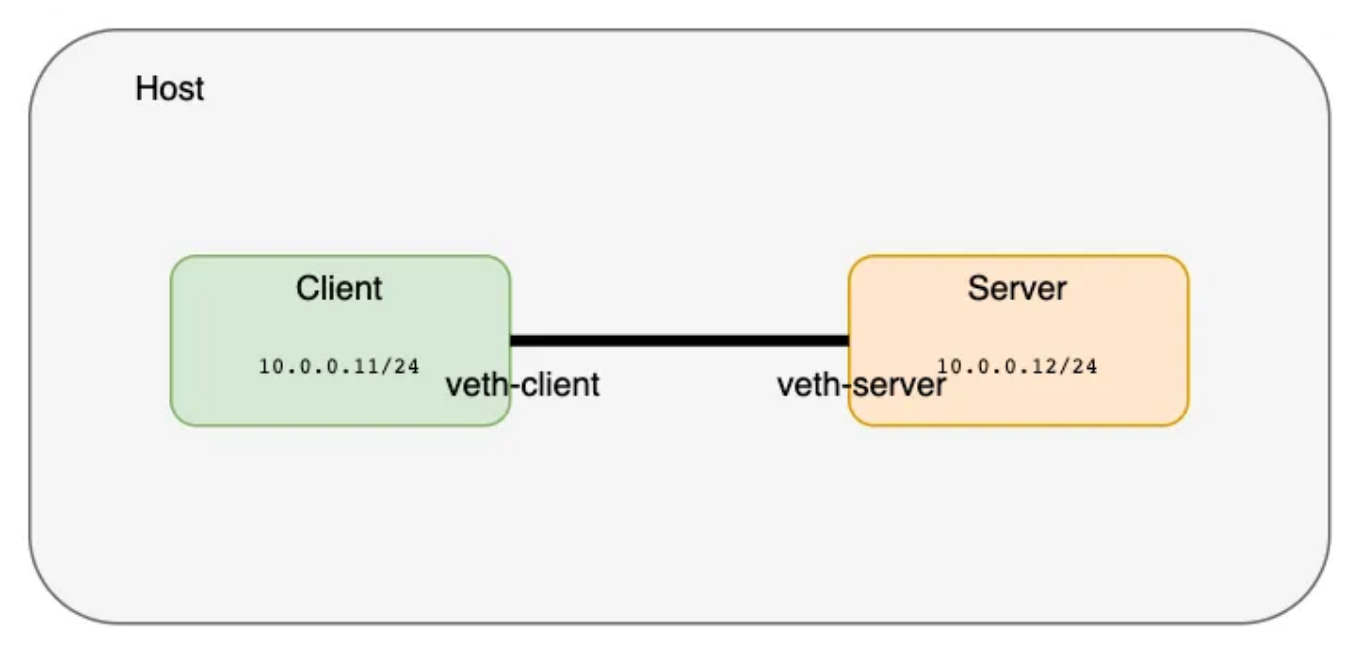
使用ping命令,我们可以验证两个网络名称空间已经连接并且可以访问,
❯ ip netns exec client ping 10.0.0.12
PING 10.0.0.12 (10.0.0.12) 56(84) bytes of data.
64 bytes from 10.0.0.12: icmp_seq=1 ttl=64 time=0.102 ms
64 bytes from 10.0.0.12: icmp_seq=2 ttl=64 time=0.036 ms
64 bytes from 10.0.0.12: icmp_seq=3 ttl=64 time=0.038 ms
64 bytes from 10.0.0.12: icmp_seq=4 ttl=64 time=0.037 ms
如果我们想创建更多的网络名称空间并将它们连接在一起,为名称空间的每个组合创建 veth 对可能不是一个可伸缩的解决方案。相反,可以创建一个Linux桥,并将这些网络名称空间连接到桥以获得连接。这正是Docker在同一主机上运行的容器之间建立网络的方式!
让我们创建名称空间并将其附加到 bridge。
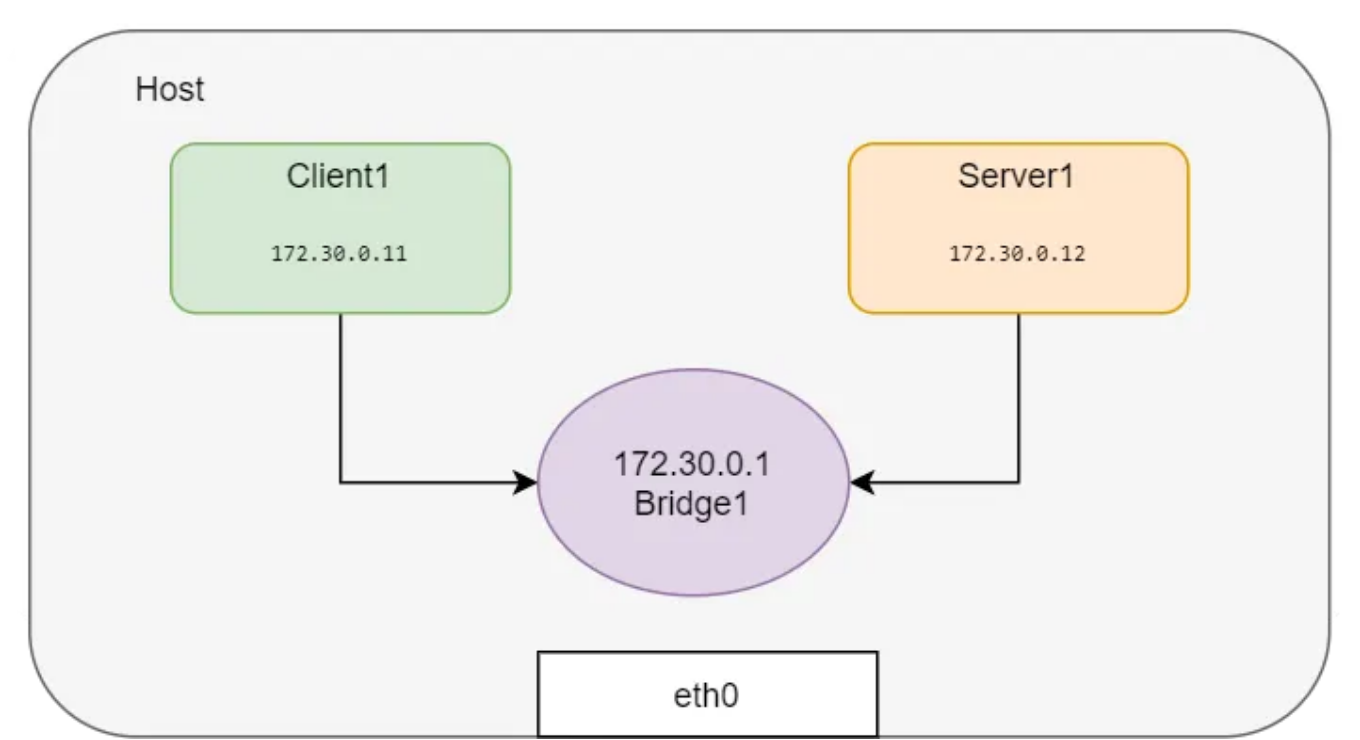
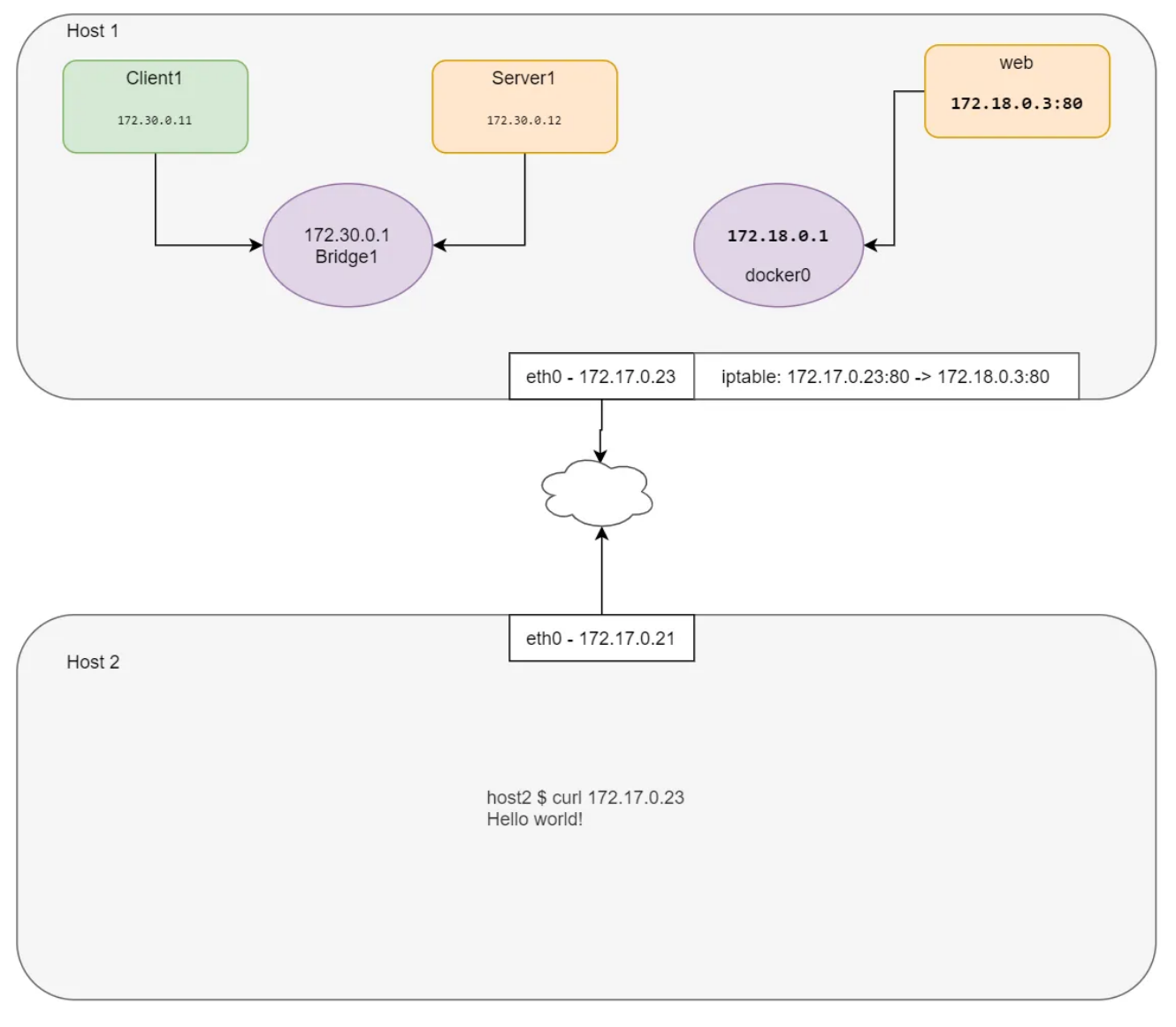
如何从外部服务器访问专用网络?
让我们使用Docker来模拟该场景。
$ docker run -d --name web --rm nginx
$ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
$ docker inspect web --format '{{ .NetworkSettings.SandboxKey }}'
/var/run/docker/netns/c009f2a4be71
由于Docker不会在默认位置创建 **netns** ,因此 **ip netns list** 不会显示此网络名称空间。我们可以创建一个指向预期位置的符号链接来克服这个限制。
client$ container_id=web
client$ container_netns=$(docker inspect ${container_id} --format '{{ .NetworkSettings.SandboxKey }}')
client$ mkdir -p /var/run/netns
client$ rm -f /var/run/netns/${container_id}
client$ ln -sv ${container_netns} /var/run/netns/${container_id}
'/var/run/netns/web' -> '/var/run/docker/netns/c009f2a4be71'
client$ ip netns list
web (id: 3)
server1 (id: 1)
client1 (id: 0)
检查Web名称空间中的IP地址
$ ip netns exec web ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
11: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.3/24 brd 172.18.0.255 scope global eth0
valid_lft forever preferred_lft forever
我们来检查一下Docker容器中的IP地址
$ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
client$ echo $WEB_IP
172.18.0.3
很明显,Docker使用所有Linux名称空间,并将内容与主机隔离。让我们尝试从HOST服务器访问在web网络名称空间中运行的WebApp。
client$ curl $WEB_IP
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
是否可以从外部网络访问此Web服务器?是的,通过添加端口转发。
$ iptables -t nat -A PREROUTING -p tcp --dport 80 -j
$ echo $HOST_IP
172.17.0.23
让我们尝试使用主机IP地址访问Web服务器。
$ curl 172.17.0.23
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
node01 $
CNI
“CNI插件负责将网络接口插入容器网络名称空间(例如,veth对的一端),并在主机上进行任何必要的更改(例如,将veth的另一端连接到网桥)。然后,它应将IP分配给接口,并通过调用相应的IPAM插件设置与IP地址管理部分一致的路由。”
CNI(容器网络接口)是云原生计算基金会的一个项目,由一个规范和库组成,用于编写插件来配置Linux容器中的网络接口,沿着许多受支持的插件。CNI只关心容器的网络连通性,并在删除容器时移除分配的资源。由于这一重点,CNI得到了广泛的支持,并且规范易于实现。
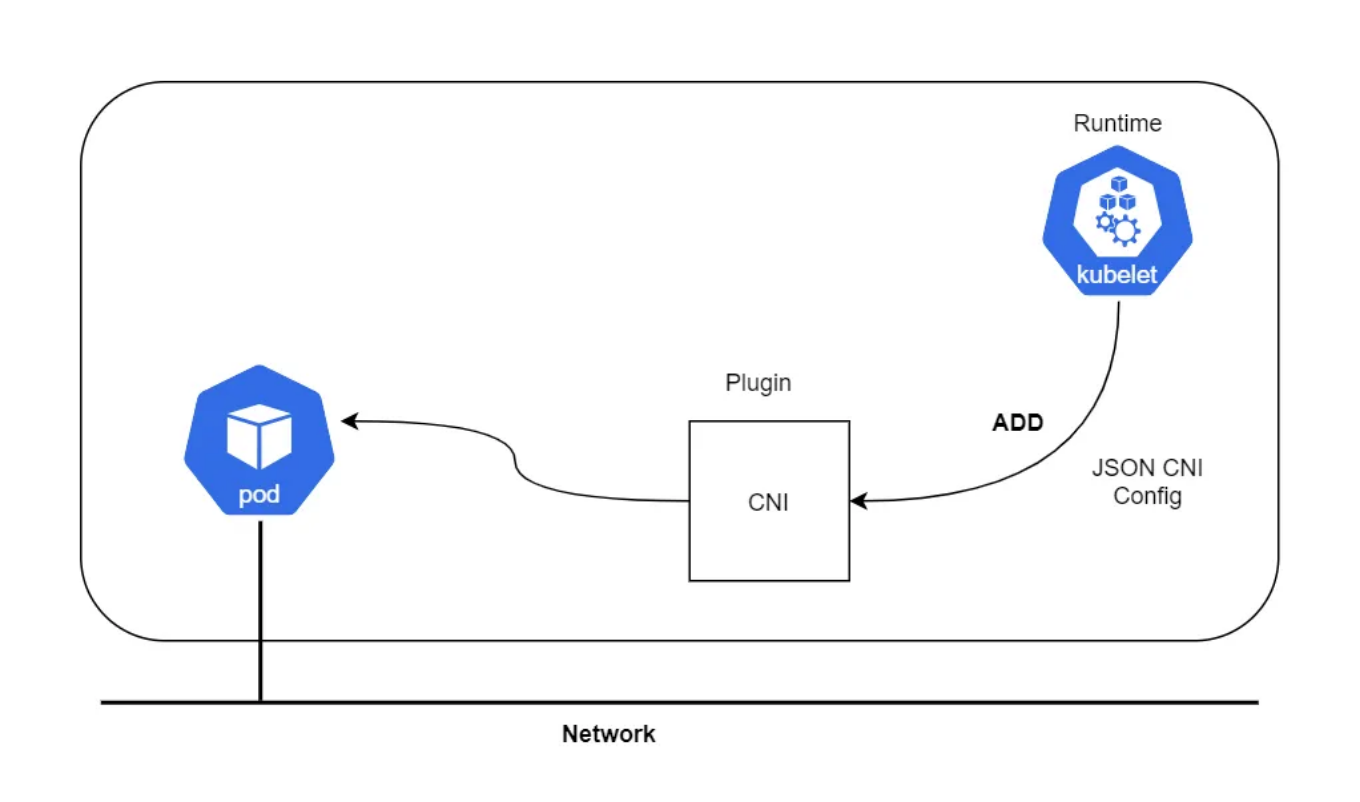
注意:运行时可以是任何东西-例如 Kubernetes, PodMan, cloud foundry, etc
创建 CNI
步骤1:下载CNI插件
client$ mkdir cni
client$ cd cni
client$ curl -O -L https://github.com/containernetworking/cni/releases/download/v0.4.0/cni-amd64-v0.4.0.tgz
client$ tar -xvf cni-amd64-v0.4.0.tgz
步骤2:创建JSON格式的CNI配置
cat > /tmp/00-demo.conf <<"EOF"
{
"cniVersion": "0.2.0",
"name": "demo_br",
"type": "bridge",
"bridge": "cni_net0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.0.10.0/24",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "1.1.1.1/32", "gw":"10.0.10.1"}
]
}
}
EOF
CNI配置参数
-:CNI generic parameters:-
cniVersion: The version of the CNI spec in which the definition works with
name: The network name
type: The name of the plugin you wish to use. In this case, the actual name of the plugin executable
args: Optional additional parameters
ipMasq: Configure outbound masquerade (source NAT) for this network
ipam:
type: The name of the IPAM plugin executable
subnet: The subnet to allocate out of (this is actually part of the IPAM plugin)
routes:
dst: The subnet you wish to reach
gw: The IP address of the next hop to reach the dst. If not specified the default gateway for the subnet is assumed
dns:
nameservers: A list of nameservers you wish to use with this network
domain: The search domain to use for DNS requests
search: A list of search domains
options: A list of options to be passed to the receiver
步骤3:创建一个网络为“none”的容器,这样容器就不会有任何IP地址可供使用。您可以为这个容器使用任何图像,但是,我使用'pause'容器来模拟Kubernetes。
controlplane $ docker run --name pause_demo -d --rm --network none kubernetes/pause
controlplane $ container_id=pause_demo
controlplane $ container_netns=$(docker inspect ${container_id} --format '{{ .NetworkSettings.SandboxKey }}')
controlplane $ mkdir -p /var/run/netns
controlplane $ rm -f /var/run/netns/${container_id}
controlplane $ ln -sv ${container_netns} /var/run/netns/${container_id}
'/var/run/netns/pause_demo' -> '/var/run/docker/netns/0297681f79b5'
controlplane $ ip netns list
pause_demo
controlplane $ ip netns exec $container_id ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 erbashrors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
步骤4:使用CNI配置文件调用CNI插件
$ CNI_CONTAINERID=$container_id CNI_IFNAME=eth10 CNI_COMMAND=ADD CNI_NETNS=/var/run/netns/$container_id CNI_PATH=`pwd` ./bridge </tmp/00-demo.conf
2020/10/17 17:32:37 Error retriving last reserved ip: Failed to retrieve last reserved ip: open /var/lib/cni/networks/demo_br/last_reserved_ip: no such file or directory
{
"ip4": {
"ip": "10.0.10.2/24",
"gateway": "10.0.10.1",
"routes": [
{
"dst": "0.0.0.0/0"
},
{
"dst": "1.1.1.1/32",
"gw": "10.0.10.1"
}
]
},
"dns": {}
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©