第46节 深挖容器底层技术
❤️💕💕新时代拥抱云原生,云原生具有环境统一、按需付费、即开即用、稳定性强特点。Myblog:http://nsddd.top
[TOC]
linux kernel 中 namespace 的实现
进程数据结构
struct task_struct {
...
/ * namespaces */
struct nsproxy *nsproxy;
...
}
Linux Namespce 是一种 Linux Kernel 提供的资源隔离方案:
- 系统可以为不同进程分配不同的 Namespace
- 系统可以保证不同的 Namespaces 资源独立分配,进程彼此隔离,即不同的 Namespace 下进程互不干扰。
即使是在 Kubernetes 中,任何进程运行都是需要一个 namespaces
namespace 数据结构
具体细节不展开,之前写过很多关于 namespces 的文章(https://docker.nsddd.top)
/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* The pid namespace is an exception -- it's accessed using
* task_active_pid_ns. The pid namespace here is the
* namespace that children will use.
*
* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
*
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied.
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};
extern struct nsproxy init_nsproxy;
我们会以 namespces 为例,即使是其他的,比如说 联合文件系统,我们之前写过一篇文章讲过,可以参考那篇文章
我在网上找到了不同 kernel 版本对应的 namespace ,作为参考
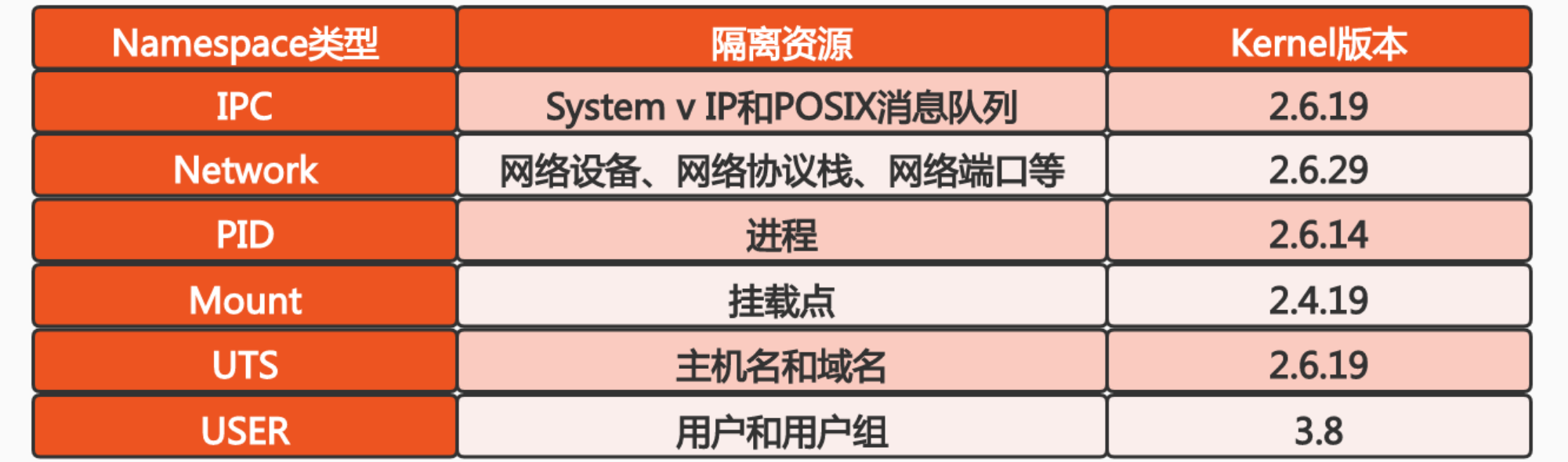
查看和操控主机的 Namespace
查看当前系统的 namespace:
lsns -t <type>
-t选项:只查看给定类型的Namespace
查看某一个进程的 namespace:
ls -al /proc/<pid>/ns/
进入某一个 namespace 运行命令:
nsenter -t <pid> -n ip addr
nsenter:可以在指定进程的Namespace下运行指定程序的命令-t选项:指定被进入命名空间的目标进程的pid-m选项:进入mnt Namespace-u选项:进入uts Namespace-i选项:进入ipc Namespace-n选项:进入net Namespace-p选项:进入pid Namespace-U选项:进入user Namespace-G选项:设置运行程序的gid-S选项:设置运行程序的uid-r选项:设置根目录-w选项:设置工作目录
int setns(int fd, int nstype)
该系统调用可以让调用进程加入某个已经存在的Namespace中.
setns可以调整一个已经存在的进程,将该进程切换到另一个Namespace中.
unshare
该系统调用可以将调用进程移动到新的Namespace下:
int unshare(int flags)
案例
查找 主进程 的 namespace:
❯ lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531992 net 270 1 root unassigned /run/docker/netns/default /sbin/init text
❯ ls -al /proc/1/ns
total 0
dr-x--x--x 2 root root 0 Mar 2 07:47 .
dr-xr-xr-x 9 root root 0 Feb 26 05:15 ..
lrwxrwxrwx 1 root root 0 Mar 2 08:06 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Mar 2 08:06 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Mar 2 08:06 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 root root 0 Mar 2 08:06 net -> 'net:[4026531992]'
lrwxrwxrwx 1 root root 0 Mar 2 07:47 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Mar 2 08:06 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Mar 2 08:06 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Mar 2 08:06 uts -> 'uts:[4026531838]'
在我们使用 docker 的时候,我们可以用 docker run / exec 进入一个容器,当然也可以用 nsenter,不过我们用的是 PID(0) system init 主进程测试的:
聪明的你应该猜到了,主进程的话,那必然也是一样的(因为我平常不用 docker 了,所以只是将 docker 作为 runtime),如下:
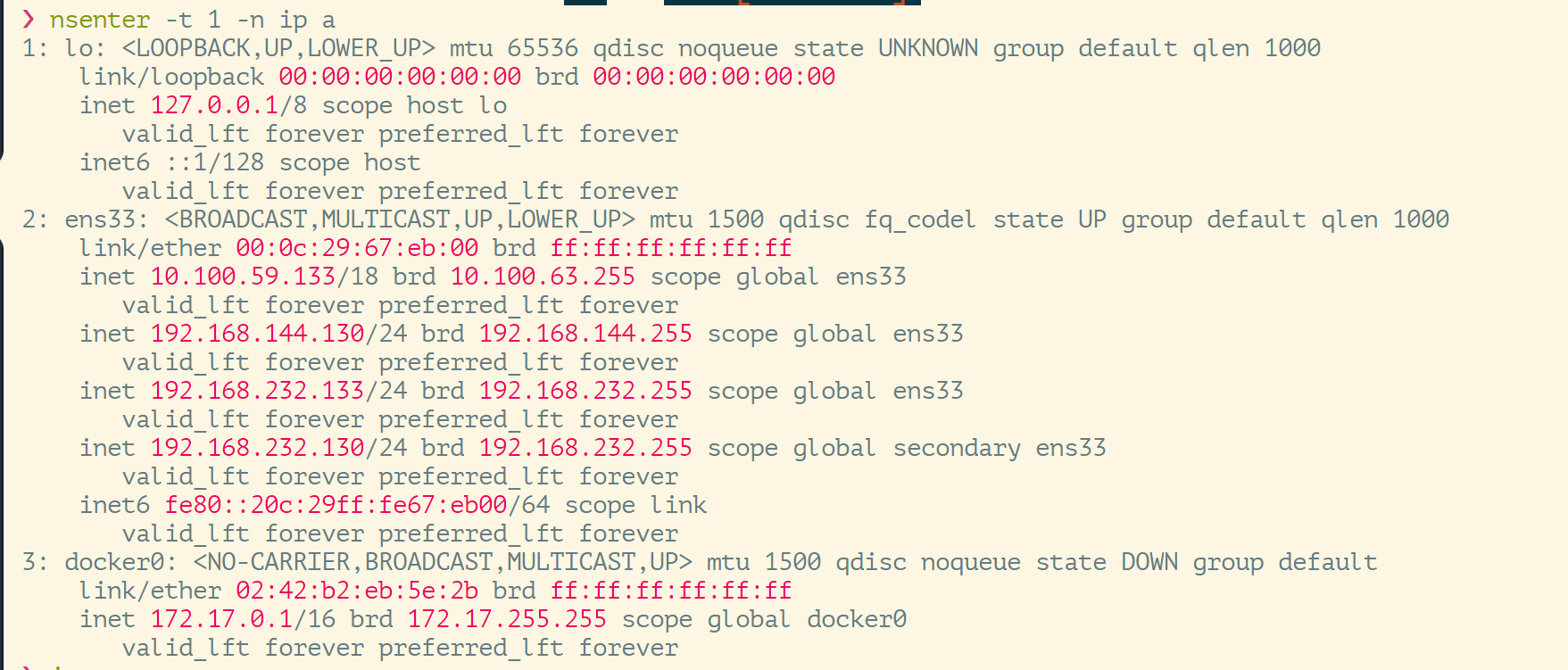
这和我们进入 容器 中,在输入 ip addr 结果是一样的,网络隔离的效果一样。
我们后面 Kubernetes 调试容器也是经常用到的。
我以网络为例,其他的 namespace 也是一样的:
ipc Namespace- 容器中进程交互还是采用Linux常见的进程间交互(interprocess communication - IPC)方法,包括常见的信号量、消息队列和共享内存
- 容器的进程间交互,实际上还是宿主机上在同一个Pid namespace中的进程间交互,因此需要在IPC资源申请时加入namespace信息.每个IPC资源有一个唯一的32位ID
如果需要进程间通信(比如要发送信号量、要共享内存),这种场景就需要通过IPC通信来完成.2个进程想要进行IPC通信,必须处于同一个ipc namespace中.
mnt Namespace- mnt Namespace允许不同namespace的进程看到不同的文件结构,这样每个namespace中的进程所看到的文件目录就被隔离开了
每个进程都有自己的文件系统.从代码的角度来看,结构体
task_struct中有如下几个字段:struct mm_struct *mm, *active_mm;struct fs_struct *fs;(文件系统信息)struct files_struct *files;(打开文件信息)struct signal_struct *signal(信号量信息)struct sighand_struct *sighand;(信号处理对象)
mnt Namespace决定了
task_struct的实例(也就是1个进程)能够看到的文件系统.因此每个进程能够看到的文件系统也是不同的.UTS Namespace- UTS(UNIX Time-sharing System) Namespace允许每个容器拥有独立的hostname和domain name,使其在网络上可以被视作一个独立的节点,而非宿主机上的一个进程.
UTS Namespace决定了每个进程可以有其专属的主机域名.配合net Namespace,每个进程就拥有了自己独立的主机域名和IP地址
user Namespace- 每个容器可以有不同的user和group id,也就是说可以在容器内部,以容器内部用户的角色执行程序.而非以宿主机上的用户角色来执行容器内的程序.
user Namespace用于让每个进程可以有自己的用户管理系统.
⚠️ 我还是想提醒一下,或许你看过我的文章,或许你可以去 Wiki 上面看,因为 namespace 出现时间不一样,所以不能一概而论。
unshare
好熟悉的地方不是吗,或许你看过我以前的文章,里面提到过
unshare: unshare 允许进程在运行时创建和隔离新的命名空间。例如,可以使用 unshare 创建一个新的 PID 命名空间,从而使一个进程在新的命名空间中运行,并且与原来的命名空间隔离。newuidmap: newuidmap 工具用于在容器中控制用户 ID 映射,这是实现容器的必要步骤。在容器中,需要在主机和容器间进行用户 ID 的映射,以便使容器中的进程具有访问文件系统的权限。
create a new PID:
也就是说这条命令的含义是:启动一个进程sleep,并切换该进程的net Namespace
❯ unshare -fn sleep 60
test:
unshare -U bash
-f:切换Namespace-n:指定切换net Namespace
ok,我们来测试一下这个💡简单的一个案例如下:
❯ unshare -n bash
root@cubmaster01:/# lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531992 net 266 1 root unassigned /run/docker/netns/default /sbin/init text
4026532657 net 2 948916 root unassigned bash
root@cubmaster01:/# ls -al /proc/948916/ns
total 0
dr-x--x--x 2 root root 0 Mar 2 08:16 .
dr-xr-xr-x 9 root root 0 Mar 2 08:16 ..
lrwxrwxrwx 1 root root 0 Mar 2 08:16 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Mar 2 08:16 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Mar 2 08:16 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 root root 0 Mar 2 08:16 net -> 'net:[4026532657]'
lrwxrwxrwx 1 root root 0 Mar 2 08:16 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Mar 2 08:16 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Mar 2 08:16 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Mar 2 08:16 uts -> 'uts:[4026531838]'
root@cubmaster01:/# ns
nscd nsenter nslookup nstat nsupdate
root@cubmaster01:/# nsenter -t 948916 -n ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@cubmaster01:/# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@cubmaster01:/# exit
exit
root@cubmaster01 / 2m 15s 08:18:01
❯
⚠️ 关于Kubernetes namespace 的通信问题以及 Linux namespace 通信问题,我写过一篇文章,请移步到这里
Cgroups
但是我们今天进一步学习,刨析它的底层实现:
- Cgroups(Control Groups)是Linux下用于对一个或一组进程进行资源控制和监控的机制
- 可以对诸如CPU使用时间、内存、磁盘I/O等进程所需资源进行限制
- 不同资源的具体管理工作由相应的Cgroup子系统(Subsystem)来实现
- 针对不同类型的资源限制,只要将限制策略在不同的子系统上进行关联即可
- Cgroups在不同的系统资源管理子系统中,以层级树(Hierarchy)的方式来组织管理:每个Cgroup都可以包含其他的子Cgroup,因此子Cgroup能使用的资源除了受本Cgroup配置的资源参数限制外,还受到父Cgroup设置的资源限制
Cgroups用于对Linux中的进程做统一的监控和资源管理.
Cgroups也分为不同的子系统,不同的子系统会控制不同的资源.一个进程所需的资源大约可以分为:CPU、内存、Disk I/O.这些资源都可以被Cgroups管理起来.这些资源在Cgroups中被称为Subsystem.
进程是一个树状结构.Cgroups也采用了类似的结构,叫做Hierarchy.
进程数据结构
struct task_struct {
...
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
struct list_head cg_list;
#endif
...
}
css_set 数据结构
css_set 是 cgroup_subsys_state 对象的集合数据结构
/*
* A css_set is a structure holding pointers to a set of
* cgroup_subsys_state objects. This saves space in the task struct
* object and speeds up fork()/exit(), since a single inc/dec and a
* list_add()/del() can bump the reference count on the entire cgroup
* set for a task.
*/
struct css_set {
/*
* Set of subsystem states, one for each subsystem. This array is
* immutable after creation apart from the init_css_set during
* subsystem registration (at boot time).
*/
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
/* reference count */
refcount_t refcount;
/*
* For a domain cgroup, the following points to self. If threaded,
* to the matching cset of the nearest domain ancestor. The
* dom_cset provides access to the domain cgroup and its csses to
* which domain level resource consumptions should be charged.
*/
struct css_set *dom_cset;
/* the default cgroup associated with this css_set */
struct cgroup *dfl_cgrp;
/* internal task count, protected by css_set_lock */
int nr_tasks;
/*
* Lists running through all tasks using this cgroup group.
* mg_tasks lists tasks which belong to this cset but are in the
* process of being migrated out or in. Protected by
* css_set_rwsem, but, during migration, once tasks are moved to
* mg_tasks, it can be read safely while holding cgroup_mutex.
*/
struct list_head tasks;
struct list_head mg_tasks;
struct list_head dying_tasks;
/* all css_task_iters currently walking this cset */
struct list_head task_iters;
/*
* On the default hierarchy, ->subsys[ssid] may point to a css
* attached to an ancestor instead of the cgroup this css_set is
* associated with. The following node is anchored at
* ->subsys[ssid]->cgroup->e_csets[ssid] and provides a way to
* iterate through all css's attached to a given cgroup.
*/
struct list_head e_cset_node[CGROUP_SUBSYS_COUNT];
/* all threaded csets whose ->dom_cset points to this cset */
struct list_head threaded_csets;
struct list_head threaded_csets_node;
/*
* List running through all cgroup groups in the same hash
* slot. Protected by css_set_lock
*/
struct hlist_node hlist;
/*
* List of cgrp_cset_links pointing at cgroups referenced from this
* css_set. Protected by css_set_lock.
*/
struct list_head cgrp_links;
/*
* List of csets participating in the on-going migration either as
* source or destination. Protected by cgroup_mutex.
*/
struct list_head mg_src_preload_node;
struct list_head mg_dst_preload_node;
struct list_head mg_node;
/*
* If this cset is acting as the source of migration the following
* two fields are set. mg_src_cgrp and mg_dst_cgrp are
* respectively the source and destination cgroups of the on-going
* migration. mg_dst_cset is the destination cset the target tasks
* on this cset should be migrated to. Protected by cgroup_mutex.
*/
struct cgroup *mg_src_cgrp;
struct cgroup *mg_dst_cgrp;
struct css_set *mg_dst_cset;
/* dead and being drained, ignore for migration */
bool dead;
/* For RCU-protected deletion */
struct rcu_head rcu_head;
};
Tip:
cgroup 主要隔离的是 CPU 资源,我们知道即使是在 Kubernetes 中,参考 《深入剖析kubernetes》 这本书的 L 314
Kubernetes 对 CPU 和 内存资源限额的设计,也是参考了 Borg 动态资源定义 调度的。使用 requests + limits 做法。
cgroups实现了对资源的配额和度量
- blkio:该子系统用于限制每个块设备的输入输出控制.如:磁盘、光盘以及USB等
- cpu:该子系统通过调度程序为cgroup任务提供CPU访问
- cpuacct:产生cgroup任务的CPU资源报告
- cpuset:如果是多核心的CPU,该子系统为cgroup任务分配单独的CPU和内存
- divices:允许或拒绝cgroup任务对设备的访问
- freezer:暂停和恢复cgroup任务
- memory:设置每个cgroup的内存限制以及产生内存资源报告
- net_cls:标记每个网络包以供cgroup方便使用
- ns:命名空间子系统
- pid:进程标识子系统
blkio:即block IO.该子系统用于控制读写磁盘的速度
cpu:设置为该进程分配多少CPU的时间片
cpuacct:用于汇报CPU的状态
cpuset:用于在多CPU场景下,将某个进程绑定在某个CPU核心上.其目的是为了高效.1个进程的生命周期就和1个CPU核心绑定,对于CPU核心来讲不需要做进程切换,提高效率(比如CPU本地的cache,TLB表等都是可以复用的,减少进程切换的开销).
memory:控制一个进程可使用的内存大小
CPU 子系统
cpu.shares:可出让的能获得CPU使用时间的相对值cpu.cfs_period_us:cfs_period_us用于配置时间周期长度,单位为μs(微秒)cpu.cfs_quota_us:cfs_quota_us用于配置当前Cgroup在cfs_period_us时间内最多能使用的CPU时间数,单位为μs(微秒)cpu.stat:Cgroup内的进程使用的CPU时间统计nr_periods:经过cpu.cfs_period_us的时间周期数量nr_throttled:在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制throttled_time:Cgroup中的进程被限制使用CPU的总用时,单位为ns(纳秒)
CPU子系统用于控制1个进程能占用多少CPU.通过2种手段控制:
cpu.shares:相对时间cpu.cfs_period_us:绝对时间
用于控制进程占用CPU的文件:
❯ tree -L 1 /sys/fs/cgroup/cpu
/sys/fs/cgroup/cpu
├── cgroup.clone_children
├── cgroup.procs
├── cgroup.sane_behavior
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_all
├── cpuacct.usage_percpu
├── cpuacct.usage_percpu_sys
├── cpuacct.usage_percpu_user
├── cpuacct.usage_sys
├── cpuacct.usage_user
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpudemo
├── cpu.shares
├── cpu.stat
├── init.scope
├── kubepods.slice
├── notify_on_release
├── release_agent
├── system.slice
├── tasks
└── user.slice
5 directories, 18 files
cpu.shares
shares顾名思义就是占比,是一个相对值。
设现有3个CPU,2个CGroup(我们将它命名为Cgroup1和Cgroup2),2个进程(我们将它命名为进程A和进程B).
将进程A放在CGroup1中,将进程B放在CGroup2中,此时进程和CGroup就产生关联关系了.
将CGroup1的cpu.shares设置为512,将CGroup2的cpu.shares设置为1024.512:1024=1:2.这表示OS在调用这2个进程时,会按照1:2的比例分配CPU时间片.因此说shares是一个相对值.
cpu.cfs_periods_us
这种方式是控制进程对CPU占用的绝对时间.需要2个文件来控制.
cpu.cfs_periods_us:配置时间周期的长度.cpu.cfs_quota_us:配置在cpu.cfs_periods_us所定义的时间长度内,进程最多可以占用CPU的时长.
二者区别
cpu.shares定义的是一个相对值.如果在多个进程竞争CPU资源的场景下,按照其定义的百分比划分CPU占用时长.如果没有竞争,则该进程可以一直占用CPU.
cpu.cfs_periods_us是绝对时间.无论是否存在其他进程与该进程竞争CPU资源,按照上文举的例子来讲,每100000μs中,该进程都只能占用40000μs的CPU.
Linux 调度器
内核默认提供了 5 个调度器,Linux 内核使用 struct sched_class 来对调度器进行抽象,关于 Linux 内核调度器的研究,我也曾经 摘抄过一篇文章
- Stop调度器,
stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占 - Deadline调度器,
dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行 - RT调度器,
rt_sched_class:实时调度器,为每个优先级维护一个队列 - CFS调度器,
cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间的概念 - IDLE-Task调度器,
idle_sched_class:空闲调度器,每个CPU都会有1个idle线程,当没有其他进程可以调度时,调度运行idle线程
Linux中提供多个调度器.最高优先级的是RT(Real Time)调度器.这个调度器是轮询的.假设有多个进程使用RT调度器来调度,那么RT调度器将使用轮询的策略来调度这些进程.这样是为了保证时效性
优先级上其次是CFS(Completely Fair Scheduler,完全公平调度器)调度器.通常普通用户进程都是使用CFS调度器来调度的.CFS引入了一个vruntime(虚拟运行时间)的概念,是平时遇到的最多的调度器
其中,CFS 调度器, 对应 cfs_sched_class : 完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念(vruntime)
CFS 调度没有将进程维护在运行
CFS调度器原理
- CFS是Completely Fair Scheduler的简写,即完全公平调度器
- CFS实现的主要思想是维护为任务提供处理器时间方面的平衡,这意味着应该给进程分配相当数量的处理器
- 分给某个任务的时间失去平衡时,应该给失去平衡的任务分配时间,以便让该任务执行
- CFS通过vruntime(虚拟运行时间)来实现平衡,维护提供给某个任务的时间量
- vruntime = 实际运行时间 * 1024 / 进程权重
- 进程按照各自不同的速率在物理时钟节拍内前进,优先级高则权重大,其虚拟时钟比真实时钟跑得慢,但获得比较多的运行时间
也就是说,一个进程的权重越大,那么该进程的虚拟时钟(vruntime)跑的越慢,就能够获得越长的运行时间.
runtime红黑树
CFS调度器并没有将进程维护在运行队列中,而是维护了一个以虚拟运行时间为顺序的红黑树.红黑树的主要持有点有:
- 自平衡,树上没有任何一条路径,会比其他路径长出2倍
- O(log n)时间复杂度,能够在树上进行快读高效地插入或删除操作
CFS进程调度
在时钟周期开始时,调度器用
__schedule()函数来开始调度的运行__schedule()函数调用pick_next_task()让进程调度器从就绪队列中选择一个最合适的进程next,即红黑树最左边的节点(也就是vruntime最小的进程)通过
context_switch()切换到新的地址空间,从而保证让next进程运行在时钟周期结束时,调度器调用
entity_tick()函数来更新进程负载、进程状态以及vruntime(当前vruntime + 该时钟周期内运行的时间)
- 在这个时钟周期内,有的进程运行了,而有的进程没有运行.那此时需要更新vruntime,然后根据更新后的vruntime做一个顺序上的调整(也就是红黑树通过插入和反转等操作进行重新排序),调整后会把一个更紧迫的进程放在红黑树的最左侧.
- 进程优先级越高的进程,按照公式
vruntime = 实际运行时间 * 1024 / 进程权重,其vruntime值越小.vruntime值越小说明该进程越紧迫,即该进程可以占用更多的时间.这样vruntime和cpu.shares就产生了一个关联关系:cpu.shares占比越大的进程,能占有CPU的时间就越长
最后将该进程的虚拟时间与就绪队列红黑树最左边的调度实体的虚拟时间作比较,如果小于最左边的时间,则不用触发调度,继续调度当前调度实体
……
更多的,我们可以深挖 Kubernetes 调度器,以及 Linux 调度器问题,我们介绍表面层。
- 关于 深挖 Linux CPU 调度器,我也摘抄过一篇文章
案例
在/sys/fs/cgroup/cpu下,创建目录cpudemo并进入:

惊讶的发现:可以看到控制文件被自动创建出来了
我们继续:创建一个go文件,在该go文件中,启动2个死循环,1个死循环跑在主线程上,另一个跑在子线程上
继续:编译并运行该程序.运行的同时再起一个连接执行top命令
❯ go build busyloop.go
❯ ./busyloop
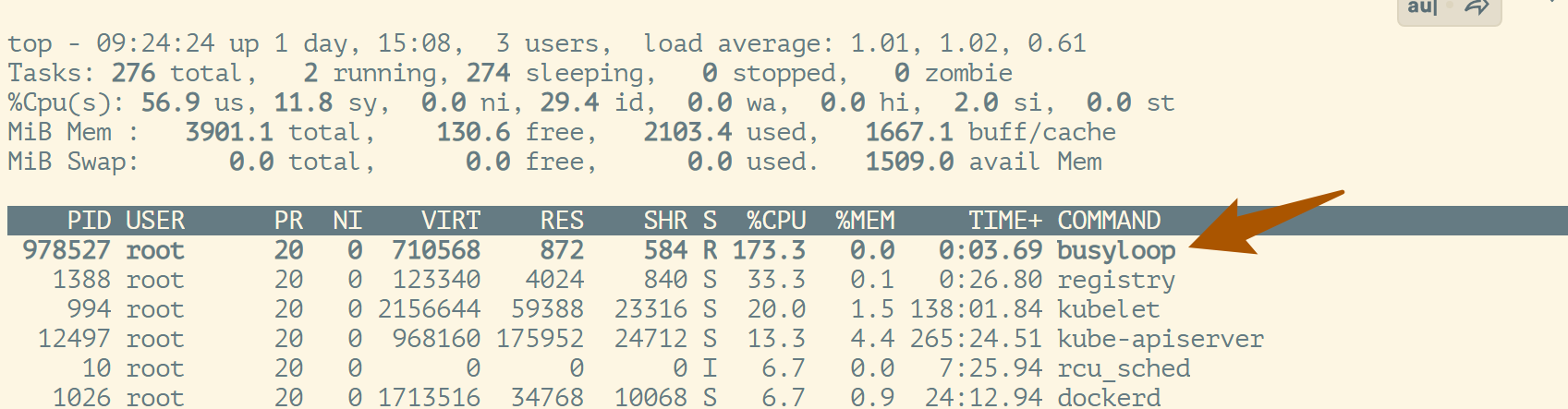
可以 用 top 看到我们的资源都被占用了
可以看到
busyloop进程吃满了2个CPU,记住PID为978527
继续:将该进程加入到CGroups的管理中
❯ cd /sys/fs/cgroup/cpu/cpudemo/;
echo 978527 > cgroup.procs;ls;
cat cgroup.procs

此时还没改,只是纳入管理.所以top查看还是200%
继续: 查看cpu.shares和cpu.cfs_period_us cpu.cfs_quota_us:
❯ cat cpu.shares;cat cpu.cfs_period_us ;cat cpu.cfs_quota_us
1024
100000
-1
此处-1表示不限制,我们需要改它阿:
通过修改绝对时间,控制该进程对CPU的占用时长
❯ echo 100000 > cpu.cfs_quota_us && cat cpu.cfs_quota_us
100000
此时quota值和period值是相同的.说明只能给该进程1个CPU.
最后:我们可以执行top命令查看:
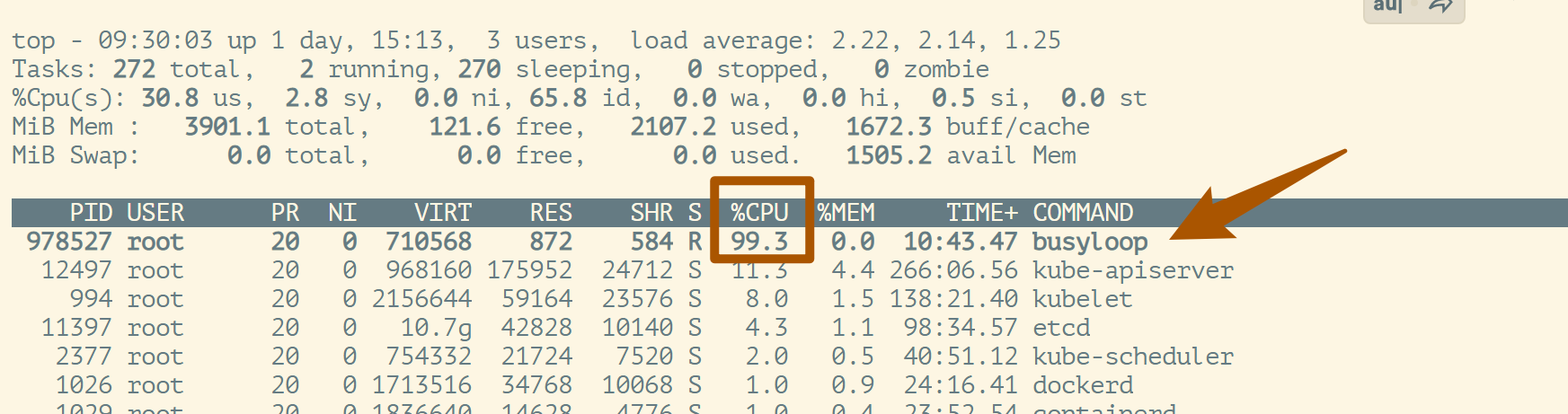
可以看到该进程现在只能占用1个CPU了.
补充:将quota限制为50000,再top查看
❯ echo 50000 > cpu.cfs_quota_us ;cat cpu.cfs_quota_us
50000
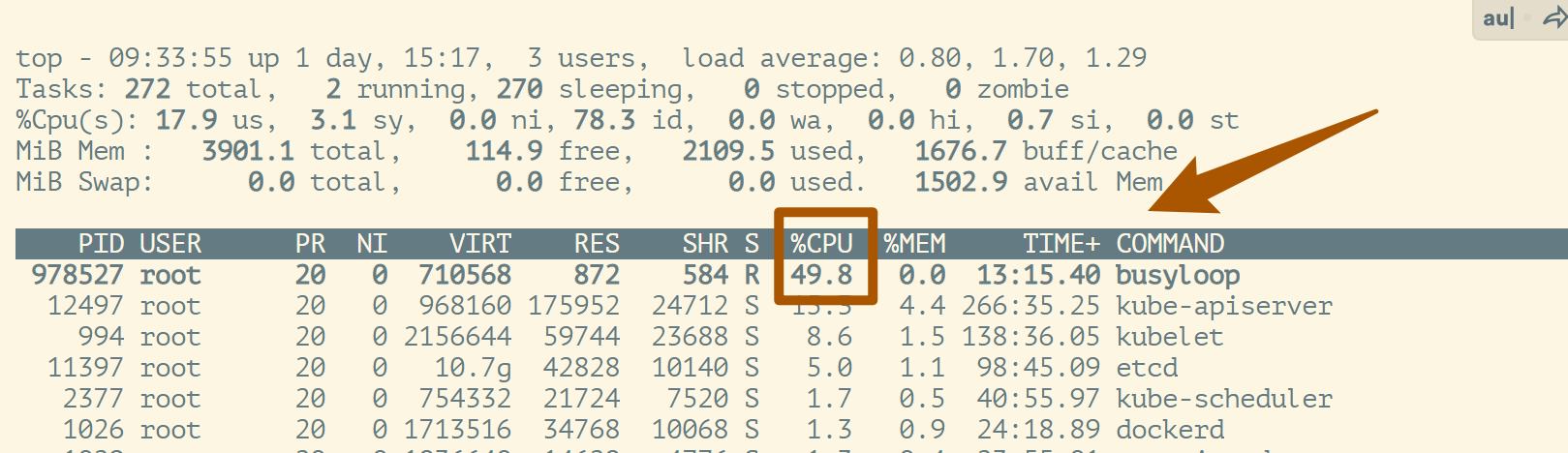
则此时只能占用1个CPU的50%了.
cpuacct子系统
用于统计Cgroup及其子Cgroup下进程的CPU使用情况
cpuacct.usage- 包含该Cgroup及其子Cgroup下进程使用CPU时间,单位是ns(纳秒)
cpuacct.stat- 包含该Cgroup及其子Cgroup下进程使用CPU时间,以及用户态和内核态的时间
Memory子系统
memory.usage_in_bytes- cgoup下进程使用的内存,包含cgroup及其子cgroup下的进程使用的内存
memory.max_usage_in_bytes- cgroup下进程使用内存的最大值,包含子cgroup的内存使用量
memory.limit_in_bytes- 设置cgroup下进程最多能使用的内存.如果设置为-1,表示对该cgroup的内存使用不做限制
memory.oom_control- 设置是否在cgroup中使用OOM(Out of Memory) Killer,默认为使用.当属于该cgroup的进程使用的内存超过最大限定值(
memory.max_usage_in_bytes)时,会立刻被OOM Killer处理
- 设置是否在cgroup中使用OOM(Out of Memory) Killer,默认为使用.当属于该cgroup的进程使用的内存超过最大限定值(
memory.limit_in_bytes:相当于控制进程可以用多少内存开销的限制.-1表示不限制
可压缩资源:比如CPU.压制一个进程可使用的CPU资源,不会导致该进程的死亡,只是会让这个进程运行速度变慢.
但内存不属于可压缩资源.因为内存一旦被限制,就不能再申请新的内存了.此时OS就会kill掉这个进程.
Cgroup dirver
- 当OS使用systemd作为init system时,初始化进程生成一个根cgroup目录结构并作为cgroup管理器
- systemd与cgroup紧密结合,并且为每个systemd unit分配cgroup
- cgroupfs
- docker默认用cgroupfs作为cgroup驱动
存在问题:
- 因此,在systemd作为init system的系统中,默认并存着2套groupdriver
- 这会使得系统中docker和kubelet管理的进程被cgroupfs管理;而systemd拉起的服务由systemd驱动管理.让cgroup管理混乱且容易在资源紧张时引发问题
- 因此kubelet会默认
--cgroup-dirver=systemd,若运行时cgroup不一致,kubelet会报错
Memory子系统案例
现有一个GO程序如下:
❯ cd /tmp; mkdir memory;cd memory;touch malloc.go malloc.c Makefile;ls
Makefile malloc.c malloc.go
❯ go mod init memory;tree
go: creating new go.mod: module memory
go: to add module requirements and sums:
go mod tidy
.
├── go.mod
├── Makefile
├── malloc.c
└── malloc.go
0 directories, 4 files
文件内容如下:
❯ cat Makefile malloc.c malloc.go
Makefile:
❯ cat Makefile
build:
CGO_ENABLED=1 GOOS=linux CGO_LDFLAGS="-static" go build
malloc.c:
❯ cat malloc.c
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define BLOCK_SIZE (100*1024*1024)
char* allocMemory() {
char* out = (char*)malloc(BLOCK_SIZE);
memset(out, 'A', BLOCK_SIZE);
return out;
}
malloc.go:
❯ cat malloc.go
package main
//#cgo LDFLAGS:
//char* allocMemory();
import "C"
import (
"fmt"
"time"
)
func main() {
// only loop 10 times to avoid exhausting the host memory
holder := []*C.char{}
for i := 1; i <= 10; i++ {
fmt.Printf("Allocating %dMb memory, raw memory is %d\n", i*100, i*100*1024*1025)
// hold the memory, otherwise it will be freed by GC
holder = append(holder, (*C.char)(C.allocMemory()))
time.Sleep(time.Minute)
}
}
编译 & 运行
🚀 编译结果如下:
❯ make build
CGO_ENABLED=1 GOOS=linux CGO_LDFLAGS="-static" go build
❯
❯ tree ./
./
├── go.mod
├── Makefile
├── malloc.c
├── malloc.go
└── memory
0 directories, 5 files
运行:
❯ ./memory
Allocating 100Mb memory, raw memory is 104960000
注意:此时时hang在这的
再起一个窗口,查看该进程的内存占用情况

在/sys/fs/cgroup/memory/下创建目录memorydemo1

查看memory进程的PID
❯ ps -ef|grep memory|grep -v grep|awk '{print $2}'
992008
将进程添加到cgroup配置组
❯ echo 992008 > cgroup.procs | cat
992008
end:设置memory.limit_in_bytes
❯ echo 104960000 > memory.limit_in_bytes | cat
104960000
此时运行
memory程序的窗口中,该进程已经被kill了.
文件系统
Union FS
😊 docker中namespace是创新点嘛,不是的,docker的创新点准确来说是并不是 runtime,而是在文件系统中(Union FS)。
- 将不同目录挂载到同一个虚拟文件系统下的文件系统(unite several directories into a single virtual filesystem)
- 支持为每一个成员目录(类似Git Branch)设定
readonly、readwirte和write-able权限 - 文件系统分层,对readonly权限的branch可以逻辑上进行修改(增量地,不影响readonly部分的)
- 通常Union FS有2个用途:
- 可以将多个disk挂到同一个目录下
- 将一个readonly的branch和一个writeable的branch联合在一起
Union FS:通过一些技术手段,将不同的目录mount到同一个虚拟目录中.每个目录在虚拟目录中可以有独立的权限(readonly、readwirte、write-able).
通过这种方式,可以将多个不同来源的子目录模拟成一个完整的OS.
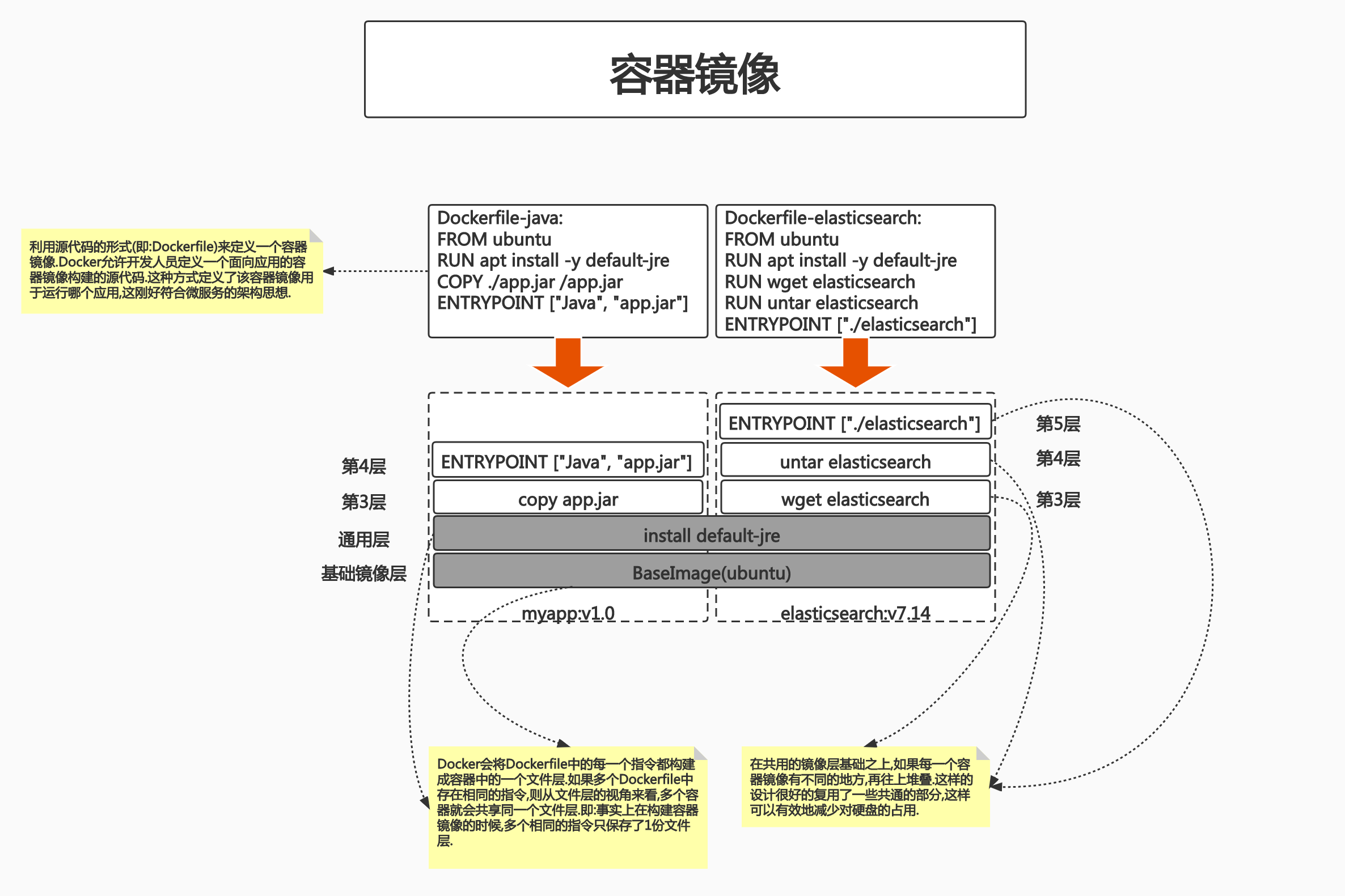
📜 对上面的解释:
我们可以看到 两个 dockerfile 是不一样的,但是前两条指令是一样的,也就是说在一个层。
但是后面两个层是不一样的,所以说后面两个 就开始判断。
所以这些地方是复用的。
docker pull 的时候会拉取并且判断,上面的话基础层是一样的,也就不会重复。
我们之前的学习 大致 止步于原理上,但是底层和源码实现还是缺少一部分的。
docker 文件系统
一般1个Linux会分为2个主要组成部分:
- Bootfs(boot file system)
Bootloader:引导加载kernelKernel:当kernel被加载到内存中后,umount bootfs
- rootfs(root file system)
/dev,/proc,/bin,/etc等标准目录和文件- 对于不同的Linux发行版,bootfs基本是一致的,但rootfs会有差别
Docker的启动
Linux的启动:
- 在启动后,首先将rootfs设置为
readonly(只读层),进行一系列检查,然后将其切换为"readwrite"供用户使用
Docker的启动:
- 初始化时也是将rootfs以
readonly方式加载并检查,但接下来使用union mount的方式将一个readwrite的文件系统挂载在readonly的rootfs之上 - 允许再次将下层的
FS(file system)设定为readonly并且向上叠加 - 这样一组
readonly和一个writeable的结构,构成了一个container的运行时态,每一个FS被称为一个FS层
最上方的一层为readwrite,在它之下的层都是readonly。所有用户的修改都被记录在了顶层(即 readwrite的层)中,不会涉及到下方的层.
写操作
由于镜像具有共享特性,所以对容器的可写层的操作需要依赖存储驱动提供的 写时复制和用时分配机制,以此来支持对容器可写层的修改,进而提高对存储和内存资源的利用率。
写时复制
写时复制:即Copy-on-Write 。1个镜像可以被多个容器使用,但是不需要在内存和磁盘上做多拷贝,在需要对镜像提供的文件进行修改时。该文件才会从镜像的文件系统被复制到容器的可写层文件系统,然后进行修改。而镜像中的文件不会改变。不同容器对文件的修改都相互独立、互不影响。
1个镜像是可以被不同的容器使用的 1 个镜像中的不同层也是被多个镜像共享的。因此有了写时复制技术,就可以确保下方的基础镜像层不会被修改.无论通过该基础镜像启动了多少个容器,这些容器的底层基础镜像都是一致的。换言之,N个使用了同一个基础镜像的容器,是共享了1个基础镜像层的文件,而非每个容器各持有一份基础镜像层文件的拷贝。
当需要修改基础镜像层时,是在位于该层上方的可写层中对基础层的文件做修改,最终结果相当于在上方的文件层中对下方的基础层做覆盖的操作。
用时分配
按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间
容器存储驱动优缺点比较以及应用
写时复制的行为需要容器的存储驱动来支持:
| 存储驱动 | Docker | Containerd |
|---|---|---|
| AUFS | 在Ubuntu或Debian上支持 | 不支持 |
| OverlayFS | 支持 | 支持 |
| Device Mapper | 支持 | 支持 |
| BtrFS | 社区版本在Ubuntu或Debian上支持,企业版本在SLES上支持 | 支持 |
| ZFS | 支持 | 不支持 |
为什么用 OverlayFS
| 存储驱动 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| AUFS | Docker最早支持的驱动类型,稳定性高 | 并未进入主线的内核,因此只能在有限的场合下使用.另外在实现上具有多层结构,在层比较多的场景下,做写时复制有时会需要比较长的时间 | 少I/O的场景 |
| OverlayFS | 并入主线内核,可以在目前几乎所有发行版本上使用.实现只有2层,因此性能比AUFS高 | 写时复制机制需要复制整个文件,而不能只针对修改的部分进行复制,因此大文件操作会需要比较长的时间.其中Overlay在Docker的后续版本中被移除 | 少I/O的场景 |
| Device Mapper | 并入主线内核,针对块操作,性能比较高.修改文件时只需复制需要修改的块,效率高 | 不同容器之间不能共享缓存。在Dokcer的后续版本中会被移除 | I/O密集场景 |
| BtrFS | 并入主线内核,虽然是文件级操作系统,但是可以对块进行操作 | 需要消耗比较多的内存,稳定性相对比较差 | 需要支持Snapshot等比较特殊的场景 |
| ZFS | 不同的容器之间可以共享缓存,多个容器访问相同的文件能够共享一个单一的Page Cache | 在频繁写操作的场景下,会产生比较严重的磁盘碎片.需要消耗比较多的内存,另外稳定性相对比较差 | 容器高密度部署的场景 |
OverlayFS
OverlayFS 也是一种与AUFS类似的联合文件系统,同样属于文件级的存储驱动,包含了最初的Overlay和更新更稳定的 OverlayFS2.
Overlay只有2层:upper层和lower层
lower层代表镜像层upper层代表容器可写层
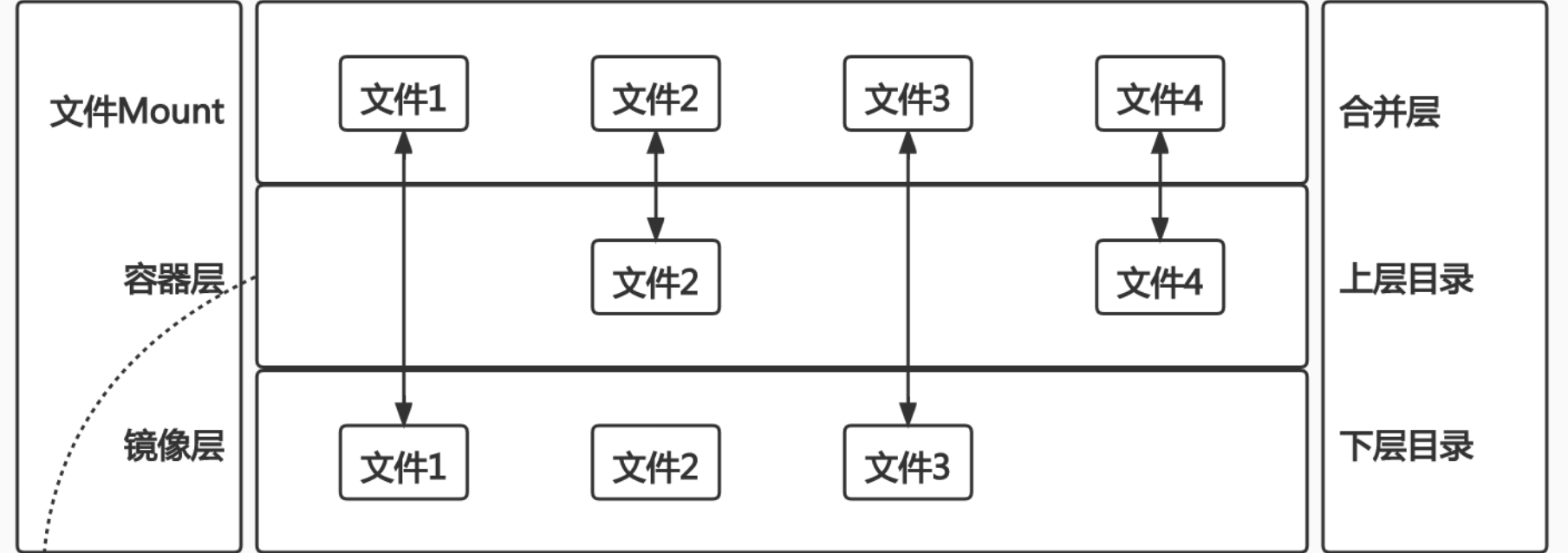
由此可见,如果一个文件在上层或者是在下层,那么他们在合并层是可见的。
如果一个文件在上下层都存在,那么就会出现在上层。
所以基础镜像是下层,每一次都叠加一次,最终看到的操作系统就是上层的。
OverlayFS文件系统演示
之前我们一直都没做镜像,我用 centos 镜像测试:
docker run -it --name centos2 centos
docker exec -it daddac4c0706 bash
在容器内创建目录:
[root@daddac4c0706 /]# ls
bin dev etc home lib lib64 lost+found media mnt opt proc root run sbin srv sys tmp usr var
[root@daddac4c0706 /]# mkdir upper lower merged work;ls
bin etc lib lost+found media mnt proc run srv tmp usr work
dev home lib64 lower merged opt root sbin sys upper var
分别创建不同的文件:
echo "from lower" > lower/in_lower.txt
echo "from upper" > upper/in_upper.txt
echo "from lower" > lower/in_both.txt
echo "from upper" > upper/in_both.txt
接下来要演示的是:将
upper目录和lower目录整合到一起后,文件的内容会有什么样的
挂载一个OverlayFS文件系统:
[root@daddac4c0706 /]# exit
exit
[root@dev workspces]# mkdir -p /tmp/overlayfs; cd /tmp/overlayfs
[root@dev overlayfs]# mkdir upper lower merged work;ls
lower merged upper work
[root@dev overlayfs]# echo "from lower" > lower/in_lower.txt
[root@dev overlayfs]# echo "from upper" > upper/in_upper.txt
[root@dev overlayfs]# echo "from lower" > lower/in_both.txt
[root@dev overlayfs]# echo "from upper" > upper/in_both.txt
[root@dev overlayfs]# sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged
目录结构:
[root@dev overlayfs2]# tree
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ ├── in_both.txt # delete
│ ├── in_lower.txt
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ └── in_upper.txt
└── work
└── work
挂载指令解析:
sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged
-t:指定文件系统类型lowerdir:指定用户要挂载的lower层目录upperdir:指定用户要挂载的upper层目录workdir:指定文件系统的工作基础目录.挂载后该目录会被清空,且在使用过程中其内容对用户不可见pwd/merged:这并不是参数,而是指定最终挂载的目录
查看./merged目录中的内容
[root@dev overlayfs2]# cd merged/
[root@dev merged]# cat in_both.txt in_lower.txt in_upper.txt
from upper
from lower
from upper
这是合并后的层
可以看到,当把2(多)个目录通过overlay的形式mount到一个虚拟目录时,在这个新的虚拟目录中,会整合来自上层和下层的文件。最终这个虚拟目录中会整合多个目录中的文件,如果遇到同名文件,则上层的文件会覆盖下层的文件。
回到容器镜像上,基础镜像层就相当于演示中的lower层。
若需要在这个基础镜像层中添加一些内容,则在这个基础镜像层上再加一个新的容器层,然后通过overlayFS的形式将这个新的容器层mount进去即可.
若需要在这个基础镜像层中做一些修改,也不需要去修改lower层,只需在上方堆叠一个同名文件即可。新的文件会覆盖掉下层中已存在的文件.
在./merged中删除文件:
[root@dev merged]# rm -f ./in_both.txt;tree ../
../
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ ├── in_lower.txt
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ └── in_upper.txt
└── work
└── work
我们删除掉了 合并层 in_both.txt 文件,看看有没有影响到
[root@dev merged]# cat ../upper/in_both.txt
cat: ../upper/in_both.txt: No such device or address
[root@dev merged]# cat ../lower/in_both.txt
from lower
可以看到,upper/in_both.txt被删除了。但lower/in_both.txt没有受到删除操作的影响。
对比到 docker ,容器层被删除了,但是 镜像(只读层没变化)
删除in_lower.txt(镜像)
[root@dev merged]# rm -f ./in_lower.txt;tree ../
../
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ ├── in_lower.txt
│ └── in_upper.txt
└── work
└── work
5 directories, 6 files
[root@dev merged]# cat ../upper/in_lower.txt
cat: ../upper/in_lower.txt: No such device or address
[root@dev merged]# cat ../lower/in_lower.txt
from lower
可以看到,upper/目录中多了一个文件in_lower.txt。但这个文件是不存在的。但lower/in_lower.txt没有受到删除操作的影响.
[root@dev merged]# cd ..;ls -al upper
total 12
drwxr-xr-x 2 root root 4096 Mar 2 20:16 .
drwxr-xr-x 6 root root 4096 Mar 2 20:06 ..
c--------- 1 root root 0, 0 Mar 2 20:11 in_both.txt
c--------- 1 root root 0, 0 Mar 2 20:16 in_lower.txt
-rw-r--r-- 1 root root 11 Mar 2 20:06 in_upper.txt
注:
c---------中的c表示字符设备文件
删除in_upper.txt
[root@dev overlayfs2]# rm ./merged/in_upper.txt -f
[root@dev overlayfs2]# tree
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
├── upper
│ ├── in_both.txt
│ └── in_lower.txt
└── work
└── work
可以看到: upper/in_upper.txt确实被删除了.
inspect
# docker inspect daddac4c0706
```bash
"Image": "sha256:5d0da3dc976460b72c77d94c8a1ad043720b0416bfc16c52c45d4847e53fadb6",
"ResolvConfPath": "/var/lib/docker/containers/daddac4c07067978995724d650ed8a6f0f8d8edfc979f13c9883f1a6971b904a/resolv.conf",
"HostnamePath": "/var/lib/docker/containers/daddac4c07067978995724d650ed8a6f0f8d8edfc979f13c9883f1a6971b904a/hostname",
"HostsPath": "/var/lib/docker/containers/daddac4c07067978995724d650ed8a6f0f8d8edfc979f13c9883f1a6971b904a/hosts",
"LogPath": "",
```
docker 引擎架构
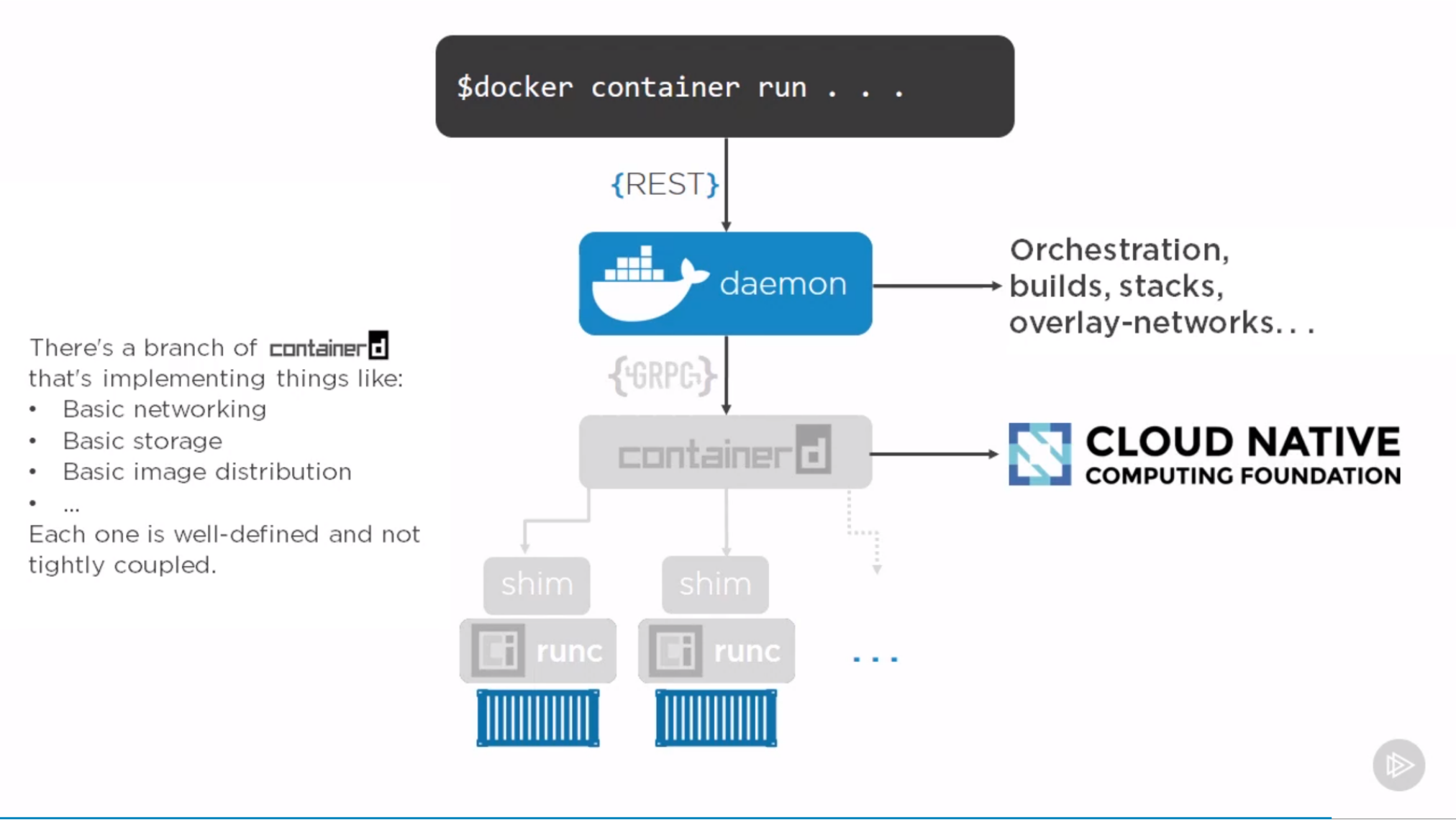
Docker daemon:Docker后台的服务端,事实上是一套 REST APIDocker command:命令行.可以把docker的命令作为一个请求发送给 Docker daemoncontainerd:用于控制运行时进程的组件,Docker daemon接收到该请求后,通过GRPC的调用,把请求转发到containerd上shim进程:containerd收到请求后,启动一个shim进程。shim进程通过runc(底层运行时的一个接口)启动容器进程
shim的作用:在早期,containerd和shim是不存在的.那个时代,当你通过docker命令去运行一个容器进程时,这个容器进程是由docker daemon直接拉起的。
这样设计的问题:docker daemon成为了所有容器进程的父进程.当你升级或重启docker时,父进程就不存在了,子进程也会被重启.这导致的问题是:你无法轻易升级docker.对于早期的docker来讲,这是一个致命问题。
containerd启动了一个shim进程后,会将该shim交给OS的init system(比如systemd)。这样 containerd下面是不挂任何进程的,可以随意升级或重启。即:把控制组件和数据面组件分离
docker 结构图 我们都知道,我们开始学 docker 的时候第一件事就是看架构,不管什么项目,始于架构,也忠于架构。
网络
😍 终于到了 网络 部分了,docker 网络是可以有 独立的 namespace ,但是也并不是这么简单的,接下来该好好研究网络了。
docker网络的几种模式:
- bridge模式(默认):使用
--network bridge指定,默认使用docker0 - host模式:使用
--network host指定 - none模式:使用
--network none指定(Kubernetes需要) - container模式:使用
--network container:NAME或者容器ID指定(复用其他容器的网络)
看到 docker0 就有一种神秘的亲切感,Kubernetes 的网络设计也是参考 docker~
你可以把 docker0 理解为一个交换机~
如果上层有Kubernetes这种编排系统,Kubernetes希望通过自己的网络插件来配置网络,此时就应该使用Null模式来创建一个镜像
⚠️ 注意,虽然什么都不做,但是用户希望全权处理容器的网络配置时使用 nono,Docker不为用户做任何配置,但是会为用户把网络的namespace创建出来.
跨主机的网络模式
Remote(work with remote dirvers)
Underlay:- 使用现有底层网络,为每一个容器配置可路由的网络IP
- 这种模式容器网络和主机网络是一样的.容器的IP段在主机层面知道如何路由.这样一来容器的数据包就可以自由传输.
- 这种模式的局限性:容器网络和主机网络共用,但容器网络对IP的消耗是巨大的.所以如果采用这种模式实现跨主机的容器间通信,需要提前规划好网段(比如有多大的网段分给容器,有多大的网段分给基础架构)
Overlay:- 通过网络封包实现
- 通常容器网络和底层基础架构网络是两套网络。容器有自己的子网,这个子网在底层网络中是不能路由的。也就是说,容器网络中的网络请求是不能在基础网络中传输的,数据包是传不过去的。
- 想要实现跨主机的容器间互联互通,就需要基于Overlay技术。当容器发出的数据包要通过主机向外传输时,在主机层面再封装一层。在原始数据包的基础上通过各种协议再加一层包头,这个包头会把当前主机地址作为原地址,把对端主机地址作为目标地址。封装好的数据包就可以在基础架构网络中传输了
- 数据包到达对端主机后,对端主机解包.解开主机一层包头后,剩下的就是容器的数据包头。这样一来数据包就可以到达对端主机上的容器了
单节点的容器网络模式
我们上面说过 NONO 是一个空实现
- Null模式是一个空实现
- 可以通过Null模式启动容器并在宿主机上通过命令为容器配置网络
案例
创建一个网络模式为Null的容器,并为该容器配置网络
运行一个nginx的容器,并且将网络模式设置成Null
[root@dev workspces]# docker run --network=none -d nginx
9dcdea440a927d7b7c60c0df3dab06b2b3cd3258507b07de339b31bd10c92d92
[root@dev workspces]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9dcdea440a92 nginx "/docker-entrypoin..." About a minute ago Up 57 seconds loving_nightingale
检查该容器进程的pid:
[root@dev workspces]# docker inspect 9dcde|grep -i pid
"Pid": 9737,
"PidMode": "",
"PidsLimit": 0,
在宿主机上查看容器进程的网络情况

可以看到只有loopback地址,没有其他网络配置。也就是说现在是无法通过外部的网络调用来访问这个服务的,但是该进程的 network namespace 是已经被建立了.
创建容器进程的network namespace
[root@dev workspces]# mkdir -p /var/run/netns
[root@dev workspces]# export pid=9737
[root@dev workspces]# ln -s /proc/$pid/ns/net /var/run/netns/$pid
此处创建目录的目的:当我们希望把一个进程关联到一个network namespace上时,就需要有一个地方来保存network namespace的相关信息(如:有哪些network namespace、这些network namespace关联了哪些进程等信息)。这个地方就是/var/run/netns/.
此处创建软连接的目的:/proc/$pid/ns/net是容器进程的network namespace信息 ,/var/run/netns/$pid是我们自己创建的,用于保存容器进程的network namespace的目录.此处建立软连接是为了后续操作,在创建了链路之后,连接容器进程的network namespace和主机的network namespace用。
⚠️ 注:某些程序启动服务后,会将它们PID放置在
/var/run/目录下
检查容器进程的network namespace是否能在主机上被查看到
[root@dev workspces]# ip netns list
9737
ip netns:用于管理network namespace。它可以创建命名的 network namespace,然后通过名字来引用network namespaceip netns list:显示所有命名的network namesapce,其实就是显示/var/run/netns目录下的所有network namespace对象
查看Docker的网桥设备:
[root@dev workspces]# if bridge-utils;then bridge;else yum install bridge-utils; fi
[root@dev workspces]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02420bb43568 no
当安装完Docker后,Docker默认在主机上会安装一个Bridge(桥接设备,可以理解为是一个集线器,该集线器上有很多网口。当多台主机的网线都连接到该Bridge设备后,这些主机之间就可以互通了),该设备用于连接当前主机上的所有容器。
有了网桥设备,想要让容器内的网络和主机互通,就比较容易了,其实只需要做2件事:
- 为容器进程配置网络
- 从容器的网络中牵一根网线到主机的namespace,并且插在docker0的Bridge上
这样主机网络和容器网络就可以互通了
默认模式–网桥和NAT
Docker网络的默认模式就是桥接。桥接其实就是刚才演示中的那些步骤.
不指定网络模式时,docker在网络连接方面做的工作,和我们刚才演示的是一样的。
案例
不指定网络模式,启动一个nginx容器
[root@dev workspces]# docker run -d nginx;docker ps
9f27121bb2f4ea27809830be982a705852430c7ed324b810ee2658452f289758

查看该容器的网络设备情况
[root@dev workspces]# docker inspect 9f|grep -i pid
"Pid": 19942,
"PidMode": "",
"PidsLimit": 0,
查看容器网络:
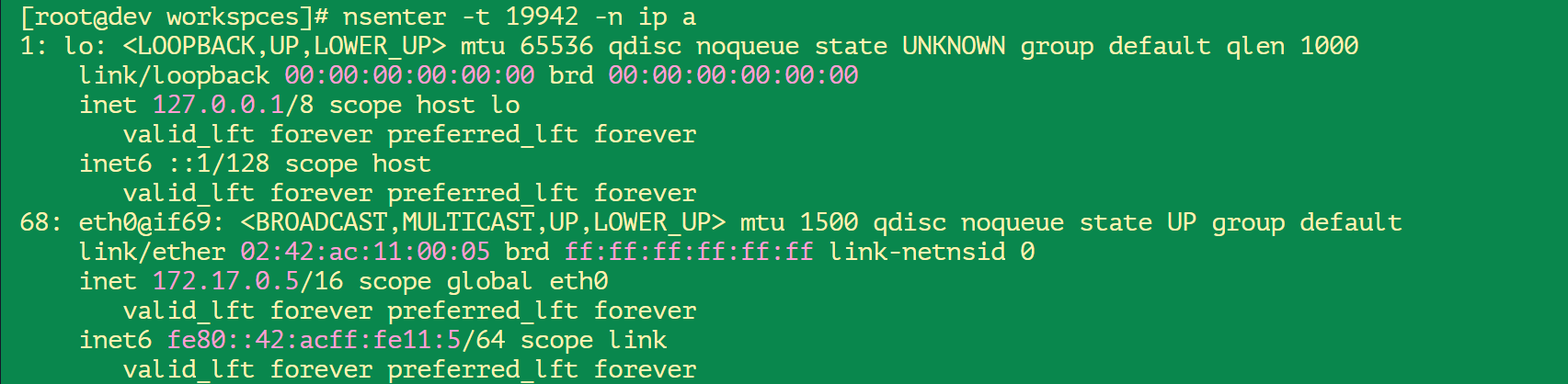
可以看到,该容器的IP地址为:
172.17.0.5,还可以这样:[root@dev workspces]# docker inspect 9f | grep -i ip "IpcMode": "", "LinkLocalIPv6Address": "", "LinkLocalIPv6PrefixLen": 0, "SecondaryIPAddresses": null, "SecondaryIPv6Addresses": null, "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "IPAddress": "172.17.0.5", "IPPrefixLen": 16, "IPv6Gateway": "", "IPAMConfig": null, "IPAddress": "172.17.0.5", "IPPrefixLen": 16, "IPv6Gateway": "", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0,
端口映射
若想要把容器内部的服务发布到主机上,该怎么做?
docker run -d --name nginx -p 8080:80 nginx
其底层逻辑为: Docker以标准模式配置网络
创建veth pair
将veth pair的一端连接到docker0网桥
veth pair的另一端设置为容器network namespace的eth0
为容器network namespace的eth0分配ip
主机上的iptables规则:
PREROUTING -A DOCKER ! -i docker0 -p tcp -m tcp -dport 2333 -j DNAT --to-destination 172.17.0.2:22实际上就是通过主机的iptable做了一个端口转发.
多节点的容器网络模式
Underlay
从实现上最容易的就是Underlay模式.
- 采用Linux网桥设备(sbrctl),通过物理网络连通容器
- 创建新的网桥设备mydr0
- 将主机网卡加入网桥
- 把主机网卡的地址配置到网桥,并把默认路由规则转移到网桥mydr0
- 启动容器
- 创建veth pair,把一个peer添加到网桥mydr0
- 配置容器把veth的另一个peer分配给容器网卡
也就是说,Underlay模式是不划分独立的容器网络,而是容器网络融入到基础架构网络中.
- 优点:方案简单
- 缺点:需要较强的网段规划能力.因为容器对IP的需求很大,所以要事先规划好所有IP的分配,避免造成IP的浪费.
Docker Libnetwork Overlay
- Docker overlay网络驱动原生支持多主机网络
- Libnetwork是一个内置的基于VXLAN的网络驱动
VXLAN是Overlay网络中最常用的一种模式.
Kubernetes中的网络插件Flannel支持Overlay模式
- 同一主机内的Pod可以使用网桥进行通信
- 不同主机上的Pod将通过flanneld将其流量封装在UDP数据包中
Dockerbuild
Dockerfile:用来构建镜像的文档,文档内容包含了一条构建镜像所需要的命令和说明。可以认为是创建一个虚拟机时,对操作的一个。
可以基于Dockerfile来定义整个容器镜像。包括容器的基础镜像、中间件、可运行的文件等。
docker build命令会依次读取并运行 Dockerfile 中的命令,把这些命令转换成一个真实的容器镜像。
通常一个容器镜像分为2部分:
- 描述文件(元数据)
- 二进制文件
理解构建上下文 (build context)
我们在阅读源码的时候,经常看到 build context,不管是 sealer、sealos、Kubernetes、k3s……
当运
docker build命令时,当前工作目录被称为构建上下文docker build默认查找当前目录的Dockerfile作构造输入,也可以通过-f参数指定Dockerfiledocker build -f ./Dockerfile当
docker build运行时,首先会把构建上下文传给docker daemon,把没有用的文件包包含在构建上下文中,会导致传播时间长,构建需要的资源架构出鞄鲧- 可以通过
.dockerignore文件从构建上下文中排除某些文件
- 可以通过
因此需要确保构建上文清晰,比如创建一个专门的目录放Dockerfile,并在目录中运行
docker build
构建缓存(Build Cache)
镜像构建日志:使用docker build命令构建镜像时,打印每一步(每一层或Dockerfile中的每一条指令)执行过程的输出内容。通过日志可以知道构建的每一个步骤.
注意日志中的Using cache的部分,即构建缓存。
# docker build $GOPATH/src/httpServer
Sending build context to Docker daemon 7.228MB
Step 1/9 : FROM ubuntu
---> ba6acccedd29
Step 2/9 : ENV MY_SERVICE_PORT=80
---> Using cache
---> 08b186233bb0
......
Docker 从上往下读取指令后,会先判别存储中是否有可用的已存储镜像,只有已存储镜像不存在时,才会重新构建。否则重复使用(reuse)已存储镜像。
通常Docker简单判定Dockerfile中的命令与镜像
指针
ADD和COPY命令,Docker判断应该镜像层每个被复制的文件的内容并生成一个checksum(校验和),与现有镜像比较时,比较的是二方的校验和其他指令,比如
RUN apt-get -y update,Docker简单比较与现有镜像中的指令字符串是否一致当某一层cache失效后,所有层级的cache均一并失效,后续指令都重新构建镜像
因此,在构建镜像时,应该尽量把很久才更新一次的(或者可以说不动的)层放在下面,把频繁更新的层放在上面。用于防止一个层缓存失效后,该层之上所有的层都缓存失效的问题。
⚠️ 再多解释一下,就是那些 不稳定 的命令写在前面(在下层),那些 稳当 的写在后面(在上层),符合构建策略~
多段构建(Multi-stage build)
有一种场景,我来描述一下:
我们构建一个业务,需要很多依赖包,正常情况下 我们 去拉取、构建、但是我们可能只需要最后一个内容或者文件,所以中间很多依赖我们可能需要去清理、删除。
场景:此时需编译一个容器镜像,该容器镜像中运行一个GO语言编写的进程,请以最终运行该进程的镜像体积尽可能小为目标,编译容器镜像。
GO语言的项目通常有
vendor/目录,因此编译时需要拉取第三方依赖包。需要注意的是,此时拉取的是第三方包的源代码,拉取之后才能完成项目的编译工作/但最终容器镜像需要的并不是这些源码,仅仅是编译之后的二进制文件,可是编译的过程又会把源代码拉取到本地,这些源代码会影响最终编译出来的镜像的体积。因此需要多段构建~多段构建: 在1个Dockerfile中,指定多个要构建的镜像。其中一个镜像(为方便描述称该镜像为镜像A)用于编译项目,将编译好的二进制文件放到指定的目录;另一个镜像用于运行该二进制文件(为方便描述称该镜像为镜像B)。镜像B从镜像A指定的目录中将二进制文件复制到镜像B中,并运行该二进制文件。
所以中间有很多没必要的依赖包,比如说我们只需要最后的二进制文件。所以 docker 提供多段构建,分成多个部分:
root@docker-test:/home/roach/dockerGoImg# cat Dockerfile # 编译用镜像 ARG GO_VERSION=1.17.6 # 命名编译用镜像为builder FROM golang:${GO_VERSION} as builder RUN mkdir -p /go/src/test WORKDIR /go/src/test COPY main.go . RUN go mod init testGoProject RUN CGO_ENABLED=0 GOOS=linux go build -o app . # 运行用镜像 FROM alpine:latest RUN apk --no-cache add ca-certificates WORKDIR /root/ # 从镜像builder处复制文件 COPY /go/src/test/app . CMD ["./app"]我们把临时的 都放在 早期
golang:${GO_VERSION} as builder真正需要的放在
app二进制文件放在后面 ~
Dockerfile 最佳实践建议
- 不要安装无效软件包
- 应简化镜像中同时运行的进程数,理想状况下,每个镜像应该只有1个进程
- 这样利于管理容器:当把一个传统巨石架构的应用移植到容器平台时,想要一下就成为这种1个容器运行1个进程的架构是比较困难的。经常会有一些伴生的进程,所以这只是指导原则,当做不到的时候,也会把多个进程放在同一个容器中,这时就要选择合理的初始化进程.
- 当无法避免同一镜像运行多进程时,应选择合理的初始化进程(init process)
- 最小化层级数
- 最新的docker只有
RUN、COPY、ADD指令会创建新的层,其他指令创建的是临时层,不会影响最终镜像的大小- 比如
EXPOSE指令就不会生成新的层
- 比如
- 通过多段构建减少镜像层数
- 将命令用
&&连接起来,仅执行1条RUN指令,可以减少层数
- 最新的docker只有
- 把多行参数按字母排序,可以减少可能出现的重复参数,并且提高可读性
- 编写Dockerfile时,应该把变更频率低的编译指令优先构建,以便放在镜像底层,这样能够有效利用构建缓存(build cache)
- 复制文件时,每个文件应独立复制,这确保某个文件变更时,只影响文件对应的缓存
目标:易管理、少漏洞、镜像小、层级少、利用缓存
多进程的容器镜像
一般来说,都是推荐单进程的,毕竟根据 namespace 原理,一个进程对应一个 app。
但是总会有依赖的,也就是多进程。
推荐应该选择适当的init进程
- 需要捕获SIGTERM信号并完成子进程的优雅终止
- 负责清理退出的子进程以避免僵尸进程
这方面上如果做的不好,就会出现很大问题:
当Kubernetes要去终止一个进程时,会发送一个SIGTERM终止信号给容器,以便容器能够优雅退出。但如果容器这一侧做的不够好,就会出现问题。
比如容器中有一个初始化进程(init),用于拉起主进程。则来自Kubernetes的SIGTERM信号发送到初始化进程时,初始化进程并没有把信号传递给主进程,而是直接把这个信号给无视了。这样应用就失去了优雅终止的可能性,最终应用只能被kill -9,有可能导致业务故障。
或许这时候你应该需要 Tini - 小巧但适用init于容器,initTini 是您能想到的最简单的。
Tini 所做的只是生成一个子进程(Tini 应该在容器中运行),并等待它退出,同时收割僵尸并执行信号转发。
docker tag 与 GitHub 的版本管理
以Kuberbetes为例:
- 开发分支
git checkout master
- Release分支
git checkout -b release-1.21
- 在并行期,所有变更同时进
master和release branch - 版本发布
- 以
release branch为基础构建镜像,并为镜像标记版本信息 docker tag 93b6fb6b8635 k8s.io/kubernetes.apiserver:v1.21
- 以
- 在github中保存
release代码快照git tag v1.21
此时 标签 就对上了
docker 私有仓库
如今私有仓库几乎是企业必备的需求,而且以前 docker 基础提高过:
在 k3s 教程中 我们补充过 Kubernetes 、 k3s 私有注册表的配置,我们再提一提:
- docker hub : https://hub.docker.com
docker 官方镜像有 文档,之前做过笔记 就不提了
查看 registry 私有镜像仓库:

使用registry镜像创建私有仓库:
docker run -d -p 宿主机端口:容器端口 registry:TAG
运行官方提供的registry镜像。(注:官方建议TAG为2),你还需要的参数:
-v,--volume:挂载宿主机上的文件卷到容器内。仓库默认被创建在容器的/var/lib/registry目录下。可使用该参数指定镜像文件存放的路径.
案例
❯ export REG="/opt/data/registry"
❯ mkdir -p $REG;cd $REG
❯ docker run -d -p 5003:5000 -v $REG:/var/lib/registry registry:2
30c6d0d0ac384d60f72c04e6fb479fab6baeb20fe64790248896b139b591e20a
查看结果:

管理私有仓库
我当前的环境:
- 搭建私有仓库虚拟机 Ubuntu-master01:
192.168.137.133 - 私有仓库端口如上:
5003 - 另一台客户机,虚拟机地址:
192.168.137.134
在客户机上拉取镜像ubuntu:18.04
# docker pull ubuntu:18.04
在客户机上使用docker tag命令,将该镜像标记为192.168.137.133:5003/test
# docker tag ubuntu:18.04 192.168.137.133:5003/test
在客户机上添加信任的私有仓库列表
# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://sb6xpp51.mirror.aliyuncs.com"],
"insecure-registries": [
"192.168.137.133:5003"
]
}
在客户机上使用docker push上传标记的镜像
# docker push 192.168.137.133:5003/test
在客户机上使用curl查看仓库192.168.0.152:5000中的镜像
# curl -XGET http://192.168.137.133:5003/v2/_catalog
{"repositories":["test"]}
在客户机上删除打过TAG的镜像,以便后续测试拉取
# docker images
# docker rmi 192.168.137.133:5003/test
# docker images
# docker pull 192.168.137.133:5003/test
# docker images
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©