第54节 Kubernetes 生命周期管理和服务发现
❤️💕💕新时代拥抱云原生,云原生具有环境统一、按需付费、即开即用、稳定性强特点。Myblog:http://nsddd.top
[TOC]
有何优雅的管理Pod生命周期
要优雅地管理Pod的生命周期,可以避免容器进程被终止和Pod被驱逐,设置合理的资源限制和确保数据写入不超过emptyDir的限制,防止OOMKill和Pod被驱逐。此外,还可以设置健康检查探针,包括livenessProbe、readinessProbe和startupProbe,其中readinessProbe可在livenessProbe执行前处理状态。探测方法包括ExecAction、TCPSocketAction和HTTPGetAction。可以通过添加readinessGates condition来引入自定义的就绪条件,除了由k8s内部的探针控制之外,还可以由k8s外部controller来控制。
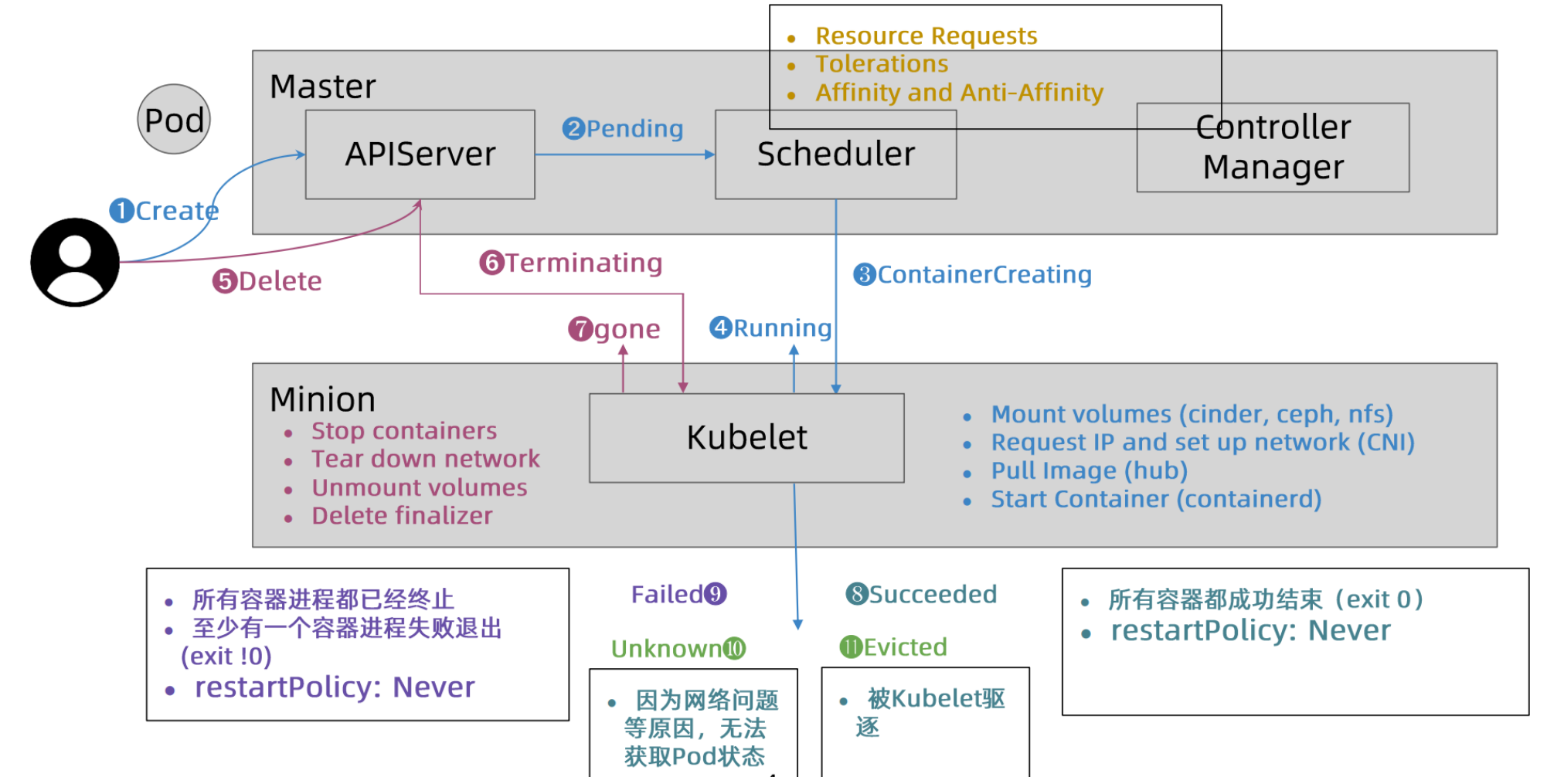
Pod 状态机
Pod 的状态可以分为以下几种:
- Pending:Pod 已被创建,但是还未被分配到节点上运行。
- Running:Pod 已经被调度到节点上运行,并且至少有一个容器正在运行。
- Succeeded:Pod 中所有的容器都已经成功运行结束,且不会再重启。
- Failed:Pod 中至少有一个容器已经运行失败,并且处于不能恢复的状态,或者容器因为 OOM 等原因被操作系统强制终止。
- Unknown:无法获取 Pod 的状态信息,通常是由于调度器或者控制器组件出现问题导致的。
在 Pod 运行过程中,由于各种原因,Pod 的状态可能会发生变化,比如容器意外终止、节点故障等。Kubernetes 会不断地监控 Pod 的状态,确保 Pod 能够保持正常运行。
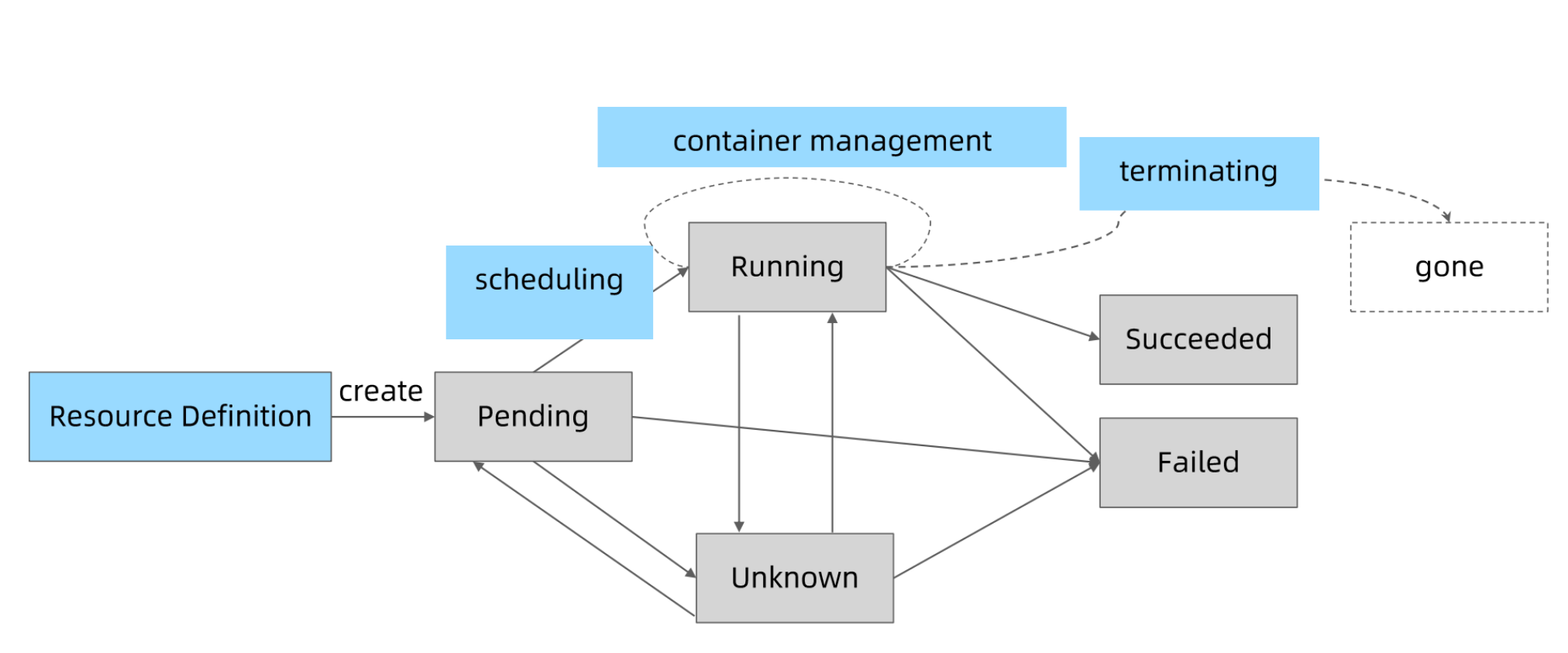
Pod Phase
kubectl get pod 显示的状态信息是由 podstatus 的 conditions 和 phase 计算出来的
Pod 状态计算细节
要查看 Pod 的细节,可以使用 kubectl get pod $podname -oyaml 命令来查看。此外,可以通过 kubectl describe pod 命令来查看与该 Pod 相关的事件。
以下是计算 Pod 状态的详细信息:
| kubectl get pod 返回的状态 | Pod Phase | Conditions |
|---|---|---|
| Completed | Succeded | |
| ContainerCreating | Pending | |
| CrashLoopBackOff | Running | Container exits |
| CreateContainerConfigError | Pending | configmap 'xxx' not foundsecret 'xxx' not found |
| ErrImagePullI | ||
| magePullBackOff | ||
| Init:ImagePullBackOff | ||
| InvalidImageName | Pending | Back-off pulling image |
| Error | Failed | restartPolicy:Nevercontainer exits with error(exit code not 0) |
| Evicted | Failed | message: 'Usage of EmptyDir volume 'myworkdir" exceeds the limit "40Gi". 'reason: Evicted |
| Init:0/1 | Pending | Init container don't exit |
| Init:CrashLoopBackOffInit:Error | Pending | Init container crashed (exit with not 1) |
| OOMKilled | Running | Containers are OOMKilled |
| StartError | Running | Containers can not be started |
| Unknown | Running | Node NotReady |
| OutOfCpu / OutOfMemory | Failed | Scheduled, but it cannot pass kubelet admit |
要保证 Pod 的高可用性,可以采取以下措施:
- 设置合理的资源限制和确保数据写入不超过 emptyDir 的限制,防止容器进程被终止和 Pod 被驱逐。
- 定义 Guaranteed 类型的资源需求来保护重要的 Pod。
- 认真考虑 Pod 的真实需求并设置
limit和resource,这可以将集群资源利用率控制在合理范围并减少 Pod 被驱逐的现象。 - 避免将生产 Pod 设置为 BestEffort,但是对于测试环境来说,BestEffort Pod 能确保大多数应用不会因为资源不足而处于 Pending 状态。
- Burstable 适用于大多数场景。
如果需要避免 Pod 被驱逐,可以增加 tolerationSeconds 的值,特别是对于依赖于本地存储状态的有状态应用来说。
健康检查探针分为 livenessProbe、readinessProbe 和 startupProbe,其中 readinessProbe 可以在 livenessProbe 执行前处理状态,探测方法包括 ExecAction、TCPSocketAction 和 HTTPGetAction。可以通过添加 readinessGates condition 来引入自定义的就绪条件。探针属性包括 initialDelaySeconds、periodSeconds、timeoutSeconds、successThreshold 和 failureThreshold。
查看pod细节:
kubectl get pod $podname -oyaml
查看pod相关事件:
kubectl describe pod
如何保证 Pod 的高可用
避免容器进程被终止避免Pod被驱逐
- 设置合理的
resources.memory limits防止容器进程被 OOMKill - 设置合理的
emptydir.sizeLimit并且确保数据写入不超过 emptyDir 的限制, 防止 Pod 被驱逐
Pod 的 Qos 分类
Kubernetes 中的 QoS(Quality of Service)是用来描述 Pod 对节点资源的需求和请求,以及在节点资源不足时 Kubernetes 如何处理 Pod 的策略。QoS 总共有三种类型:Guaranteed、Burstable 和 BestEffort。
Guaranteed:Pod 请求了所有的资源,kubelet 会保证这些资源被分配到 Pod 中,如果资源不足,Pod 会处于 Pending 状态。Burstable:Pod 请求了最小的资源,但可以加倍使用,直到达到请求的上限。如果资源不足,Pod 会被暂停或者调度到其他节点。BestEffort:Pod 请求了最小的资源,但不必保证资源分配到 Pod 中。如果资源不足,Pod 会被暂停或者调度到其他节点。
QoS 类型的判断依据是 Pod 所请求的 CPU 和内存的 request 和 limit。如果 request 和 limit 相等,那么 Pod 的 QoS 类型就是 Guaranteed;如果 limit 大于 request,那么 Pod 的 QoS 类型就是 Burstable;如果 request 和 limit 都为 0,那么 Pod 的 QoS 类型就是 BestEffort。
- Guaranteed
- Pod 的每个容器都设置了资源 CPU 和内存需求
- Limits 和 requests 的值完全一 致
- Burstable
- 至少一个容器指定了 CPU 或内存 request
- Pod 的资源需求不符合 Gauranteed QoS 的条件,也就是 requests 和 limits 不一致
- BestEffort
- Pod中的所有容器都未指定CPU或内存资源需求requests
当计算节点检测到内存压力时,Kubernetes 会按 BestEffort-> Burstable->Guaranteed 的顺序依次驱逐 Pod。
$ kubectl get pod test-vfgg6 -oyaml |grep qosClass
qosClass: Burstable
- 定义 Guaranteed 类型的资源需求来保护你的重要 Pod
- 认真考量 Pod 需要的真实需求并设置 limit 和 resource,这有利于将集群资源利用率控制在合理范围并减少 Pod 被驱逐的现象。
- 尽量避免将生产 Pod 设置为 BestEffort,但是对测试环境来讲,BestEffort Pod 能确保大多数应用不会因为资源不足而处于 Pending 状态。
- Burstable 适用于大多数场景。
- 思考:为什么?
- 为了节省资源,Guaranteed 类型 Pod 占用的资源 k8s 会优先保证,不足时就驱逐 Pod, 如果实际 Pod 没有消耗掉申请的资源就会造成浪费。
基于Taint的Evictions
基于 Taint 的 Evictions 是 Kubernetes 中的一种节点驱逐机制。当节点临时不可达,比如出现网络分区、kubelet 或 containerd 不工作等情况,或者节点重启超过 15 分钟时,就会触发该机制,从而保证 Pod 的高可用性。为了避免被驱逐,可以增大 tolerationSeconds 的值,特别是对于依赖于本地存储状态的有状态应用来说。
- 节点临时不可达
- 网络分区
- kubelet, containerd 不工作
- 节点重启超过了15 分钟
- 增大tolerationSeconds 以避免被驱逐
- 特别是依赖于本地存储状态的有状态应用
健康检查探针
健康检查探针是 Kubernetes 中的一种机制,用于检测 Pod 中容器的运行状态。健康探针类型分为:livenessProbe、readinessProbe 和 startupProbe。其中,livenessProbe 用于探活,当检测到容器不健康时,Kubernetes 会自动重启该容器;readinessProbe 用于探测容器是否已经准备好接收流量,如果容器无法处理流量,Kubernetes 会将其从 Service 中删除,从而避免流量被分配到不健康的容器上;startupProbe 用于在容器启动时检查应用程序是否已经启动成功,如果应用程序没有启动成功,那么 Kubernetes 会认为容器不健康。探测方法包括 ExecAction、TCPSocketAction 和 HTTPGetAction。探针属性包括 initialDelaySeconds、periodSeconds、timeoutSeconds、successThreshold 和 failureThreshold。
健康探针类型分为:
- livenessProbe
- 探活,当检查失败时,意味着该应用进程已经无法正常提供服务, kubelet 会终止该容器进程并按照 restartPolicy 决定是否重启
- 在该探针执行前 Pod 默认就是存活状态
- readinessProbe
- 就绪状态检查,当检查失败时,意味着应用进程正在运行,但因为某些原因不能提供服务,Pod 状态会被标记为NotReady
- 默认为 NotReady,Pod 需要通过该检查后才能对外提供服务
- startupProbe
- 在初始化阶段(Ready之前)进行的健康检查,通常用来避免过于频繁的监测影响应用启动
- 有些 Pod 启动比较慢,频繁的 readinessProbe 探针可能反而会影响到该 Pod 的启动
探测方法包括
- ExecAction:在容器内部运行指定命令,当返回码为0时,探测结果为成功
- TCPSocketAction:由kubelet发起,通过TCP协议检查容器IP和端口,当端口可达时,探测结果为成功
- HTTPGetAction:由 kubelet 发起,对 Pod 的 IP 和指定端口以及路径进行 HTTPGet 操作,当返回码为 200-400 之间时,探测结果为成功
小结:因为 livenessProbe 执行前,Pod 状态默认就是存活,因此需要配置 readinessProbe 来处理 livenessProbe 运行前这段时间的状态,保证用户流量达到时 Pod 一定是能提供服务的。
例如:
livenessProbe 设置为启动后 10s 才执行。
当时 Pod 两秒就启动完成了,剩下这 8 秒就直接以 Ready 状态对外提供服务了。如果此时 Pod 不能正常对外提供服务,这部分请求就会失败。
因此需要设置 readinessProbe,在 readinessProbe 检测通过之前 Pod 都不能对外提供服务。
为了解决上述问题,可以添加 readinessProbe,并且最好在两秒后就开始检测,这样可以让 Pod 能尽快的对外提供服务。readinessProbe 通过后就可以对外提供服务了,然后后续运行过程中可能因为某些 情况又会出现异常,这时就需要 livenessProbe 在检测了,当 livenessProbe 检测到不正常时就会 kill 掉容器进程,如果配置了 正确的 restartPolicy 那么 kubelet 就会重启该 Pod。
探针属性
| 参数 | 描述 | 默认值 |
|---|---|---|
| initialDelaySecons | Pod 启动后延迟探测的时间 | Defaults to 0 seconds. Minimum value is 0. |
| periodSeconds | 探测频率 | Default to 10 seconds. Minimum value is 1. |
| timeoutSeconds | 每次探测超时时间 | Defaults to 1 second. Minimum value is 1. |
| success Threshold | 成功阈值,连续成功多少次就算成功 | Defaults to 1. Must be 1 for liveness. Minimum value is 1. |
| failure' Threshold | 失败阈值,连续失败多少次就算失败 | Defaults to 3. Minimum value is 1. |
ReadinessGates
- Readiness 允许在 Kubernetes 自带的 Pod Conditions 之外引入自定义的就绪条件
- 新引入的readinessGates condition 需要为 True 状态后,加上内置的 Conditions, Pod 才可以为就绪状态
- 该状态应该由某控制器修改
ReadinessGates 是一个 hook,主要用于进行扩展。
场景:某个 Pod 是否 Ready,除了由 k8s 内部的探针控制之外,可能还需要由某些 k8s 外部 controller 来控制。
apiVersion: v1
kind: Pod
metadata:
labels:
app: readiness-gate
name: readiness-gate
spec:
# 配置该属性,指定一个类型即可
readinessGates:
- conditionType: "www.example.com/feature-1" containers:
- name: readiness-gate
image: nginx
---
apiVersion: v1
kind: Service
metadata:
name: readiness-gate
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: readiness-gate
该 Pod 运行后就会由于 readinessGates Not Ready 导致整个 Pod 进入Not Ready 的状态,直到外部控制器修改了 readinessGates condition 的值为 True。
Post-start和Pre-Stop Hook
在启动后或者停止前可以执行自定义 hook:
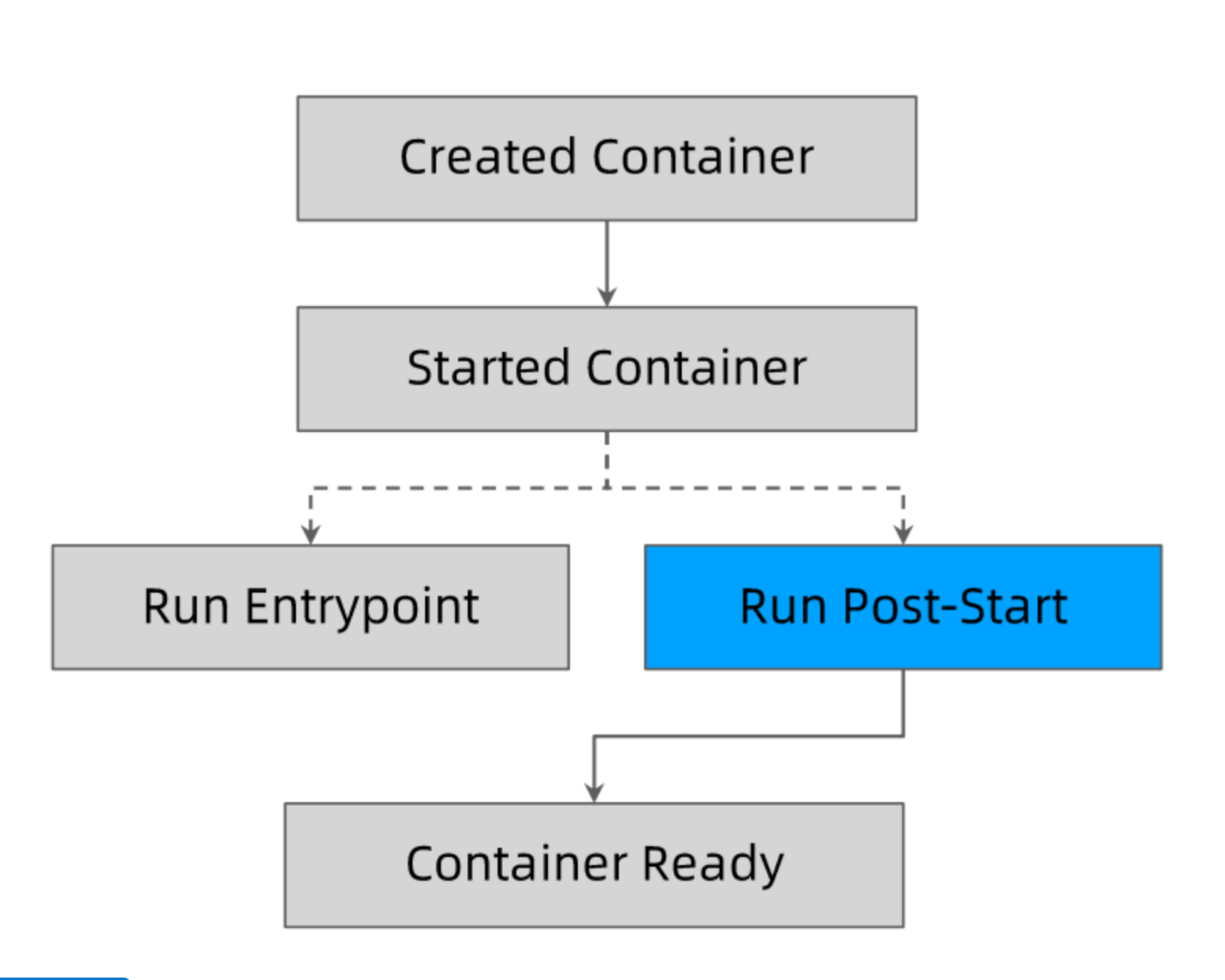
注意点:
- 无法保证 postStart 脚本的容器的 Entrypoint 哪个先执行
- postStart 结束之前,容器不会被标记为 Running 状态
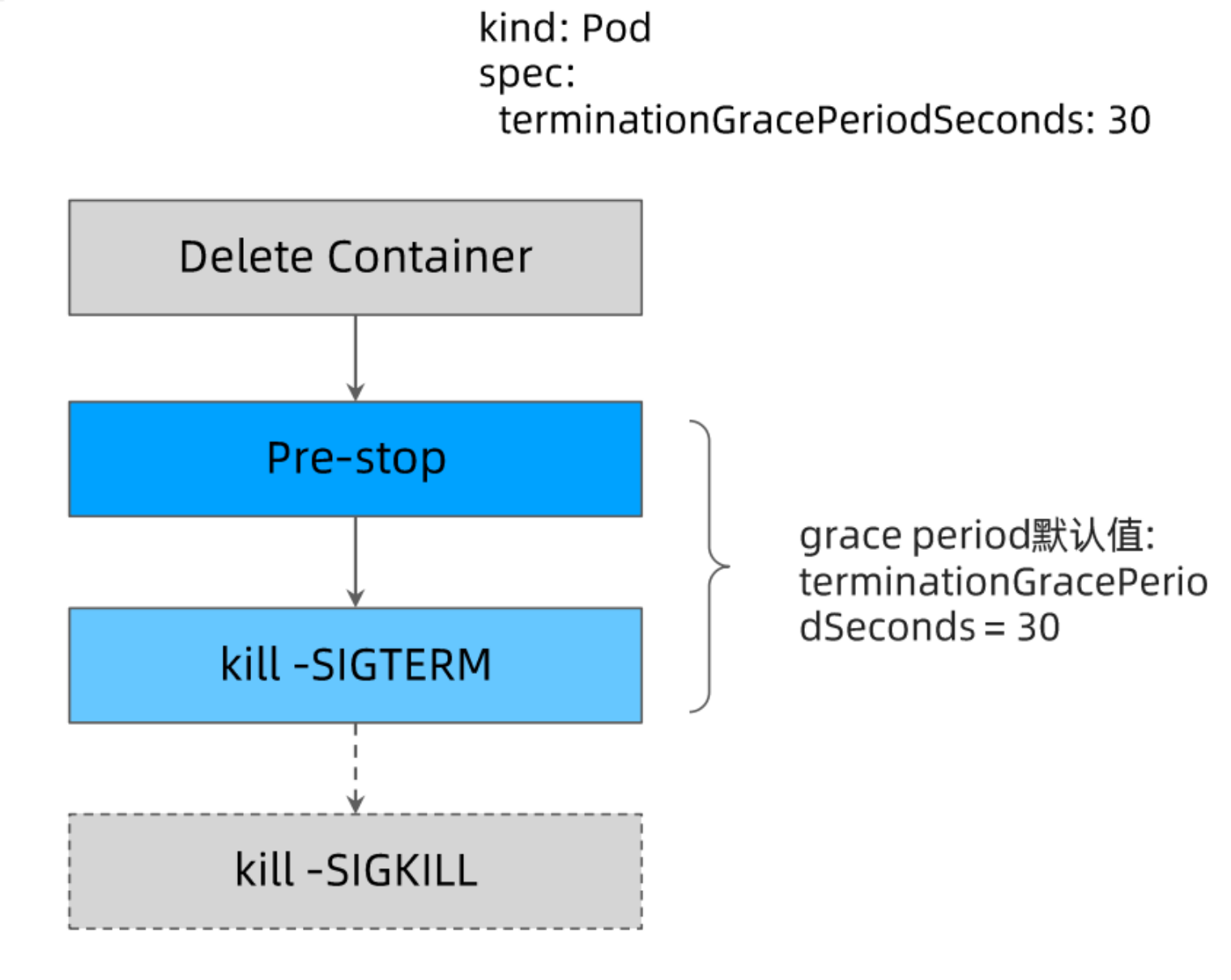
注意事项:
- 容器有一个terminationGracePeriodSeconds 时间,默认为 30 秒,如果超过这个时间会被强制 kill
- 一般用于做服务的优化退出,比如 http 服务可以再这段时间把已经进来的请求处理完再退出
- 只有当 Pod 被终止时,Kubernetes 才会执行 preStop 脚本,这意味着当 Pod 完成或容器退出时,preStop 脚本不会被执行。
apiVersion: v1
kind: Pod
metadata:
name: prestop
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
preStop:
exec:
command: [ "/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done" ]
terminationGracePeriodSeconds 的分解
terminationGracePeriodSeconds 定义了 Pod 退出到强制 kill 中间的间隔时间。
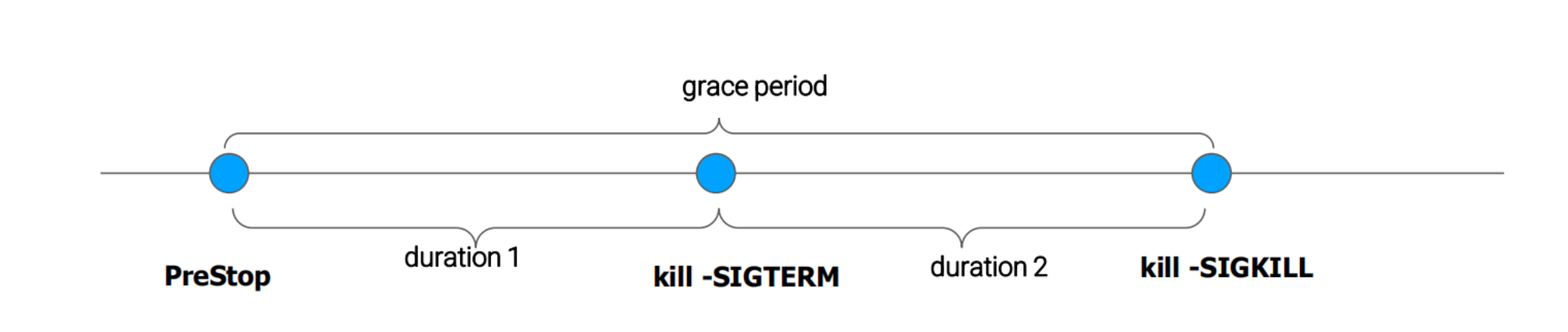
长连接场景下对 terminationGracePeriodSeconds 依赖比较大,比如一个视频会议的服务,一个视频会议可能一开就是几个小时,甚至更长时间都有可能,这种情况下业务如何做滚动升级呢?
一升级就会把现有连接 kill 掉,用户体验就很糟糕。
这种情况下就可以把 terminationGracePeriodSeconds 设置非常长时间,比如设置个 1天,然后业务里实现优化关机逻辑,等所有连接处理完成后程序再退出。
Terminating Pod的误用
bash/sh 会忽略 SIGTERM 信号量,因此 kill -SIGTERM 会永远超时,若应用使用 bash/sh 作为 Entrypoint, 则应避免过长的 grace period。
根据上图可知,如果 Pod 忽略 SIGTERM 信号量,那么就会一直阻塞在 kill -SIGTERM 这一步,直到整个 grace period 时间耗尽才触发 kill -SIGKILL。
Terminating Pod的经验分享
terminationGracePeriodSeconds默认时长30秒
- 如果不关心 Pod 的终止时长,那么无需采取特殊措施
- 如果希望快速终止应用进程,那么可采取如下方案
- 在 preStop script 中主动退出进程.
- 在主容器进程中使用特定的初始化进程
- https://github.com/krallin/tini
- 优雅的初始化进程应该
- 正确处理系统信号量,将信号量转发给子进程
- 在主进程退出之前,需要先等待并确保所有子进程退出
- 监控并清理孤儿子进程
在 k8s 上部署应用的挑战
资源规划
- 每个实例需要多少计算资源
- CPU/GPU?
- Memory
- 超售需求
- 每个实例需要多少存储资源
- 大小
- 本地还是网盘
- 读写性能
- Disk IO
- 网络需求
- 整个应用总体QPS和带宽
存储带来的挑战
多容器之间共享存储,最简方案是 emptyDir
带来的挑战:
- emptyDir 需要控制 size limt,否则无限扩张的应用会撑爆主机磁盘导致主机不可用,进而导致大规模集群故障
- emptyDir size limit 生效以后, kubelet 会定期对容器目录执行读操作,会导致些许的性能影响.
- size limit 达到以后,Pod 会被驱逐,原 Pod 的日志配置等信息会消失
应用配置
传入方式
- Environment Variables
- Volume Mount
数据来源
- ConfigMap
- Secret
- Downward API
数据应该如何保存
| 存储卷类型 | 容器重启后是否存在 | Pod 重建后数据是否存在 | 是否有大小控制 | 注意事项 |
|---|---|---|---|---|
| emptyDir | 是 | 否 | 是 | |
| hostPath | 是 | 否 | 否 | 需要额外权限控制 |
| Local Volume | 是 | 否 | 是 | 无备份 |
| Network Volume | 是 | 是 | 是 | |
| rootFS | 否 | 否 | 否 | 不要写任何数据 |
注意控制日志写入速度,防止操作系统在配置日志滚动窗口期把硬盘写满。
容器应用可能面临的进程中断
| 类型 | 影响 | 建议 | 备注 |
|---|---|---|---|
| kubelet 升级 | 不重建容器 | 无影响 | |
| kubelet 升级(某几个版本) | 重建容器Pod 进程会被重启 | 冗余部署跨故障域部署 | kubelet 如何判断 Pod 是否启动?计算 hash 值,和 etcd 中的 Pod 进行对比,如果不一致则认为没有启动,会重新拉取 Pod。而有几个版本 k8s 中对计算 hash 值的方法进行了修改,因此升级到该版本后 kubelet 会认为 Pod 没有被启动,又重新创建 Pod,对业务影响比较大 |
| 主机操作系统升级手工节点重启 | 节点重启Pod 进程会被终止数分钟(10分钟左右) | 跨故障域部署增加 liveiness、readiness 探针设置合理的 NotReady node 的 toleration | |
| 节点下架,送修 | 节点会 drain,重启或从集群中删除Pod 进程会被终止数分钟 | 跨故障域部署利用 Pod disruption budget 避免节点被 drain 导致 Pod 被意外删除而影响业务利用 preStop script 做数据备份等操作 | 因此升级 k8s 版本之前需要认真查看每个版本的 changelog。比如Pod有3副本,结果该节点上就有两个,一下子 drain 掉两个 2/3 副本数可能会业务就会有比较大的影响 |
| pod will | 跨故障域部署设置合理的 NotReady node 的 toleration | ||
| 节点崩溃 | Pod 进程会被终止 15 分钟左右 | 跨故障域部署 |
高可用部署方式
多少实例
更新策略
- maxSurge
- maxUnavalibale(需要考虑 ResourceQuota 的限制)
- 比如当前 Pod 副本数已经把 ResourceQuota 占满了,然后 maxUnavalibale 还配置为 0,滚动更新时势必要启动新 Pod,然后又会被 ResourceQuota 卡住,导致一致无法更新
深入理解 PodTemplateHash 导致的应用的易变性
课后作业
现在你对 Kubernetes 的控制面板的工作机制是否有了深入的了解呢?
是否对如何构建一个优雅的云上应用有了深刻的认识,那么接下来用最近学过的知识把你之前编写的 http 以优雅的方式部署起来吧,你可能需要审视之前代码是否能满足优雅上云的需求。
作业要求:编写 Kubernetes 部署脚本将 httpserver 部署到 kubernetes 集群,以下是你可以思考的维度:
- 优雅启动
- 优雅终止
- 资源需求和 QoS 保证
- 探活
- 日常运维需求,日志等级
- 配置和代码分离
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©