第53节 CRI、CNI、CSI 底层刨析
❤️💕💕新时代拥抱云原生,云原生具有环境统一、按需付费、即开即用、稳定性强特点。Myblog:http://nsddd.top
[TOC]
容器运行时
容器运行时(Container Runtime),运行于Kubernetes (k8s)集群的每个节点中,负责容器的整 个生命周期。其中Docker是目前应用最广的。随着容器云的发展,越来越多的容器运行时涌现。为了 解决这些容器运行时和Kubernetes的集成问题,在Kubernetes 1.5版本中,社区推出了CRI ( Container Runtime Interface,容器运行时接口)以支持更多的容器运行时。
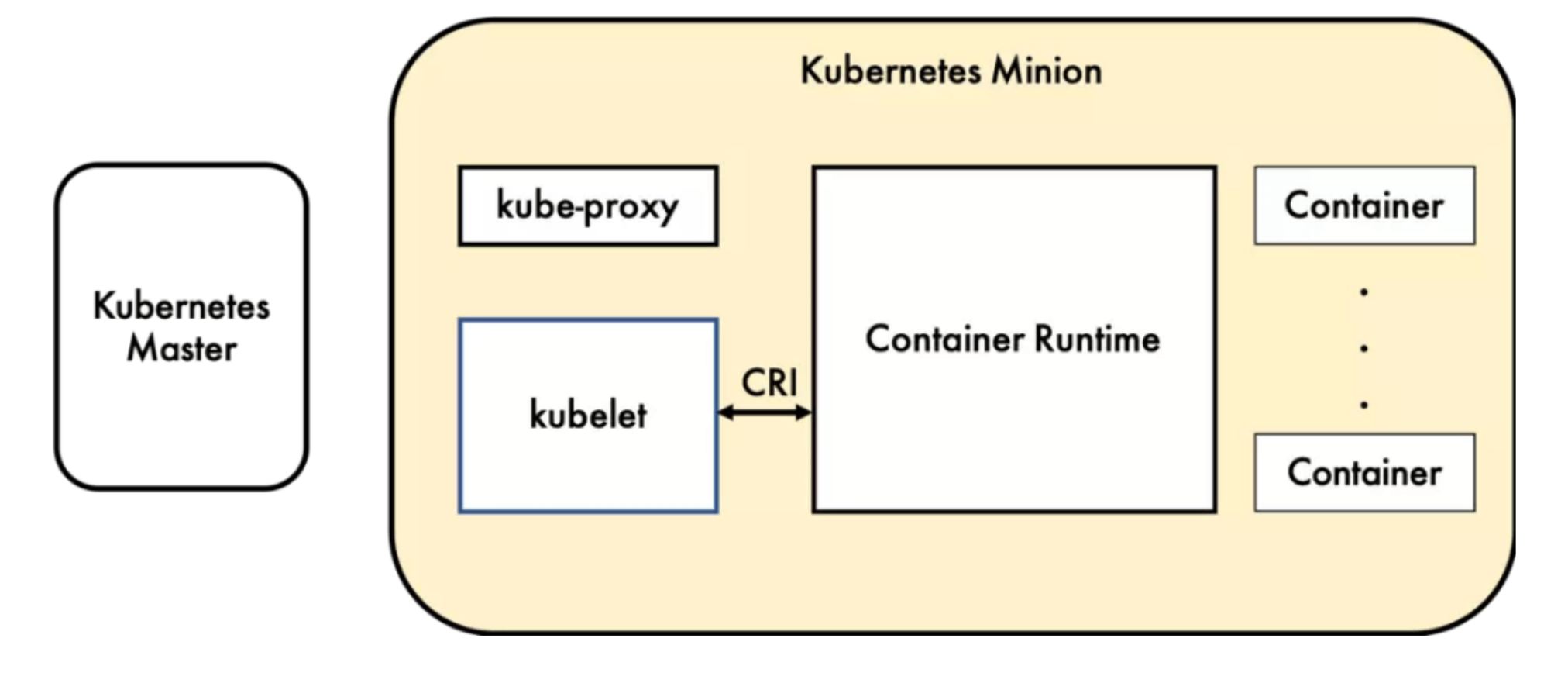
什么是 CRI
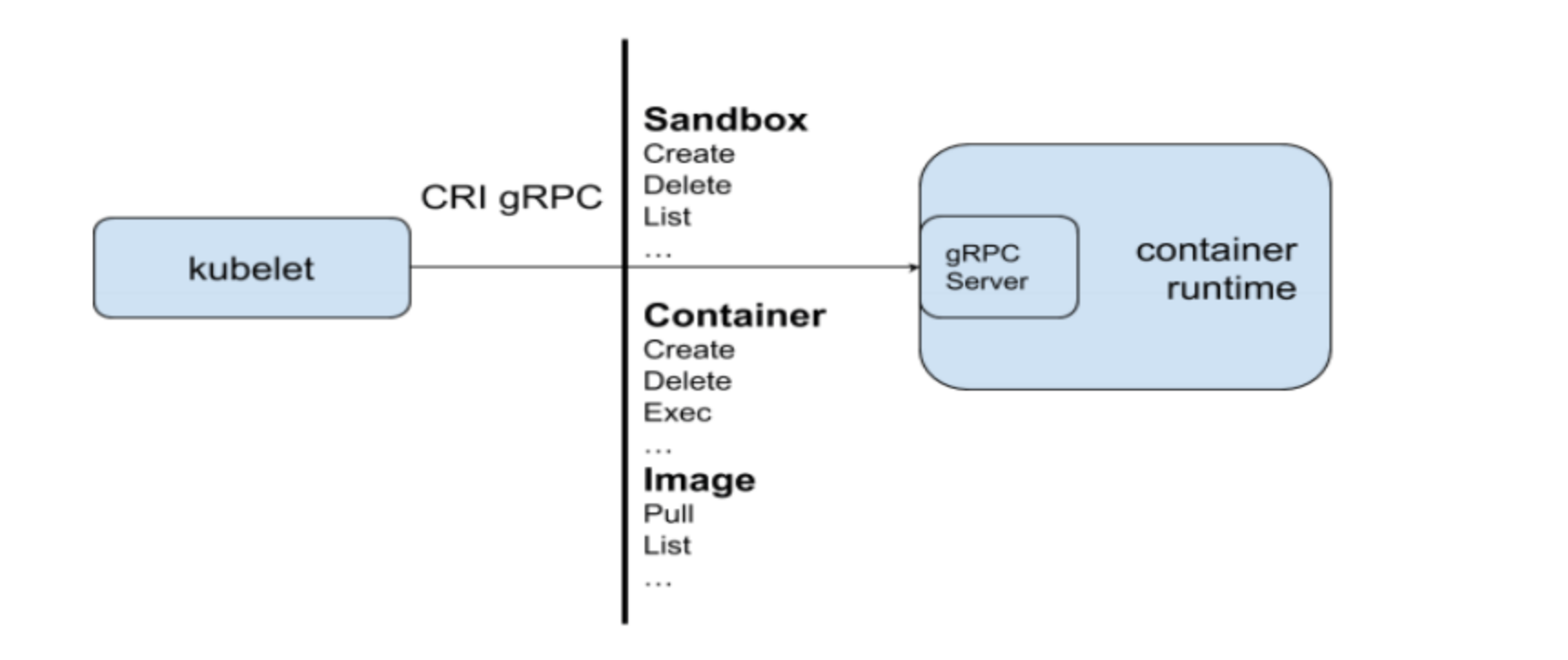
CRI 是 Kubernetes 定义的一组 gRPC 服务。
kubelet 作为客户端,基于 gRPC 框架,通过 Socket 和容器运行时通信。它包括两类服务:
- 镜像服务(Image Service):提供下载、检查和删除镜像的远程程序调用;
- 运行时服务(Runtime Service):包含用于管理容器生命周期,以及与容器交互的调用(exec/ attach / port-forward)的远程程序调用。
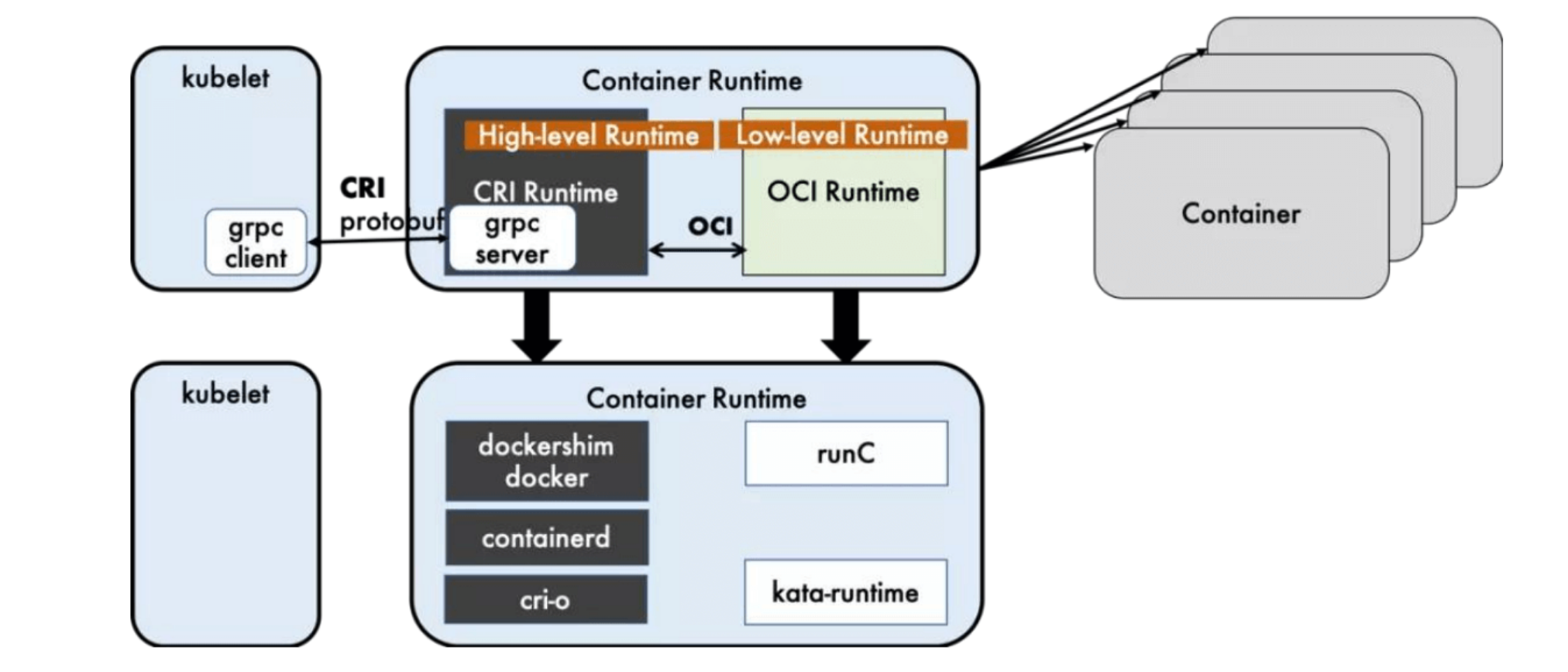
运行时的层级
容器运行时可以分为高层和低层的运行时:
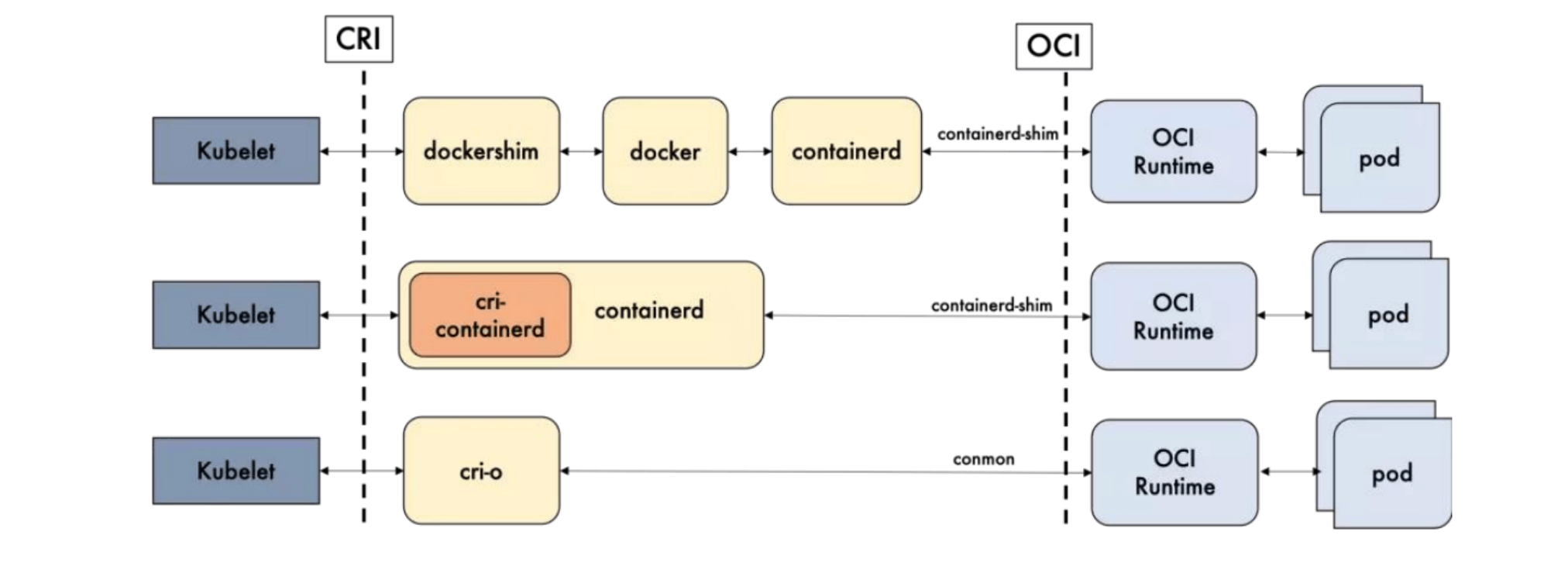
Dockershime,containerd 和 CRI-O 都是遵循 CRI 的容器运行时,我们称之为 高级运行时。
OCI 定义了创建容器的格式和运行时的开源行业标准,包括 镜像规范(Image Specification) 和 容器运行时规范 (runtime specification)
镜像规范定义了 OCI 镜像标准,高层级运行时 将会下载一个 OCI 镜像,并且将它解压为 OCI 运行时文件系统包(file system bundle)
运行时规范描述了如何从 OCI 运行时文件系统包运行容器程序。并且定义它的配置,运行环境和生命周期。如何为新的容器设置命名空间(namespace)和控制组(cgroup) ,以及挂载根文件系统(rootfs)等等操作,都是在这里定义的。它的一个参考实现是 runc,我们称其为 低层级运行时(Low-level Runtime)
- 高层级运行时(High-level Runtime):主要包括 Docker,containerd 和 CRI-O
- 低层级运行时(Low-level Runtime):包含了 runc, kata,以及 gVisor。
低层运行时 kata 和 gVisor 都还处于小规模落地或者实验阶段,其生态成熟度和使用案例都比较欠缺,所以除非有特殊的需求,否则 runc 几乎是必然的选择。因此在对容器运行时的选择上,主要是聚焦于上层运行时的选择。
可能你还是无法理解,简单来说,就是一边链接 Kubernetes ,一边链接容器进程,前者是高级运行时,后者是低级运行时。
OCI
**OCI (Open Container Initiative,开放容器计划)**定义了创建容器的格式和运行时的开源行业标准, 包括:
- 镜像规范(Image Specification):定义了 OCI 镜像的标准。高层级运行时将会下载一个OCI 镜像,并把它解压成OCI 运行时文件系统包(filesystem bundle)。
- 运行时规范(Runtime Specification):描述了如何从 OCI 运行时文件系统包运行容器程序,并且定义它的配置、运行环境和生命周期,如何为新容器设置命名空间(namepsaces)和控制组(cgroups) ,以及挂载根文件系统等等操作。
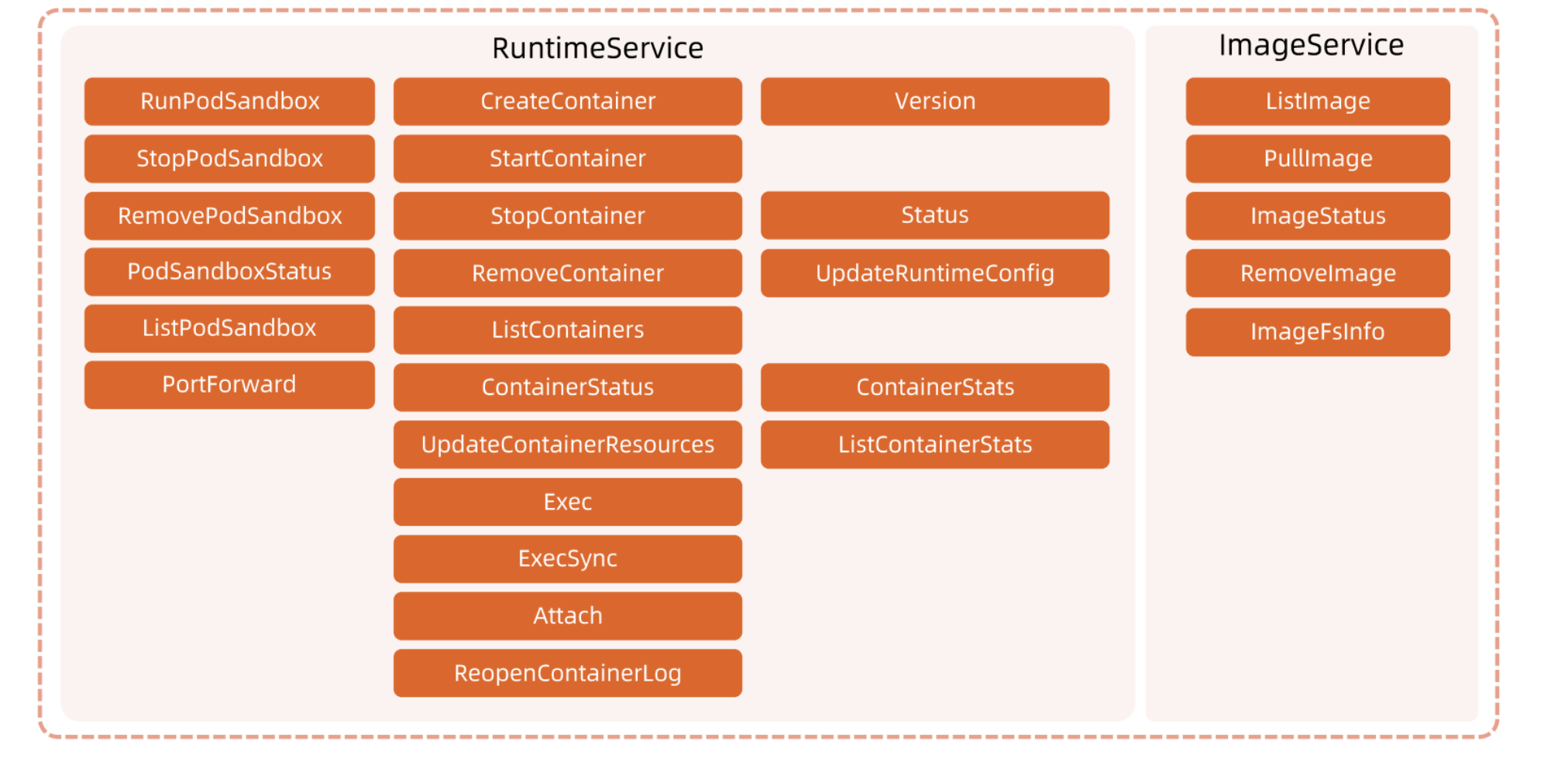
CRI 方法列表
开源运行时的比较
Docker 的多层封装和调用,导致其在可维护性上略逊一筹,增加了线上问题的定位难度;几乎除了重启 Docker,我们就毫无他法了。 containerd 和 CRI-O 的方案比起 Docker 简洁很多。
docker 可以理解为 containerd 的一个超集,如果你用 docker 作为 运行时,那么相当于启动了一个厚重的 dockershim。
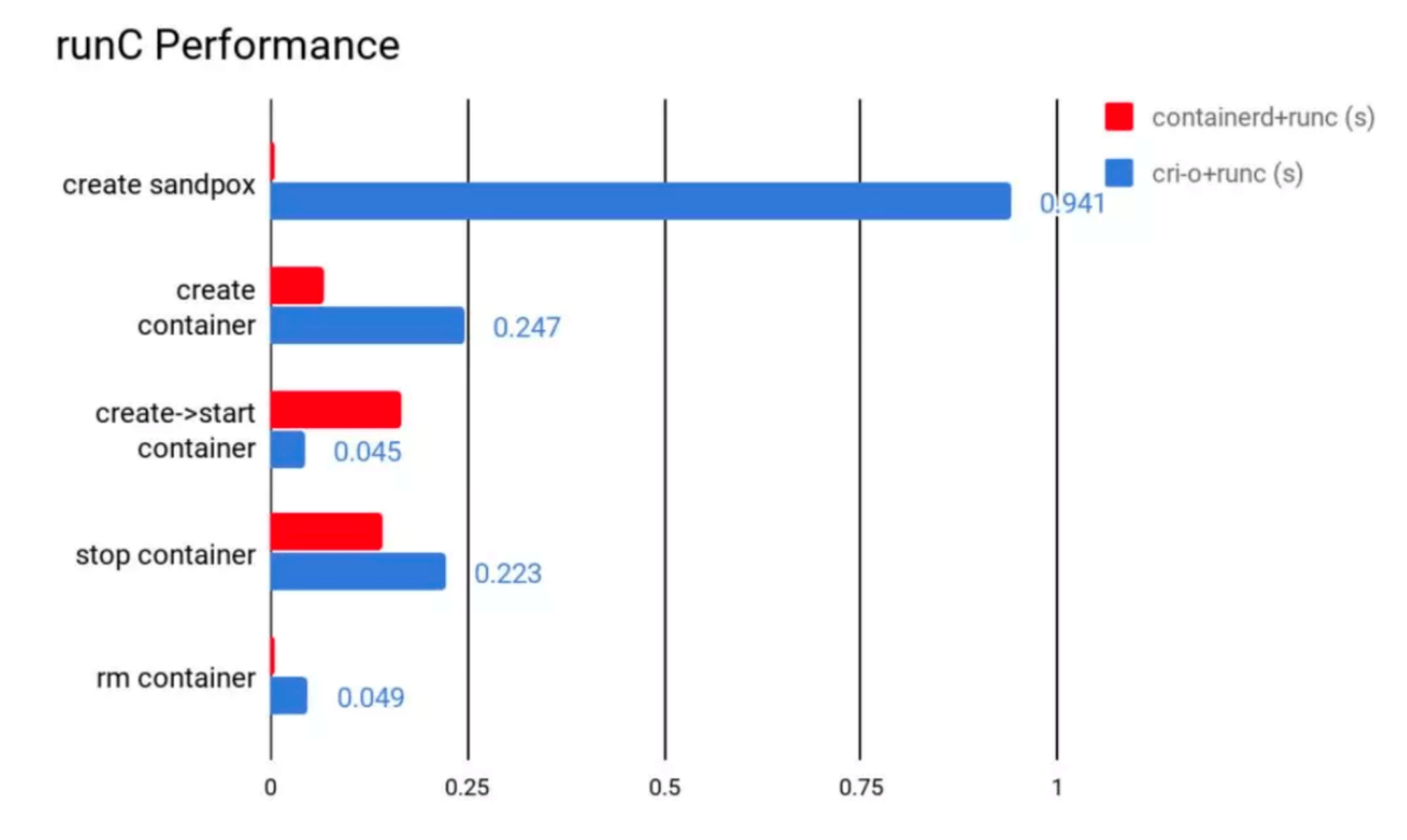
性能差异
containerd 在各个方面都表现良好,除了启动容器这项。从总用时来看,containerd 的用时还是要比 CRI-O 要短的。
所以最终是 containerd 赢了,最优的方案,当然 cri-o + runc 也是可以的。
优劣对比
功能性来讲,containerd 和 CRI-O 都符合 CRI 和 OCI 的标准;;在稳定性上,containerd 略胜一筹; 从性能上讲,containerd 胜出。
| containerd | CRI-O | 备注 | |
|---|---|---|---|
| 性能 | 更优 | 优 | |
| 功能 | 优 | 优 | CRI 与 OCI 兼容 |
| 稳定性 | 稳定 | 未知 |
Docker & Containerd
Docker 内部关于容器运行时功能的核心组件是 containerd,后来 containerd 也可直接和 kubelet 通过 CRI 对接,独立在 Kubernetes 中使用。
这就是很微妙的,containerd 也提供了 CLI 工具:
crictl pods #也能读取pod信息
相对于 Docker而言,containerd 减少了Docker 所需的处理模块 Dockerd 和 Docker-shim,并且对 Docker 支持的存储驱动进行了优化,因此在容器的创建启动停止和删除,以及对镜像的拉取上,都具有性能上的优势。架构的简化同时也带来了维护的便利。
当然 Docker 也具有很多 containerd 不具有的功能,例如支持 zfs 存储驱动,支持对日志的大小和文件限制,在以 overlayfs2 做存储驱动的情况下,可以通过 xfs_quota 来对容器的可写层进行大小限制等。尽管如此,containerd 目前也基本上能够满足容器的众多管理需求,所以将它作为运行时的也越来越多。
docker 和 containerd 的差异细节
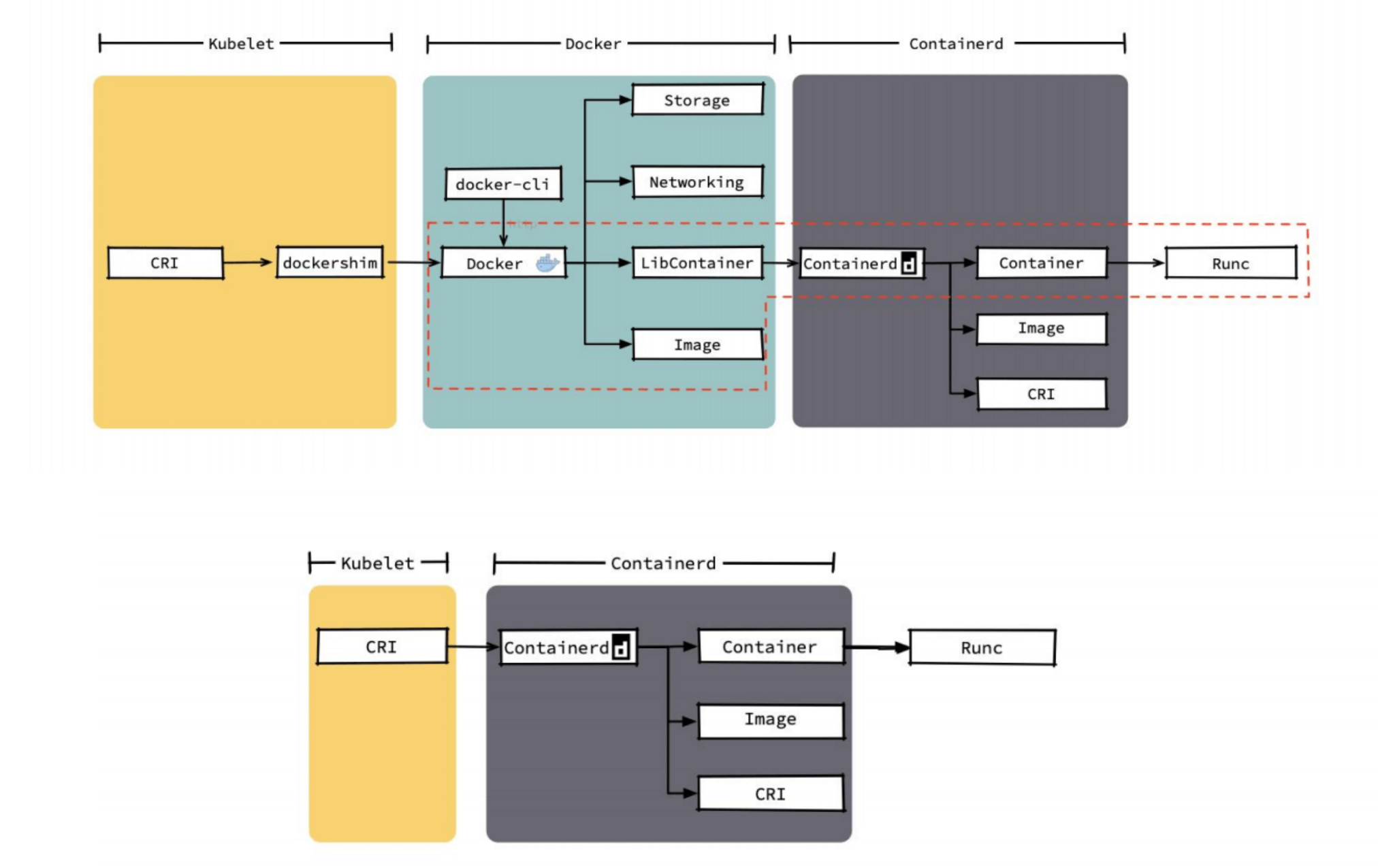
可以看到 docker 中有许多 k8s 不需要的功能,k8s 需要的只是 红框中的部分,其他的都是冗余,即便去掉这部分,剩下的调用链也是非常的长。
相比之下 containerd 整个代码和调用链都远优于 docker 的。
如何从 Docker 切换到 Containerd
https://kubernetes.io/zh/docs/setup/production-environment/container-runtimes/#containerd
Stop service
systemctl stop kubelet
systemctl stop docker
systemctl stop containerd
Create containerd config folder:
配置 containerd :
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
在 containerd 中,
sandbox_image这个参数:❯ containerd config default | sudo tee /etc/containerd/config.toml | grep -i "sandbox_image" sandbox_image = "k8s.gcr.io/pause:3.1"在国内不翻墙是没办法下载的。
Update default config
sed -i s#k8s.gcr.io/pause:3.5#registry.aliyuncs.com/google_containers/pause:3.5#g /etc/containerd/config.toml
sed -i s#'SystemdCgroup = false'#'SystemdCgroup = true'#g /etc/containerd/config.toml
可以配置镜像为 阿里云
Edit kubelet config and add extra args
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Environment="KUBELET_EXTRA_ARGS=--container-runtime=remote --container-runtime-endpoint=unix:///run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.5"
接下来就是 修改 Kubernetes 的启动参数,告诉 Kubernetes 我的运行时 要改为 containerd。
这个位置就是 kubelete gPRC 调用的位置。

Restart
systemctl daemon-reload
systemctl restart containerd
systemctl restart kubelet
Config crictl to set correct endpoint
cat <<EOF | sudo tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
EOF
CNI
Kubernetes 集群网络
ok,我觉得 Kubernetes 的集群网络是非常复杂的,回归到网络本身也是非常复杂的。即使是对有着虚拟网络和请求路由操作的工程师来说也是如此。很多书上(包括 docker、Kubernetes 的教程,网络学习本身是一个循循渐进的过程,Kubernetes 会从 docker 网络讲起,docker 从Linux讲起,我们在前面 docker 中也是了解到网络一些核心的不是吗,那我们就从 Linux 网络开始讲起。
Linux名称空间包含了大多数现代容器实现背后的一些基本技术。在高级别上,它们允许在独立进程之间隔离全局系统资源。例如,PID命名空间隔离进程ID号空间。这意味着在同一主机上运行的两个进程可以有相同的PID!
这种级别的隔离在容器世界中显然是有用的。例如,如果没有名称空间,在容器A中运行的进程可能会在容器B中卸载一个重要的文件系统,或者更改容器C的主机名,或者从容器D中删除一个网络接口。通过命名这些资源,容器A中的进程甚至不知道容器B、C和D中的进程存在。
Kubernetes网络模型设计的基础原则是:
- 所有的Pod能够不通过NAT就能相互访问。
- 所有的节点能够不通过NAT就能相互访问。
- 容器内看见的IP地址和外部组件看到的容器IP是一样的。
Kubernetes 的集群里,IP 地址是以 Pod 为单位进行分配的,每个 Pod 都拥有一个独立的 IP 地址。一个 Pod 内部的所有容器共享一个网络栈,即宿主机上的一个网络命名空间,包括它们的 IP 地址、网络设备、配置等都是共享的。 也就是说,Pod 里面的所有容器能通过 localhost:port 来连接对方。
在 Kubernetes 中,提供了一个轻量的通用容器网络接口 CNI ( Container Network Interface),专门用于设置和删除容器的网络连通性。 容器运行时通过 CNI 调用网络插件来完成容器的网络设置。
CNI 插件分类和常见插件
- IPAM: IP地址分配
- 主插件:网卡设置
bridge:创建一个网桥,并把主机端口和容器端口插入网桥ipvlan:为容器添加ipvlan网口loopback:设置loopback网口
- Meta: 附加功能
portmap:设置主机端口和容器端口映射bandwidth:利用Linux Traffic Control限流firewall:通过iptables或firewalld为容器设置防火墙规则
https://github.com/containernetworking/plugins
CNI 插件运行机制
容器运行时在启动时会从 CNI 的配置目录中读取 JSON 格式的配置文件。
cat /etc/cni/net.d # 读取这个 CNI 配置文件
ls -al /opt/cni/bin # CNI 可执行二进制文件
文件后缀为 .conf、 .conflist、 .json。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的 CNI 插件名称和配置参数。
我们可以看到有个
.conflist结尾的文件,是的,k8s 的 cni 允许同时使用多个插件,并且会把上一个插件的执行结果作为参数传递给下一个插件,以此我们可以串通多个插件,让多个插件做不同的事情。比如我可以第一个插件只负责让同一台主机上的节点通信,然后第二个插件可以负责让不同节点上的 pod 通信,总之还是那句话,配置文件有了,pod 信息也被 k8s 传过来了,爱怎么玩儿是你插件自己的事儿了~
关于容器网络管理,容器运行时一般需要配置两个参数 --cni-bin-dir 和 --cni-conf-dir。
cni-bin-dir:网络插件的可执行文件所在目录。默认是/opt/cni/bin。cni-conf-dir:网络插件的配置文件所在目录。默认是/etc/cni/net.d。
有一种特殊情况,kubelet 内置的 Docker 作为容器运行时,是由 kubelet 来查找 CNI 插件的,运行插件来为容器设置网络,这两个参数应该配置在 kubelet 处。
后续 k8s v1.24 彻底移除 docker 之后就不用考虑这种特殊情况了。
具体流程如下:
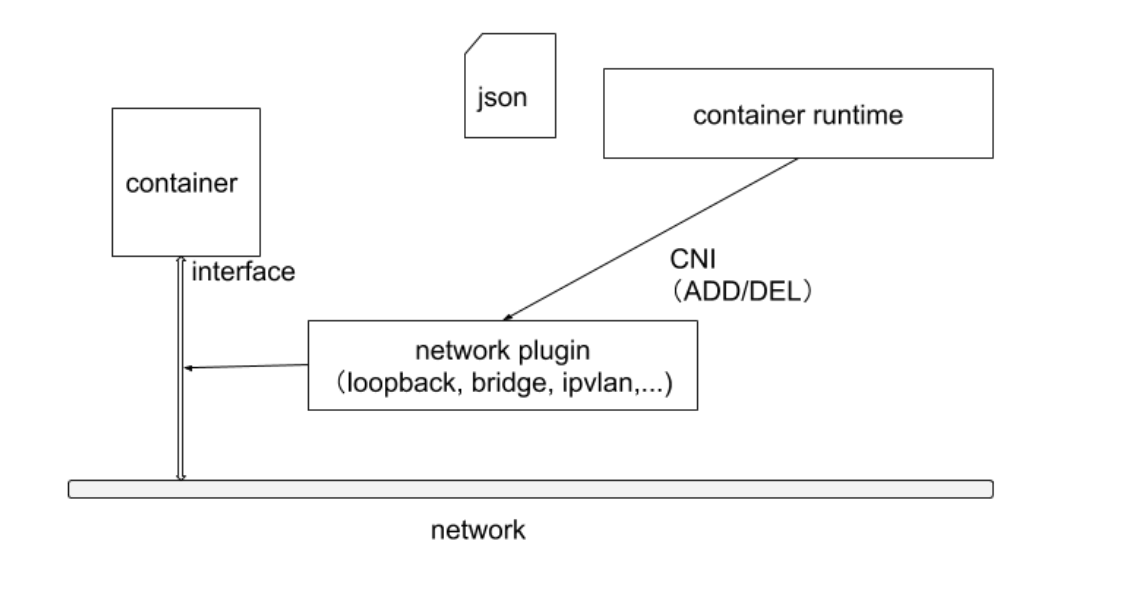
完整的调用链如下:
首先 Pod 是由 kubelet 来起的,然后 kubelet 通过 CRI 接口来起 Pod。
而起 Pod 的过程中又包含 网络相关配置,这部分就要由 CRI 来调用 CNI 实现了。
因此整个调用链就是 kubelet --> CRI --> CNI。
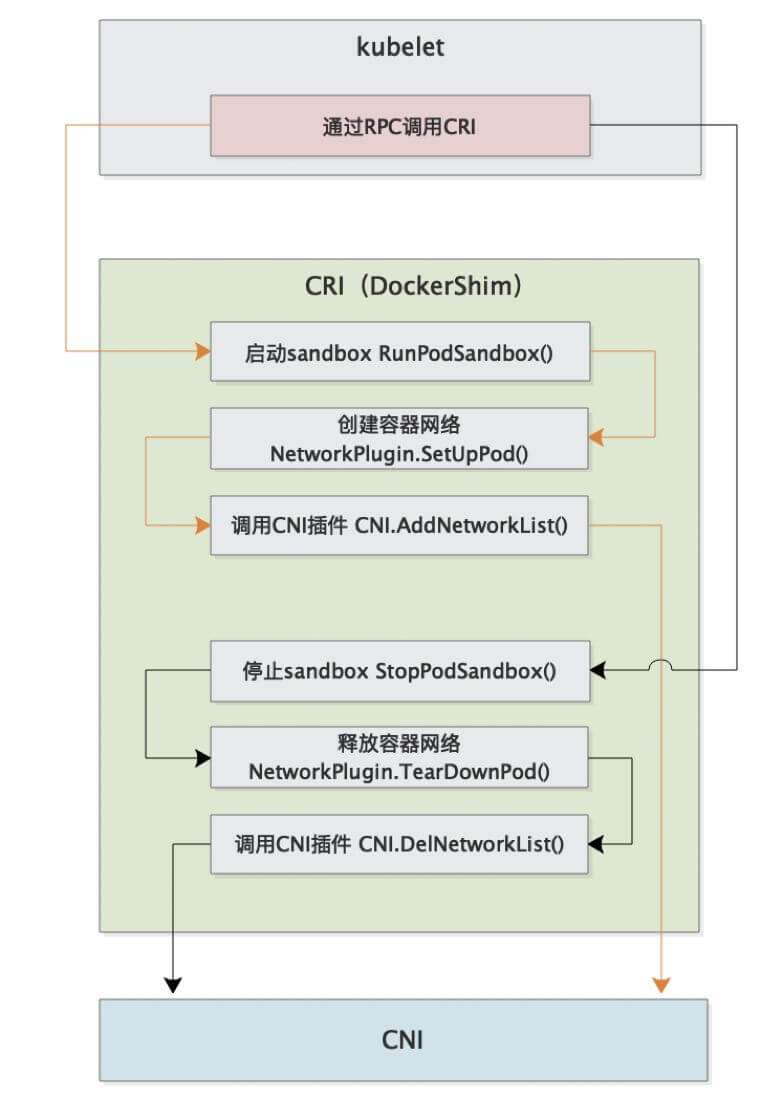
CNI 部署?
CNI 插件部署的时候一般会启动一个 DaemonSet,然后把 镜像里的二进制文件复制到宿主机的 /opt/cni/bin 目录下,这样就算是完成了部署。
因此写一个 CNI 插件实际就是提供一些包含对应功能的二进制文件给 kubelet 调用。
CNI 可以 设置多个,只不过 CNI 是按照顺序执行~
CNI 插件设计考量
- 容器运行时必须在调用任何插件之前为容器创建个新的网络命名空间。
- 容器运行时必须决定这个容器属于哪些网络,针对每个网络,哪些插件必须要执行。
- 容器运行时必须加载配置文件,并确定设置网络时哪些插件必须被执行
- 网络配置采用
JSON格式,可以很容易地存储在文件中。 - 容器运行时必须按顺序执行配置文件里相应的插件
- 在完成容器生命周期后容器运行时必须按照与执行添加容器相反的顺序执行插件,以便将容器与网络断开连接
- 容器运行时被同一容器调用时不能并行操作但被不同的容器调用时,允许并行操作。
- 容器运行时针对一个容器必须按顺序执行 ADD 和 DEL 操作,ADD 后面总是跟着相应的 DEL。DEL 可能跟着额外的 DEL,插件应该允许处理多个 DEL。
- 容器必须由
ContainerID来唯一标识,需要存储状态的插件需要使用网络名称容器 ID 和网络接口组成的主 key 用于索引。 - 容器运行时针对 同一个网络、同一个容器同一个网络接口, 不能连续调用两次 ADD 命令。
打通主机层网络
CNI 插件外,Kubernetes 还需要标准的 CNI 插件 lo,最低版本为 0.2.0 版本。网络插件除支持设置和清理 Pod 网络接口外,该插件还需要支持 Iptables。如果 Kube-proxy 工作在 Iptables 模式,网络插件需要确保容器流量能使用 Iptables 转发。例如,如果网络插件将容器连接到 Linux 网桥,必须将 net/bridge/bridge-nf-call-iptables 参数 sysctl 设置为 1,网桥上数据包将遍历 Iptables 规则。如果插件不使用 Linux 桥接器 ( 而是类似 Open vSwitch或其他某种机制的插件),则应确保容器流量被正确设置了路由。
CNI Plugin
ContainerNetworking 组维护了一些 CNI 插件,包括网络接口创建的 bridge、ipvlan、 loopback、macvlan、ptp、host-device 等,IP 地址分配的 DHCP、host-local 和 static,其他的 Flannel、tunning、portmap、 firewall 等。 社区还有些第三方网络策略方面的插件,例 如Calico、Cilium 和 Weave 等。可用选项的多样性意味着大多数用户将能够找到适合其当前需求和部署环境的 CNI 插件,并在情况变化时迅捷转换解决方案。
Flannel
Flannel 是由 CoreOS 开发的项目,是 CNI 插件早期的入门产品,简单易用。 Flannel 使用 Kubernetes 集群的现有 etcd 集群来存储其状态信息,从而不必提供专用的数据存储,只需要在每个节点上运行 flanneld 来守护进程。
每个节点都被分配一一个子网,为该节点上的 Pod 分配 IP 地址。 同一主机内的 Pod 可以使用网桥进行通信,而不同主机上的 Pod 将通过 flanneld 将其流量封装在 UDP 数据包中,以路由到适当的目的地。 封装方式默认和推荐的方法是使用 VxLAN,因为它具有良好的性能,并且比其他选项要少些人为干预。虽然使用VxLAN 之类的技术封装的解决方案效果很好,但缺点就是该过程使流量跟踪变得困难。
同时 Flannel 不支持 network policy。
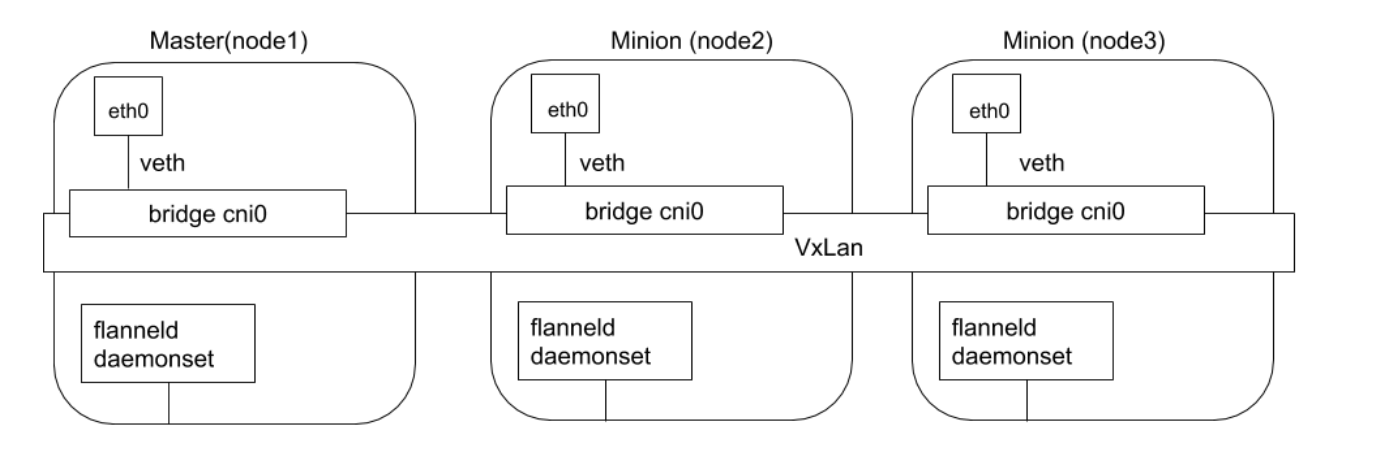
Flannel 通过封包解包方式实现。
Calico
Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全和 策略管理。
对于同网段通信,基于第 3 层,Calico 使用 BGP 路由协议在主机之间路由数据包,使用 BGP 路由协议也意味着数据包在主机之间移动时不需要包装在额外的封装层中。
对于跨网段通信,基于 IPinIP 使用虚拟网卡设备 tunl0,用一个 IP 数据包封装另一个 IP 数据包,外层 IP 数据包头的源地址为隧道入口设备的 IP 地址,目标地址为隧道出口设备的 IP 地址。
网络策略是 Calico 最受欢迎的功能之一,使用 ACLS 协议和 kube-proxy 来创建 iptables 过滤规则,从而实现隔离容器网络的目的。
此外,Calico 还可以与服务网格 Istio 集成,在服务网格层和网络基础结构层上解释和实施集群中工作负载的策略。这意味着可以配置功能强大的规则,以描述 Pod 应该如何发送和接收流量,提高安全性及加强对网络环境的控制。
Calico 属于完全分布式的横向扩展结构,允许开发人员和管理员快速和平稳地扩展部署规模。对于性能和功能(如 网络策略)要求高的环境,Calico 是一个不错选择。
Calico 有两种模式:
- 封包解包的隧道模式
- 动态路由模式
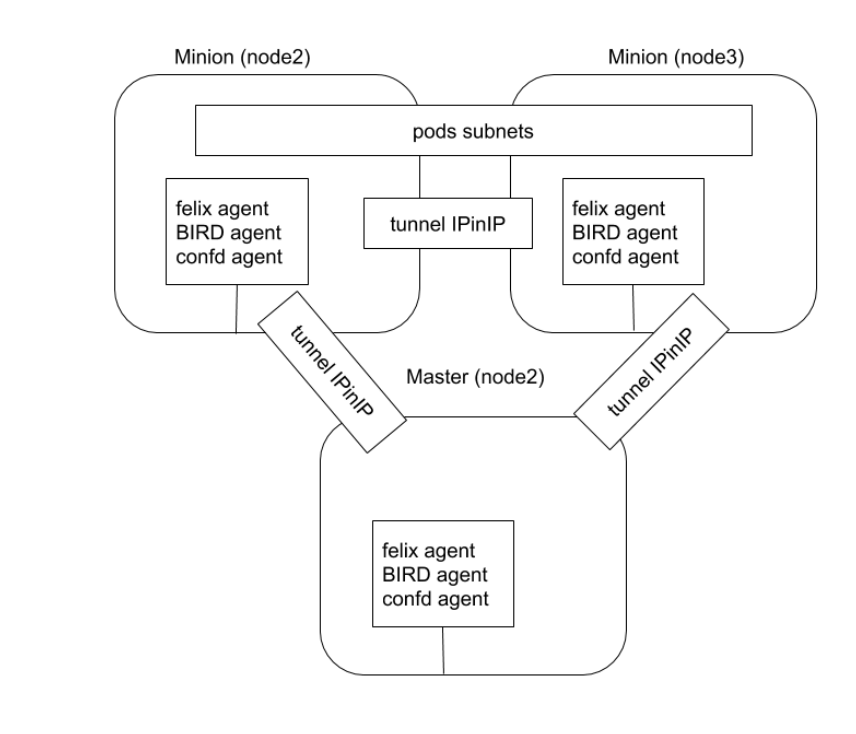
Calico 运行流程
插件部署后会启动 DaemonSet,该 DaemonSet 会把存放配置文件(/etc/cni/net.d)和二进制文件(/opt/cni/bin)的目录挂载到 Pod 里去,后把镜像里的配置文件和二进制文件复制到对应目录。
DaemonSet 会运行再所有节点上,所以添加或者删除节点时都可以处理。
Calico VxLAN
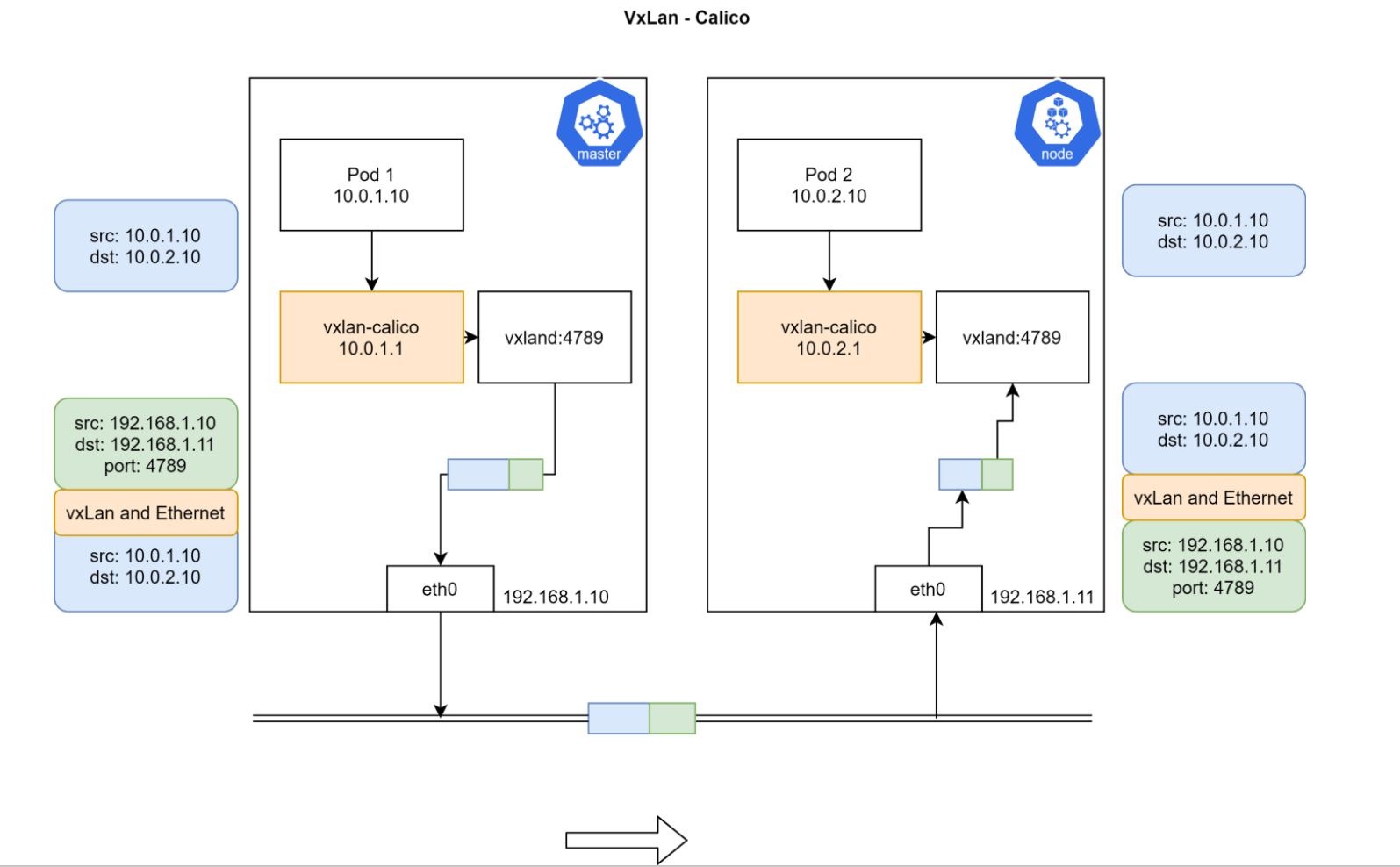
Pod1 和 Pod2 处于不同 Node,且不属于同一网段,无法直接路由到达。
然后安装了 Calico 之后会在每个节点上都有一个 vxland 进程和 vxlan-calico 的网络设备,Pod 中的数据通过 vxlan-calico 设备转发到 vxland 进程,这个 vxland 进程就会进行封包,把 Pod 里发出来的网络包整个作为 payload,然后再次增加 IP 头,这里添加的源IP就是当前节点的IP+vxland 监听的 4789 端口,目标IP就是Pod2所在Node的IP,然后这个包就走外部节点的路由从master 节点到了 node 节点,然后 node 节点的 vxland 进行解包后又通过vxlan-calico 设备进入到 Pod2 里面。
实际和 Flannel 的原理是一样的,都是封包解包
IPAM 数据存储
Calico 默认使用的是在集群中创建 crd 方式来存储。
当前也可以配置其他存储方式
- IPPool:定义一个集群的预定义的 IP 段
- IPAMBlock:定义每个主机预分配的 IP 段
- IPAMHandle:用来记录 IP 分配的具体细节
Calico 数据流转演示
同一节点间不同 Pod
首先启动一个包含大量工具的容器,比如 centos
kubectl run --images=centos centos
然后进入该 Pod
$ k exec -it centos-5fdd4bb694-7cgc8 bash
查看该 Pod 的 IP 和路由信息
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if48: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 16:4c:ec:e4:3a:d6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.119.78/32 brd 192.168.119.78 scope global eth0
valid_lft forever preferred_lft forever
$ ip r
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
可以看到有一个默认路由,所有数据都要通过 eth0 发送到 169.254.1.1 这个IP。
然后使用 arpping 看一下 169.254.1.1 这个 IP 是哪个设备
$ arping 169.254.1.1
ARPING 169.254.1.1 from 192.168.119.78 eth0
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.579ms
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.536ms
发现这个 IP 对应的 mac 地址是 EE:EE:EE:EE:EE:EE.
然后退出容器,到主机上看一下有没有 mac 地址全为 e 的设备
$ ip a
45: calie3f1daf7d15@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 11
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
发现还真有,所有以 cali 开头的设备都是这个 mac 地址,这些实际是 calico 创建的 veth pair,一端在 Pod 里,一端在主机上。
然后再看一下宿主机上的路由信息
[root@agent-1 ~]# ip r
default via 192.168.10.1 dev eth0
169.254.169.254 via 192.168.10.3 dev eth0 proto static
blackhole 172.25.0.128/26 proto 80
172.25.0.131 dev cali1cc9705ed50 scope link
172.25.0.132 dev cali9d0f51d41f9 scope link
172.25.0.133 dev cali4dcdb8d77a9 scope link
172.25.0.134 dev caliac318995356 scope link
发现有好几个 IP 的流量都要转给 cali* 设备,实际上这些流量就是通过 veth pair 又进入到了别的容器里了,这也就是为什么在 Pod 里 ping 别的 Pod 能通。
流量到宿主机转一圈又进入到 Pod 里了。
不同节点上的 Pod
具体节点及 IP 信息如下:
ipamblock:
10-233-90-0-24
node1
cidr: 10.233.90.0/24
ipamblock:
10-233-96-0-24
node: node2
cidr: 10.233.96.0/24
然后 calico 部署后会起一个叫做 bird 的守护进程,该进程的作用就是同步不同节点间的路由信息。
Pod 的网络实际上是一个私有的信息,和组宿主机的网络没有任何关系,其他节点也无法感知当前节点上的 Pod 网段,因此需要借助 bird 这个工具来进行同步。
具体同步的信息就是就是哪个 IP 段和哪个宿主机的 IP 是绑定关系。比如下面的要访问 10.233.96.0/24 这个IP 段就要转发到 192.168.34.11,要访问 10.233.90.0/24 这个 IP 段就需要转发到 192.168.34.10。
因此在 node1 上就会出现这么一条指向 node2 的路由信息
10.233.96.0/24 via 192.168.34.11 dev tunl0 proto bird onlink
同样的 node2 上也有到 node1 的路由信息
10.233.90.0/24 via 192.168.34.10 dev tunl0 proto bird onlink
这样彼此就可以进行通信了。
具体 bird 相关信息可以通过 calico daemonset 中进行查看:
$ k get po -n calico-system calico-node-xk4kn -oyaml
- name: CALICO_NETWORKING_BACKEND
value: bird
name: calico-node
readinessProbe:
exec:
command:
- /bin/calico-node
- -bird-ready
- -felix-ready
failureThreshold: 3
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
在宿主机上查看 bird 进程
$ ps -ef|grep bird
root 2433 2386 0 10:58 ? 00:00:00 runsv bird
root 2435 2386 0 10:58 ? 00:00:00 runsv bird6
root 2505 2469 0 10:58 ? 00:00:00 svlogd -ttt /var/log/calico/bird6
root 2516 2510 0 10:58 ? 00:00:00 svlogd -ttt /var/log/calico/bird
root 3662 2433 0 10:58 ? 00:00:00 bird -R -s /var/run/calico/bird.ctl -d -c /etc/calico/confd/config/bird.cfg
root 3664 2435 0 10:58 ? 00:00:00 bird6 -R -s /var/run/calico/bird6.ctl -d -c /etc/calico/confd/config/bird6.cfg
root 9167 5788 0 11:05 pts/0 00:00:00 grep --color=auto bird
进入 Pod 查看 bird 配置文件
$ k exec -it calico-node-7hmbt -n calico-system cat /etc/calico/confd/config/bird.cfg
router id 192.168.34.2;
protocol direct {
debug { states };
interface -"cali*", -"kube-ipvs*", "*"; # Exclude cali* and kube-ipvs* but
# include everything else. In
# IPVS-mode, kube-proxy creates a
# kube-ipvs0 interface. We exclude
# kube-ipvs0 because this interface
# gets an address for every in use
# cluster IP. We use static routes
# for when we legitimately want to
# export cluster IPs.
}
对应的 iptables 规则:
iptables-save, masq all traffic to outside
-A cali-nat-outgoing -m comment --comment "cali:flqWnvo8yq4ULQLa" -m set --match-set cali40masq-ipam-pools src -m set ! --match-set cali40all-ipam-pools dst -j MASQUERADE --random-fully
CNI Plugin 的对比
如果是上生产的话,一般是考虑 calico 或者 Cilium,Flannel 现在都不维护了。
| 解决方案 | 是否支持网络策略 | 是否支持 ipv6 | 基于网络层级 | 部署方式 | 命令行 |
|---|---|---|---|---|---|
| Calico | 是 | 是 | L3(IPinIP,BGP) | DaemonSet | calicoctl |
| Cilium | 是 | 是 | L3 / L4+L7(filtering) | DaemonSet | cilium |
| Contiv | 否 | 是 | L2(VxLAN) / L3(BGP) | DaemonSet | 无 |
| Flannel | 否 | 否 | L2(VxLAN) | DaemonSet | 无 |
| Weave net | 是 | 是 | L2(VxLAN) | DaemonSet | 无 |
参考文档
CSI
Kubernetes CSI(Container Storage Interface)是针对容器化环境设计的存储接口,用于将持久化存储系统集成到 Kubernetes 集群中。该接口的目的是提高存储系统的可插拔性和可移植性,同时简化了存储系统的管理。
Kubernetes支持以插件的形式来实现对不同存储的支持和扩展,这些扩展基于如下三种方式:
- FlexVolume
- in-tree volume plugins
- CSI
其中 CSI 是一种标准化的存储接口,允许 Kubernetes 与各种存储后端交互。CSI 提高了存储系统的可插拔性和可移植性,并简化了存储系统的管理。通过了解 CSI 的工作原理和使用方法,可以更好地利用 Kubernetes 提供的存储功能。
容器运行时存储
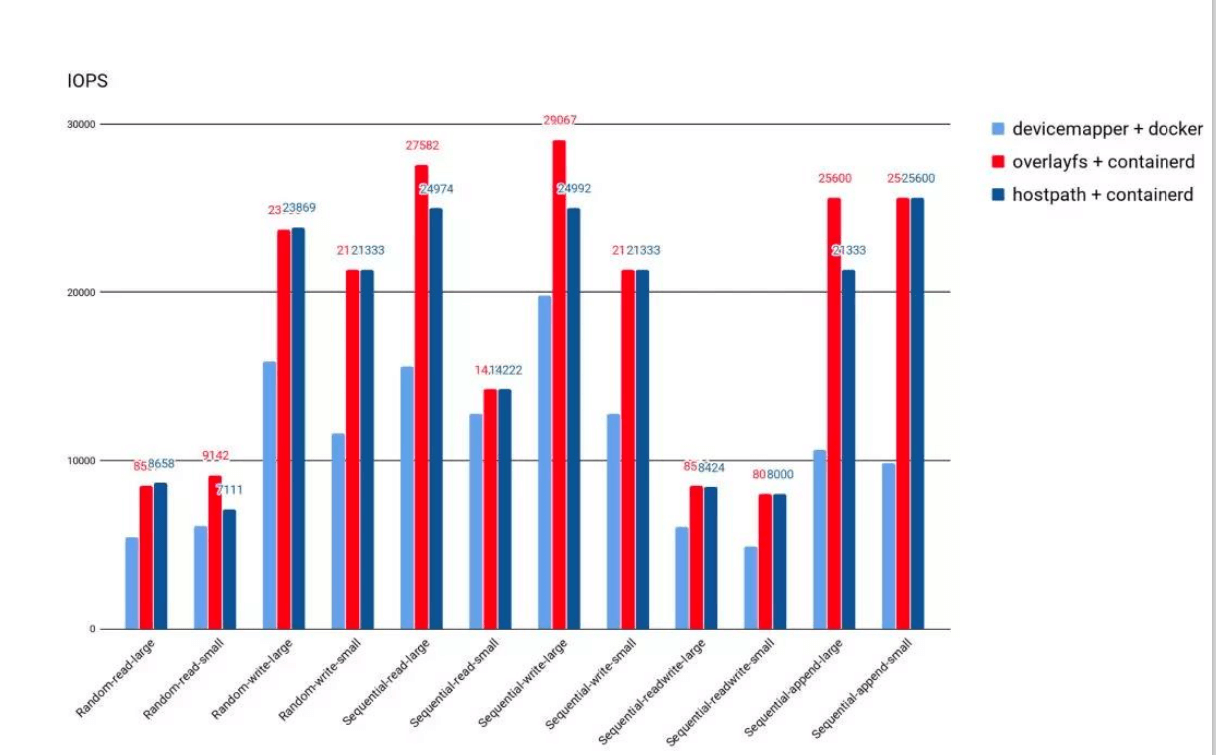
- 除外挂存储卷外,容器启动后,运行时所需文件系统性能直接影响容器性能;
- 早期的 Docker 采用 Device Mapper 作为容器运行时存储驱动,因为 OverlayFS 尚未合并进 Kernel;
- 目前 Docker 和 containerd 都默认以
OverlayFS作为运行时存储驱动; - OverlayFS 目前已经有非常好的性能,与 DeviceMapper 相比优 20%,与操作主机文件性能几乎一致。
注意这是运行时存储,是一个文件系统,这个用作拉取运行时就好了,不建议写任何东西或者日志,这样会影响效率。
存储卷插件管理
Kubernetes支持以插件的形式来实现对不同存储的支持和扩展,这些扩展基于如下三种方式:
in-tree插件:直接下载 k8s 仓库中的插件,当前 k8s 社区已经不在接受新的in-tree存储插件了,必须以 out-of-tree 插件方式支持out-of-tree FlexVolume插件:这个模式也逐渐取消了FlexVolume是指 Kubernetes 通过调用计算节点的本地可执行文件与存储插件进行交互FlexVolume插件需要宿主机用 root 权限来安装插件驱动FlexVolume存储驱动需要宿主机安装 attach、mount 等工具,也需要具有 root 访问权限。
out-of-tree CSI插件:CSI 插件通过 RPC 与存储驱动交互,当前主流的插件形式。
思考:CNI 插件是否也可以改成这种调用方式?
Kubernetes CSI 是专门为容器化环境设计的存储接口允许 Kubernetes 与各种存储后端交互。CNI 插件(Container Network Interface)也是 Kubernetes 的插件之一,但是它与 CSI 的功能和作用是不同的。CNI 插件用于将网络插件集成到 Kubernetes 中,用于为容器提供网络服务,而 CSI 插件则用于将持久化存储系统集成到 Kubernetes 集群中,用于为容器提供持久化存储服务。虽然 CNI 插件和 CSI 插件都是插件机制,但它们的调用方式和实现方式是不同的,因此不能将 CNI 插件改为 CSI 插件的调用方式。
CSI 插件
CSI 驱动程序是 CSI 接口与存储后端之间的桥梁。它们允许 Kubernetes 与各种存储后端(如本地存储、网络存储、云存储)交互,并且可以以插件方式加载和卸载。
Kubernetes 社区已经为一些存储后端(如 Ceph、NFS 和 AWS EBS)编写了 CSI 驱动程序,并且支持其他存储后端编写自己的 CSI 驱动程序。这些驱动程序允许 Kubernetes 与存储后端交互,并将存储后端的功能暴露给 Kubernetes 用户。
在设计 CSI 的时候,Kubernetes 对 CSI 存储驱动的打包和部署要求很少,主要定义了 Kubernetes 的两个相关 模块:
- kube-controller-manager :
- kube-controller-manager 模块用于感知 CSI 驱动存在。
- Kubernetes 的主控模块通过 Unix domain socket (而不是 CSI 驱动)或者其他方式进行直接地交互。
- Kubernetes 的主控模块只与 Kubernetes 相关的 API 进行交互,因此 CSI 驱动若有依赖于 Kubernetes API 的操作,例如卷的创建 、卷的 attach、 卷的快照等,需要在 CSI 驱动里面通过 Kubernetes 的 API,来触发相关的 CSI 操作。
- kubelet:
- kubelet 模块用于与 CSI 驱动进行交互。
- kubelet 通过 Unix domain socket 向CSI 驱动发起 CSI 调用(如 NodeStageVolume、NodePublishkubelet通过插件注册机制发现CSI驱动及用于和CSI驱动交互的Unix Domain Socket。Volume等),再发起 mount 卷和 umount 卷。
- kubelet 通过插件注册机制发现 CSI 驱动及用于和 CSI 驱动交互的 Unix Domain Socket。
- 所有部署在 Kubernetes 集群中的 CSI 驱动都要通过 kubelet 的插件注册机制来注册自己。
使用CSI插件:
要使用 CSI,需要完成以下步骤:
- 安装 CSI 驱动程序: 可以从存储后端厂商或 Kubernetes 社区中获取 CSI 驱动程序,并将其安装在 Kubernetes 集群中。安装过程包括将 CSI 驱动程序二进制文件放在正确的位置、创建 CSI 驱动程序的 DaemonSet 和 ConfigMap 等。
- 创建 StorageClass: StorageClass 定义了如何为动态卷分配存储。可以使用 kubectl 命令或 YAML 文件创建 StorageClass。在创建 StorageClass 时,需要指定存储后端、存储类型、卷大小等参数。
- 创建 PersistentVolumeClaim(PVC): PVC 是请求容器卷的声明。可以使用 kubectl 命令或 YAML 文件创建 PVC。在创建 PVC 时,需要指定 StorageClass、卷大小、访问模式等参数。
- 使用 PVC: 可以将 PVC 附加到 Pod 上并在其中引用它。在定义 Pod 时,需要将 PVC 的名称指定为 volumeMounts 和 volumes 字段中的一部分。
CSI 驱动
CSI的驱动一般包含 external-attacher、external-provisioner、 external-resizer、 external-snapshotter、node-driver-register、 CSI driver 等模块,可以根据实际的存储类型和需求进行不同方式的部署。
| 模块 | 描述 |
|---|---|
| external-attacher | 用于将已有的存储卷附加到节点上 |
| external-provisioner | 用于在存储后端创建新的存储卷并将其附加到节点上 |
| external-resizer | 用于调整存储卷的大小 |
| external-snapshotter | 用于为存储卷创建快照,并在需要时还原它们 |
| node-driver-register | 用于将 CSI 驱动程序注册到 Kubernetes 节点上 |
| CSI driver | 用于实现 CSI 接口并与存储后端交互 |
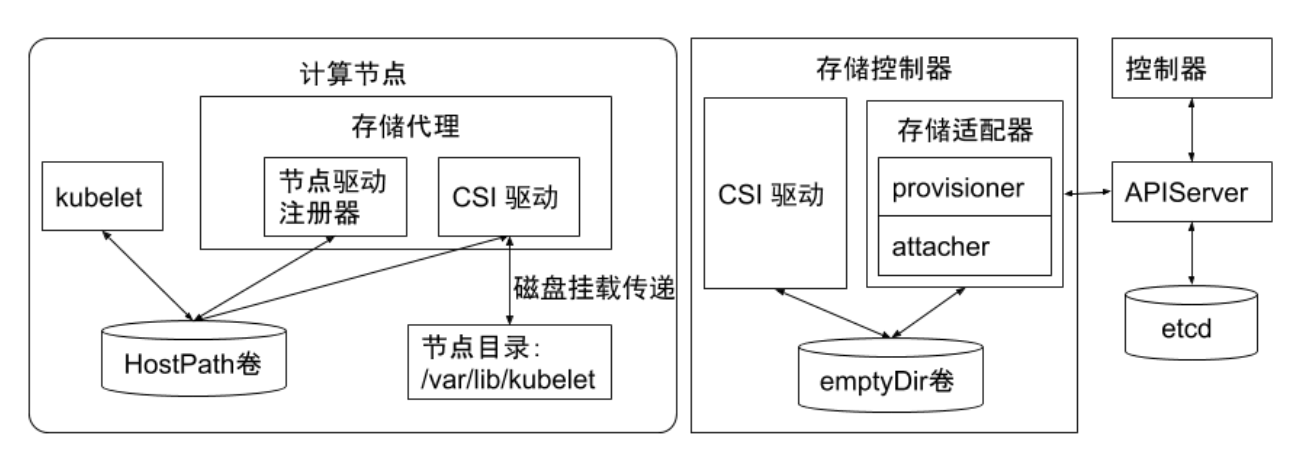
hostPath 卷是 Kubernetes 中最简单和最常见的一种卷类型,它可以将节点上的目录或文件挂载到容器中。hostPath 卷非常适合用于临时存储,如日志文件等。但是,由于 hostPath 卷的生命周期与 Pod 的生命周期密切相关,因此它并不适合用于持久化存储。如果 Pod 被删除,hostPath 卷中的数据不被清理就会留在这边。。
emptyDir 卷是 Kubernetes 中另一种简单的卷类型,它是一个空目录,并在 Pod 创建时创建。emptyDir 卷可以用于在容器之间共享文件,也可以用于存储临时数据,如日志文件等。与 hostPath 卷不同,emptyDir 卷的生命周期与 Pod 的生命周期相同。当 Pod 被删除时,emptyDir 卷中的数据也会被删除。
- 半持久化存储卷(EmptyDir):存储在 Pod 生命周期内的临时数据卷,用于将数据存储在容器之间共享,但在 Pod 重新启动时,数据将被清除。
- 临时存储卷:在 Pod 生命周期结束时将被删除的存储卷,通常用于存储临时数据,如日志文件。这种卷不需要手动清理,因为它们会随着 Pod 的删除而自动清理。
- 持久化存储卷:可以在 Pod 之间共享的存储卷,即使 Pod 重新启动或重新调度也可以保留数据。 Kubernetes 支持多种类型的持久化存储卷,如 NFS、iSCSI、HostPath、AWS EBS 等。
除了这三种存储卷外,还可以通过定义自定义存储卷来扩展 Kubernetes 的存储功能。自定义存储卷可以通过 Kubernetes 插件或外部存储系统来实现。
在使用存储卷时,需要在 Pod 的 YAML 配置文件中定义一个或多个卷,然后在容器中使用 volumeMounts 来挂载这些卷。这样,容器就可以访问卷中存储的数据。
如果需要使用持久化存储卷来存储数据,还需要在 Kubernetes 集群中设置存储类。存储类是用于定义存储卷类型的 Kubernetes 资源,它可以将 PVC 映射到特定的存储卷类型和提供商。
临时存储卷
常见的临时存储主要就是 emptyDir 卷。
emptyDir 是一种经常被用户使用的卷类型,顾名思义,“卷”最初是空的。当 Pod 从节点上删除时,emptyDir 卷中的数据也会被永久删除。但当Pod的容器因为某些原因退出再重启时,emptyDir 卷内的数据并不会丢失。
默认情况下,emptyDir 卷存储在支持该节点所使用的存储介质上,可以是本地磁盘或网络存储。 emptyDir 也可以通过将 emptyDir.medium 字段设置为"Memory" 来通知 Kubernetes 为容器安装 tmpfs,此时数据被存储在内存中,速度相对于本地存储和网络存储快很多。但是在节点重启的时候,内存数据会被清除;
而如果存在磁盘上,则重启后数据依然存在。另外,使用 tmpfs 的内存也会计入容器的使用内存总量中,受系统的Cgroup 限制。
emptyDir 设计的初衷主要是给应用充当缓存空间,或者存储中间数据,用于快速恢复。 然而,这并不是说满足以上需求的用户都被推荐使用 emptyDir,我们要根据用户业务的实际特点来判断是否使用 emptyDir。因为 emptyDir 的空间位于系统根盘,被所有容器共享,所以在磁盘的使用率较高时会触发 Pod 的 eviction 操作,从而影响业务的稳定。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: test-container
image: ubuntu
volumeMounts:
- name: my-volume
mountPath: /data
volumes:
- name: my-volume
emptyDir:
medium: Memory
半持久化存储
常见的半持久化存储主要是 hostPath 卷。hostPath 卷能将主机节点文件系统上的文件或目录挂载到指定 Pod中。
对普通用户而言一般不需要这样的卷,但是对很多需要获取节点系统信息的 Pod 而言,却是非常必要的。 例如,hostPath 的用法举例如下:
- 某个 Pod 需要获取节点上所有 Pod 的 log, 可以通过 hostPath 访问所有 Pod 的 stdout 输出存储目录,例如
/var/log/pods路径。 - 某个 Pod 需要统计系统相关的信息,可以通过 hostPath 访问系统的
/proc目录。
使用 hostPath 的时候,除设置必需的 path 属性外,用户还可以有选择性地为 hostPath 卷指定类型,支持类型包含目录、字符设备、块设备等。
hostpath 注意事项
- 使用同一个目录的 Pod 可能会由于调度到不同的节点,导致目录中的内容有所不同。
- Kubernetes 在调度时无法顾及由 hostPath 使用的资源。
- Pod 被删除后,如果没有特别处理,那么 hostPath上写的数据会遗留到节点上,占用磁盘空间。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: test-container
image: ubuntu
volumeMounts:
- name: my-volume
mountPath: /data
volumes:
- name: my-volume
emptyDir: {}
持久化存储
支持持久化的存储是所有分布式系统所必备的特性。
针对持久化存储,Kubernetes 引入了 StorageClass、Volume、 PVC ( Persistent Volume Claim)、PV (Persitent Volume)的概念,将存储独立于 Pod 的生命周期来进行管理。
Kuberntes 目前支持的持久化存储包含各种主流的块存储和文件存储,譬如 awsElasticBlockStore、azureDisk、cinder、 NFS、 cephfs、 iscsi 等,在大类上可以将其分为网络存储和本地存储两种类型。
StorageClass
StorageClass 用于指示存储的类型,不同的存储类型可以通过不同的 StorageClass 来为用户提供服务。
StorageClass 主要包含存储插件 provisioner、卷的创建和 mount 参数等字段。
PVC
由用户创建,代表用户对存储需求的声明,主要包含需要的存储大小、存储卷的访问模式、StroageClass 等类型,其中存储卷的访问模式必须与存储的类型一致。
- RWO:ReadWriteOnce,该卷只能在一个节点上被 mount,属性为可读写
- ROX:ReadOnlyMany,该卷可以在不同节点上被 mount,属性为可读
- RWX:ReadWriteMany,该卷可以在不同节点上被 mount,属性为可读写
PV
由集群管理员提前创建,或者根据 PVC 的申请需求动态地创建,它代表系统后端的真实的存储空间,可以称之为卷空间。
在 k8s 中创建一个 pv 来代表外部系统的存储空间。
存储对象关系
用户通过创建 PVC 来申请存储。控制器通过 PVC 的 StorageClass 和请求的大小声明来存储后端创建卷,进而创建 PV, Pod 通过指定 PVC 来引用存储。
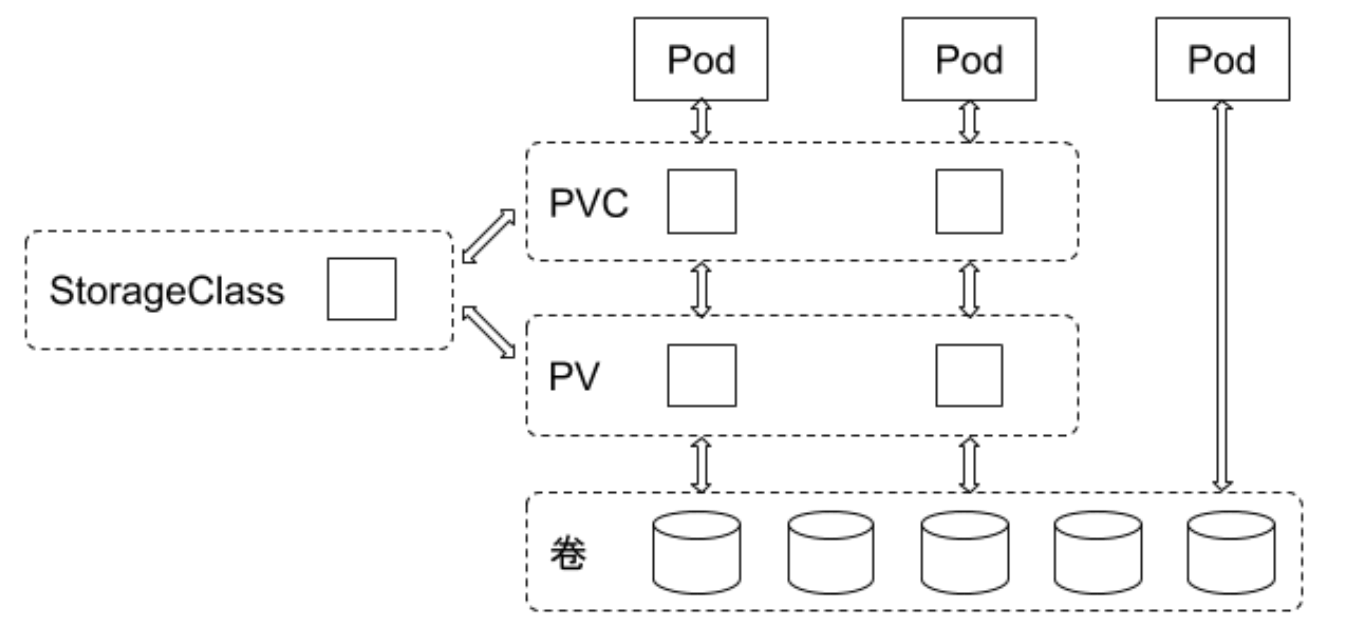
pod 什么需要使用的 pvc,pvc 和 pv 关联,pv 对应后端存储。
具体需要创建哪个插件控制的后端存储就是由 pvc 中指定的 StorageClass 来控制了。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: test-container
image: ubuntu
volumeMounts:
- name: my-volume
mountPath: /data
volumes:
- name: my-volume
persistentVolumeClaim:
claimName: my-pvc
生产实践经验分享
不同介质类型的磁盘,需要设置不同的 StorageClass,以便让用户做区分。StorageClass 需要设置磁盘介质的类型,以便用户了解该类存储的属性。
在本地存储的PV静态部署模式下,每个物理磁盘都尽量只创建一个 PV,而不是划分为多个分区来提供多个本地存 储PV,避免在使用时分区之间的 I/O 干扰。
本地存储需要配合磁盘检测来使用。当集群部署规模化后,每个集群的本地存储 PV 可能会超过几万个,如磁盘损坏将是频发事件。此时,需要在检测到磁盘损坏、丟盘等问题后,对节点的磁盘和相应的本地存储 PV 进行特定的处理,例如触发告警、自动 cordon 节点、自动通知用户等。
对于提供本地存储节点的磁盘管理,需要做到灵活管理和自动化。节点磁盘的信息可以归一、集中化管理。在 local-volume- provisioner 中增加部署逻辑,当容器运行起来时,拉取该节点需要提供本地存储的磁盘信息,例如磁盘的设备路径,以 Filesystem 或 Block 的模式提供本地存储,或者是否需要加入某个 LVM 的虚拟组(VG)等。 local-volume-provisioner 根据获取的磁盘信息对磁盘进行格式化,或者加入到某个 VG,从而形成对本地存储支 持的自动化闭环。
建议:
- 为避免数据丢失,推荐使用持久化存储卷。在使用持久化存储卷时,应考虑备份和恢复策略,以及卷的大小和性能要求。
- 避免在 Pod 生命周期内使用半持久化存储卷(EmptyDir)存储重要数据。如果需要在容器之间共享数据,请使用持久化存储卷。
- 对于需要临时存储数据的场景,建议使用临时存储卷。这种卷会在 Pod 生命周期结束时自动清理,无需手动清理。
- 在使用存储卷时,请确保您的容器映像具有必要的文件系统和工具,以便访问卷中的数据。
- 如果您需要使用自定义存储卷,请确保插件或外部存储系统已正确配置。
- 在定义存储卷和 PVC 时,请使用有意义的名称,以便于识别和管理。
- 在设置存储类时,请考虑您的应用程序的性能和可靠性需求。不同的存储类可能具有不同的性能和可靠性特征。
- 在使用存储卷时,应遵循 Kubernetes 的最佳实践和安全准则。
独占的 LocalVolume
除了 Kubernetes 支持的三种存储卷类型外,还可以使用 LocalVolume 来创建独占的本地存储卷。 LocalVolume 是 Kubernetes 中的一种存储类型,它将 Pod 与本地磁盘上的目录或设备关联起来,以提供独占的存储空间。LocalVolume 适用于需要本地磁盘访问的应用程序,例如数据库或文件服务器。
以下是使用 LocalVolume 的示例 YAML 配置:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: test-container
image: ubuntu
volumeMounts:
- name: my-volume
mountPath: /data
volumes:
- name: my-volume
local:
path: /mnt/disks/data
在上述示例中,我们将 Pod 与路径 /mnt/disks/data 上的本地磁盘目录关联起来,以提供独占的存储空间。我们使用 local 类型指定卷类型,并将路径指定为 path 字段的值。
与其他存储卷类型不同,LocalVolume 不能被多个 Pod 共享。这是因为本地磁盘上的文件系统和数据只能被一个 Pod 访问。如果需要在多个 Pod 之间共享数据,应该使用其他类型的存储卷,例如 NFS 或 iSCSI。
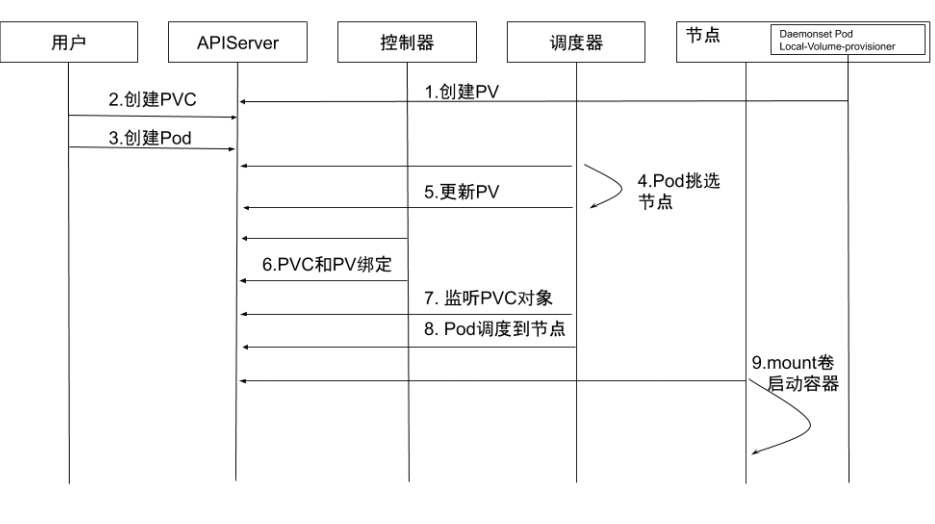
- 创建 PV:通过
local-volume-provisioner DaemonSet创建本地存储的 PV。 - 创建 PVC:用户创建 PVC,由于它处于 pending 状态,所以kube-controller-manager 并不会对该 PVC 做任何操作。
- 创建Pod:用户创建Pod。
- Pod 挑选节点:kube-scheduler 开始调度 Pod,通过 PVC 的
resources.request.storage和 volumeMode 选择满足条件的 PV,并且为 Pod 选择一个合适的节点。 - 更新PV:kube-scheduler 将 PV 的
pv.Spec.claimRef设置为对应的 PVC,并且设置annotation pv.kubernetes.io/ bound-by-controller的值为 "yes" 。 - PVC 和 PV绑定:
pv_controller同步 PVC 和 PV 的状态,并将 PVC 和 PV 进行绑定。 - 监听PVC对象:kube-scheduler 等待 PVC 的状态变成 Bound 状态。
- Pod调度到节点:如果 PVC 的状态变为 Bound 则说明调度成功,而如果 PVC 一直处于 pending 状态,超时后会再次进行调度。
- Mount 卷启动容器:kubelet 监听到有 Pod 已经调度到节点上,对本地存储进行 mount 操作,并启动容器。
Dynamic Local Volume
Dynamic Local Volume 是 Kubernetes 中的一种存储卷类型,它可以动态地创建和删除本地存储卷,以提供独占的存储空间。与其他类型的存储卷不同,Dynamic Local Volume 不需要提前手动创建本地存储卷,而是在 Pod 创建时动态地创建本地存储卷。这使得在 Kubernetes 集群中使用本地存储卷更加灵活和方便。
Dynamic Local Volume 可以通过 Kubernetes 插件或本地存储系统来实现。在使用 Dynamic Local Volume 之前,需要先在 Kubernetes 集群中设置 LocalVolumeDiscovery 插件。LocalVolumeDiscovery 插件用于自动发现并创建本地存储卷,以便将其与 Pod 关联起来。
CSI 驱动需要汇报节点上相关存储的资源信息,以便用于调度
但是机器的厂家不同,汇报方式也不同。
例如,有的厂家的机器节点上具有 NVMe、SSD、 HDD 等多种存储介质,希望将这些存储介质分别进行汇报。
这种需求有别于其他存储类型的 CSI 驱动对接口的需求,因此如何汇报节点的存储信息,以及如何让节点的存储信息应用于调度,目前并没有形成统一的意见。
集群管理员可以基于节点存储的实际情况对开源 CSI 驱动和调度进行一些代码修改, 再进行部署和使用
Local Dynamic 的挂载流程
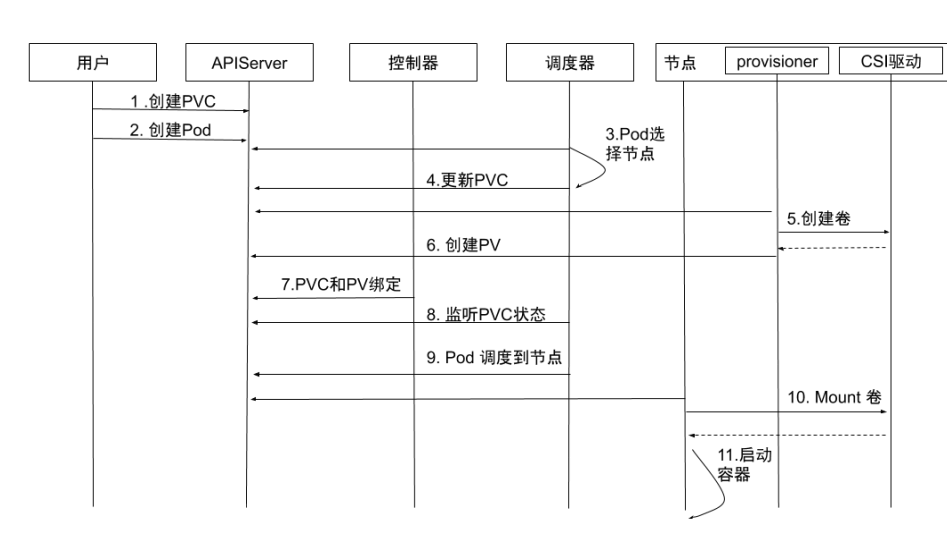
- 创建PVC:用户创建 PVC,PVC 处于 pending 状态。
- 创建 Pod:用户创建 Pod。
- Pod选择节点: kube-scheduler 开始调度 Pod,通过 PVC 的 pvc.spec.resources.request.storage 等选择满足条件的节点。
- 更新 PVC:选择节点后,kube-scheduler 会给 PVC 添加包含节点信息的
annotation:volume.kubernetes.io/selected-node: <节点名字>。 - 创建卷:运行在节点上的容器 external-provisioner 监听到 PVC 带有该节点相关的 annotation,向相应的 CSI 驱动申请分配卷。
- 创建PV: PVC 申请到所需的存储空间后,external-provisioner 创建 PV,该 PV 的
pv.Spec.claimRef设置为对应的 PVC。 - PVC和PV绑定:kube-controller-manager 将PVC 和 PV 进行绑定,状态修改为 Bound。
- 监听PVC状态:kube-scheduler 等待 PVC 变成 Bound 状态。
- Pod调度到节点:当PVC的状态为 Bound 时,Pod 才算真正调度成功了。如果 PVC 一直处于 Pending 状态,超时后会再次进行调度。
- Mount 卷:kubelet 监听到有 Pod 已经调度到节点上,对本地存储进行 mount 操作。
- 启动容器:启动容器。
Local Dynamic 的挑战
如果将磁盘空间作为一个存储池(例如 LVM )来动态分配,那么在分配出来的逻辑卷空间的使用上,可能会受到其他逻辑卷的 I/O 干扰,因为底层的物理卷可能是同一个。
如果 PV 后端的磁盘空间是一块独立的物理磁盘,则 I/O 就不会受到干扰。
Rook
Rook是一款云原生环境下的开源分布式存储编排系统,目前支持 Ceph、NFS、EdgeFS、Cassandra、CockroachDB 等存储系统。它实现了一个自动管理的、自动扩容的、自动修复的分布式存储服务。
Rook 支持自动部署、启动、配置、分配、扩容/缩容、升级、迁移、灾难恢复、监控以及资源管理。
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©