分布式存储之hash取余算法
[toc]
cluster(集群)模式-docker版哈希槽分区进行亿级数据存储
1~2亿条甚至更多数据需要缓存,请问如何设计这个存储案例
使用普通关系型数据库百分百不可能实现,肯定是分布式存储,用redis如何落地?或者是mongoDB
1. hash取余分区
2亿条记录就是2亿条k,v,我们单机不行就必须要分布式多机,假如有3台机器构成一个集群,用户每次读写操作都是根据公式,hash(key)%N个机器台数,计算出hash值,用来决定数据映射到哪个节点上。
- 缺点:简单粗暴,起到负载均衡和分而治之
- 缺点:某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重启洗牌
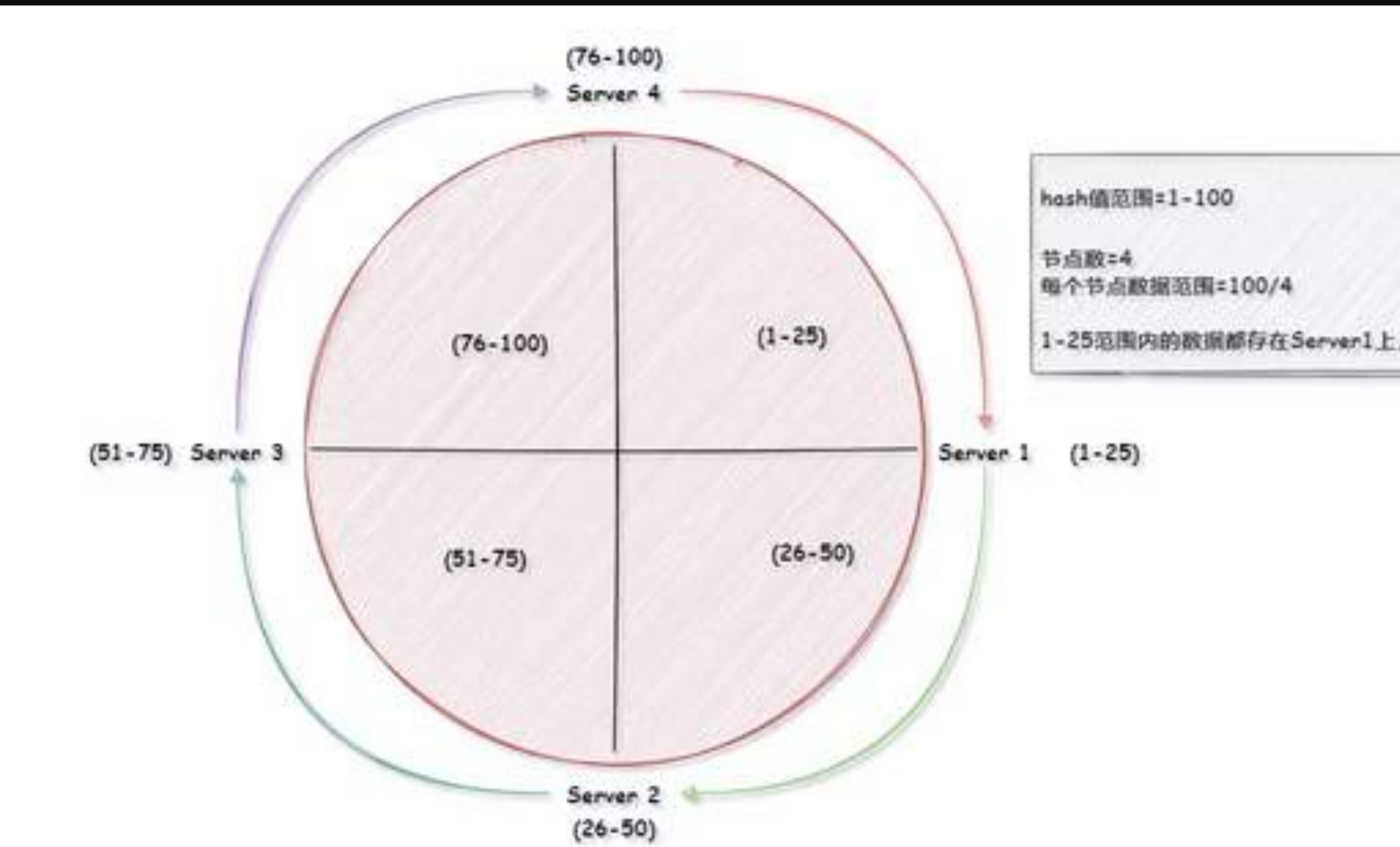
2. 一致性hash算法分区
目的就是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数就不ok了
步骤:
- 算法构建一致性哈希环
- hash函数产生hash值,所有hash值构成一个全量集,这个集合可以成为hash空间
- 一致性hash算法就是将整个hash空间组织成一个虚拟的圆环
- 将各个服务器使用hash进行一次hash,具体可以选择服务器的IP或者主机名作为关键字映射
- 服务器IP结点映射
- key落到服务器的落键规则
优点
- 一致性hash算法的容错性
- 一致性hash算法的扩展性
缺点
- 一致性hash算法的数据倾斜问题
当结点太少非常容易导致结点分布不均匀
3. 哈希槽分区算法
这个是大厂非常常见的算法,解决了数据倾斜问题
哈希槽实质就是一个数组,数据[0,2^14-1]形成hash slot空间
redis cluster使用的是hash slot算法,有固定的16384个hash slot,slot是槽的概念,有点类似memcached的slot,就理解为数据管理和迁移的基本单位吧。
redis cluster算是真正服务端的分布式缓存系统,不像memcached和2.0的redis需要在客户端进行负载均衡。
算法:
对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot。
数据分区
Redis Cluster 采用虚拟槽分区,所有的键根据哈希函数映射到 0~16383 (redis默认是16384个槽)整数槽内,计算公式:slot = CRC16(key)& 16384。每个节点负责维护一部分槽以及槽所映射的键值数据,如图所示:
redis集群并没有使用一致性hash而是引入了哈希槽的概念,redis集群有16384个hash槽,每个key通过CRC16校验后对16384取模来决定放哪个槽,集群中每一个结点负责一部分槽,但为什么hash槽的数量是16384呢?
CRC16产生65535位

举个例子
 当前集群有 5 个节点,每个节点平均大约负责 3276 个槽。由于采用高质量的哈希算法,每个槽所映射的数据通常比较均匀,将数据平均划分到 5 个节点进行数据分区。Redis Cluster 就是采用虚拟槽分区。
当前集群有 5 个节点,每个节点平均大约负责 3276 个槽。由于采用高质量的哈希算法,每个槽所映射的数据通常比较均匀,将数据平均划分到 5 个节点进行数据分区。Redis Cluster 就是采用虚拟槽分区。
节点1: 包含 0 到 3276 号哈希槽。
节点2:包含 3277 到 6553 号哈希槽。
节点3:包含 6554 到 9830 号哈希槽。
节点4:包含 9831 到 13107 号哈希槽。
节点5:包含 13108 到 16383 号哈希槽。
所以hash slot的好处是可以像磁盘分区一样自由分配槽位,在配置文件里可以指定,也可以让redis自己选择分配,结果均匀。
这种结构很容易添加或者删除节点。如果增加一个节点 6,就需要从节点 1 ~ 5 获得部分槽分配到节点 6 上。如果想移除节点 1,需要将节点 1 中的槽移到节点 2 ~ 5 上,然后将没有任何槽的节点 1 从集群中移除即可。
由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
缓存的key hash结果是和slot绑定的,而不是和服务器节点绑定,所以节点的更替只需要迁移slot即可平滑过渡。
但是redis分片技术也有功能限制:
笔者遇到过的一些限制主要就是以下几点:
1.对于pipeline批量操作,只能路由到一个片区,压力相对大
2.hmset() map结构也是只能路由到一个片区,是根据大key进行hash,即使有很多个field。
3.事务,不同片区无法在同一个事务中